3.1 来自海豚的告白
3.2 单节点数据库
3.3 一主一从架构
3.4 Master/Slave 复制原理及方式
3.5 一主多从架构
3.6 双主多从架构
3.7 Mysql Sharding
3.8 小张讲解
3.9 课后作业
3.1 来自海豚的告白
"我是一只海豚,我很孤独,我遨游在我的世界里,有很多人喜欢我,也有很多人厌恶我,可是,我还是我。"
这是一只Mysql 海豚的独白。

他是那么的清高,那么的傲慢,好像动物世界里的一朵奇葩,正是因为他的轻盈、他的开放,即使他这样傲慢无理,
还是有很多粉丝的追捧。
几乎大部分的互联网公司都会选用Mysql做为数据库,体现在它的扩展性,mysql 可以架构出一个分布式集群,
相对于oracle 这种大型数据库来说,他显得灵活,轻盈,而且他还是开源免费的。
为什么mysql 在互联网公司那么受到青睐, 因为互联网公司相对于传统企业来说,他的数据量增长的很快,单点数据库
已经无法满足数据的实时查询和存储的要求了,所以需要扩展数据库架构。
Mysql数据库架构的演化分为几个阶段:
单节点数据库

一主一从架构

一主多从架构
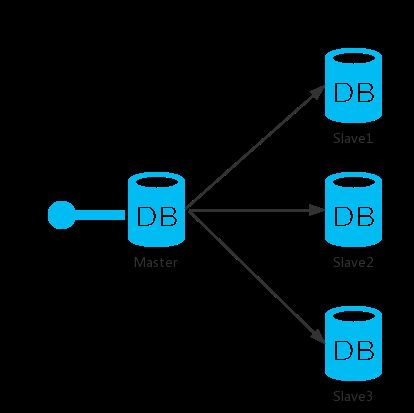
双主多从架构
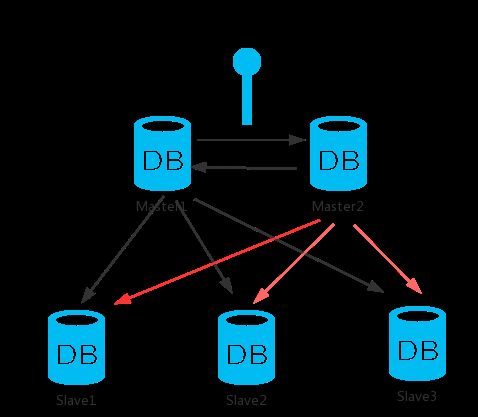
对比上面的架构图,来具体看看这几种架构的区别。
3.2 单节点数据库
大部分的童鞋接触到的都是这种单节点的数据库架构,
一个JAVA程序使用数据库连接池操作一个数据库,这个是不是很熟悉,就是J2EE的典型应用。
上点代码看看,更熟悉一点

架构上面来说就是 一个应用连接一个数据库 ,十分简单,也就不多说了,如下图:

3.3 一主一从架构
随着互联网访问量的迅速增加、以及数据量的增大,单点数据库会出现延迟,假死,更严重的出现崩溃的情况,在用户端看到的现象会是这样的

这种情况下,数据库已经负担不起这么大的压力了,海豚自恃清高也没用,于是有人想出用两个海豚来解决这个问题,最简单的就是这种一主一从的架构
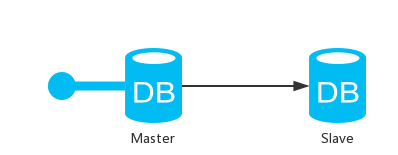
为什么要这样子来架构呢?
这样我们先来分析一下 造成系统性能的瓶颈在哪里
从硬件计算机系统来说 , 系统的性能主要取决于
CPU, 内存, 磁盘I/O, 网络I/O




再仔细分析
内存的 读写速度 是 24165M/s
机械硬盘的读写速度 在100M/s
网络带宽一般机房可以到 千兆带宽
很明显我们可以看出, 硬盘的读写速度跟内存 相差200多倍
很容易找出,我们系统的瓶颈在硬盘读写这一块,当然这里只是简单的推理
也有一些专业的工具对其进行测试
现在我们有两个方法来解决这个问题:
1. 提高硬盘的读写速度,让其达到内存的速度
2. 分摊压力,把硬盘读写的压力分摊到不同的节点上面
第一个方法那是硬盘厂商的事情了,我们控制不了,当然现在市面上也有读写快的,例如固态硬盘可以选配
我们要说的就是如何用现有的硬件来解决问题,也就是第二种方法。
我们再来分析业务:
数据库的操作 insert , delete ,update ,select
在正式的生产环境中,我们会发现,对比insert 写的操作,用户更多的在 select 查询上面的操作.
例如: 我们经常浏览新闻、逛淘宝,还在看我写的这篇文章,这些都是在 进行 读查询.

那么我们一主一从的架构 就是 让应用从 2个节点上面读取, 来进行分摊压力,
而这种从两个节点上面读取的策略 可以 通过 负载均衡来实现,意思就是说 如果有10个请求过来
把5个读的请求转发到 A 节点, 另外5个转发到B节点上面。
那么这个一主一从是如何实现的呢?
可以通过 MySQL replication 复制的方式来做
选定一个节点的MySQL作为 master
另外一个节点的MySQL作为 slave
插入更新数据 我们通过 master 完成 ,
master 会通过 replication 的方式来完成 对 slave 的同步更新.
这时 slave 就会有相同的数据, 应用就可以通过 从 slave 读取数据 来减轻 master 的压力.
3.4 Master/Slave 复制原理及方式
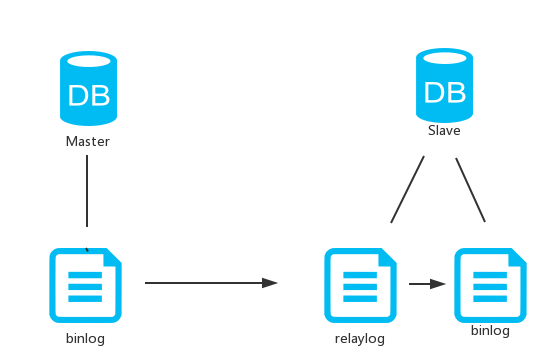
1. Master 所有的数据更新会记录到 日志 binlog 中,Master A 把binlog日志传给 Slave B
2. B 先把 A 的binlog日志 放到 称为 relaylog 中继日志的 地方
3. 最后 B 通过relaylog 日志中的内容对自己的binlog 进行更新,复制数据。
从这种机制上我们可以看出,可以保证A 和 B 的数据一致,但是同步或许会有延时(不考虑网络因素)
A 的执行可以并发执行, 等A 的 binlog 日志写 到 B 的 relaylog ,然后 B 从relaylog 读取复制到binlog
这个过程中会发生延时.
于是出现了
同步复制 的方式 :
同步复制 是 用户在前端访问,Master收到 insert 请求,这个时候 需要 等待 slave 复制完成后确认,
才能返回结果给用户,
显然这种方式不可取,因为会造成用户请求变的很慢的情况。
而这种方式也不是 MySQL的默认方式。
异步复制:
Master 只要完成自己的数据更新就返回结果给 用户,
而同步在异步状态下进行。 MySQL 默认设置。
半同步复制:
即是 如果slave 有很多个 , 也是后面讲的 一主多从的 架构下, master只要保证 其中一个slave 同步复制成功,
就返回结果给用户端。
3.5 一主多从架构
一主一从 是 一主多从 架构中的特例, 一主一从学会了,很容易理解 一主多从的架构了
在Mysql 的配置上面区别不大,后面实战进行架构的搭建会讲到。
这里就不衍生开了。
3.6 双主多从架构
为什么会有双主多从架构出现呢,肯定是为了解决某种问题而产生的。
是的,当我们用了一主多从架构以后,我们会发现一个致命的问题, 当我有5个节点,
肯定是 1个Master ,另外4 个是 slave , 这个时候 master 就相当于是中心领导的地位,
他这么重要,如果master 崩掉了怎么办,整个系统就不能正常运行了,
这个时候采用 双主多从,来用副领导保证。
就像master1 是一个总经理, 如果总经理不舒服或者有事走开了
这个时候就由 master2 副总 来接替他的工作。
3.7 Mysql Sharding
master-slave 这种架构,不管是 一主多从 还是 双主多从,我们发现他的性能瓶颈是在
master 上面,整个系统也并不是可以通过增加master 来达到性能的倍数增长的。
slave 越多,master 复制到 slave 的 日志越多,master 的负担就越重,同步的延时就越大
会出现读取到脏数据,以及数据不一致的问题。
问题出现了,新的架构也随之而来。
一种分表分库的分布式架构就出现了。
简单来讲,分表分库 不是 在master 和 slave 之间进行数据复制 以减轻 读的压力。
而是把数据内容进行切分,分别放到不同的节点上 。
例如 : 现在有10个用户的数据
master-slave 的做法是 复制10个用户的数据到 slave 下面去,这个时候整个系统就有10 * N个slave的数据量了。
而 分表分库则是 其中5个用户数据放到 A 节点上 , 另外5个用户数据放到B节点上,整个系统数据还是10个数据量。
这里简单讲这些,详细的放到后面章节中来讲。
在分表分库我们用Mycat 中间件, 在每个节点的分库中 ,我们还可以采用Master-Slave 这种架构 作为 混合架构使用。
3.8 小张讲解
读写分离
通过MySQL replication 我们可以复制数据到不同的数据库中, 但是上面讲到读取需要从不同的节点中读取,
还要有策略作负载均衡,这个功能逻辑就需要应用来进行实现。(应用要连接不同的数据库节点,分离读写)
市面上有很多成熟的中间件可以实现 负载均衡、读写分离,例如:MySQL-Proxy ,
应用层可以像 刚开始那样代码不变,所有的 读写分离工作交给 MySQL-Proxy中间件来实现。
MySQL replication
下一节中 ,我们具体来动手来做一个一主一从这种架构,通过配置MySQL的 replication ,以及在应用层进行
负载均衡、读写分离的实现,用最轻的方式来进行性能的最大提升。
3.9 课后作业
1. 什么是一主一从?
2. 同步有哪几种方式?
3. 实验:
> 安装centos 7 操作系统
> 安装mysql5.7 数据库
> 进行一主一从的Mysql 数据库架构
> 应用层实现一个DEMO , 进行读写分离以及负载均衡