Wide & Deep Learning for Recommender Systems(Google&Facebook推荐)
1、背景
文章提出的Wide&Deep模型,旨在使得训练得到的模型能够同时获得记忆(memorization)和泛化(generization)能力:
- 记忆(体现准确性):即从历史数据中发现item或者特征之间的相关性;
- 泛化(体现新颖性):即相关性的传递,发现在历史数据中很少或者没有出现的新的特征组合。
2、Wide&Deep模型
2.1、模型结构
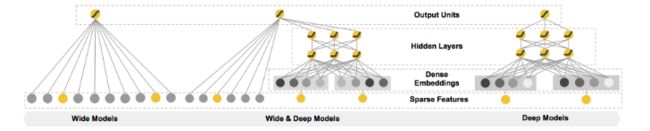
在Wide&Deep模型中包括两个部分,分别为Wide和Deep部分,Wide部分如上图中的左图所示,Deep部分如上图中的右图所示。
2.2、Wide模型
Memorization主要是学习特征的共性或者说相关性,产生的推荐是和已经有用户行为的物品直接相关的物品。
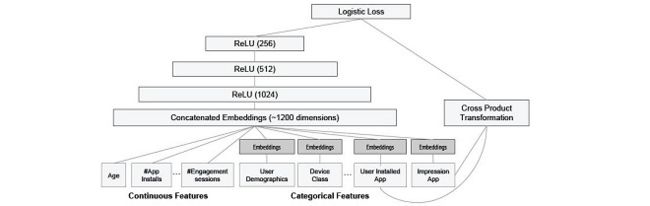
用的模型是逻辑回归(logistic regression, LR),LR 的优点就是简单(simple)、容易规模化(scalable)、可解释性强(interpretable)。LR 的特征往往是二值且稀疏的(binary and sparse),这里同样采用 one-hot 编码,如 “user_installed_app=netflix”,如果用户安装了 Netflix,这个特征的值为 1,否则为 0。
为了达到 Memorization,我们对稀疏的特征采取 cross-product transformation,比如说 AND(user_installed_app=netflix, impression_app=pandora”) 这个特征,只有 Netflix 和 Pandora 两个条件都达到了,值才为 1,这类 feature 解释了 co-occurrence 和 target label 之间的关系。一个 cross-product transformation 的局限在于,对于在训练集里没有出现过的 query-item pair,它不能进行泛化(Generalization)
Wide模型的输入是用户安装应用(installation)和为用户展示(impression)的应用间的向量积(叉乘),模型通常训练one-hot编码后的二值特征,这种操作不会归纳出训练集中未出现的特征对。
实际上,Wide模型是一个广义线性模型:,其中特征是一个d维特征向量,特征包括原始输入特征以及cross-product transformation特征。交叉积转换为
为布尔变量,若第i个特征是第k个变换的一部分,值为1,否则为0。为模型参数。最终在y的基础上增加Sigmoid函数作为最终的输出。
2.3、Deep模型
Generalization可以理解为相关性的传递(transitivity),会学习新的特征组合,来提高推荐物品的多样性,或者说提供泛化能力(Generalization)。
泛化往往是通过学习 low-dimensional dense embeddings 来探索过去从未或很少出现的新的特征组合来实现的,通常的 embedding-based model 有 Factorization Machines(FM) 和 Deep Neural Networks(DNN)。特殊兴趣或者小众爱好的用户,query-item matrix 非常稀疏,很难学习,然而 dense embedding 的方法还是可以得到对所有 query-item pair 非零的预测,这就会导致 over-generalize,推荐不怎么相关的物品。这点和 LR 正好互补,因为 LR 只能记住很少的特征组合。
为了达到 Generalization,文章引入新的小颗粒特征,如类别特征(安装了视频类应用,展示的是音乐类应用,等等)AND(user_installed_category=video, impression_category=music),这些高维稀疏的类别特征(如人口学特征和设备类别)映射为低纬稠密的向量后,与其他连续特征(用户年龄、应用安装数等)拼接在一起,输入 MLP 中,最后输入逻辑输出单元。
Deep模型是一个前馈神经网络。深度神经网络模型通过需要的输入是连续的稠密特征,对于稀疏、高维的类别特征,通常首先将其转换为低维的向量,这个过程也称为embedding。
在训练的时候首先随机初始化embedding向量,并在模型的训练过程中通过最小化损失函数来优化模型,逐渐修改该向量的值,即将向量作为参数参与模型的训练。
隐层的计算方法为:
其中,f为激活函数,如ReLus。
基于embedding的深度模型的输入是类别特征(生成embedding)+连续特征。
2.4、Wide&Deep模型联合训练
联合训练是指同时训练Wide模型和Deep模型,并将两个模型的输出算log odds ratio然后加权求和作为最终的预测结果:
联合训练和embedding方法是不同的。embedding把不同的部分分开训练,这个过程中不同的模型相互之间不知道彼此的存在,也不会互相影响。但在联合训练中,整个网络同时被训练,梯度的反向传播同时影响整个模型的所有部分,使用mini-batch SGD来训练模型。
训练方法:
- Wide模型:FTRL 各大公司广泛使用的在线学习算法FTRL详解
其中,式中第一项是对损失函数的贡献的一个估计,第二项是控制w(也就是model)在每次迭代中变化不要太大,第三项代表L1正则(获得稀疏解),表示学习速率。学习速率可以通过超参数自适应学习。,下角标表示第t次迭代,第i维特征,为超参数。
https://blog.csdn.net/a819825294/article/details/51227265
https://blog.csdn.net/fangqingan_java/article/details/51020653 - Deep模型:AdaGrad
在一般的梯度下降法中,对每一个参数的训练都使用了相同的学习率α。Adagrad算法能够在训练中自动的对学习率进行调整,对于出现频率较低参数采用较大的α更新;相反,对于出现频率较高的参数采用较小的α更新。因此,Adagrad非常适合处理稀疏数据。
http://www.cnblogs.com/xianhan/p/9347523.html
https://blog.csdn.net/u012759136/article/details/52302426
3、apps的推荐系统
将上述Wide&Deep模型应用在Google play的apps推荐中。
3.1、 推荐系统
推荐系统的一般结构如下所示:
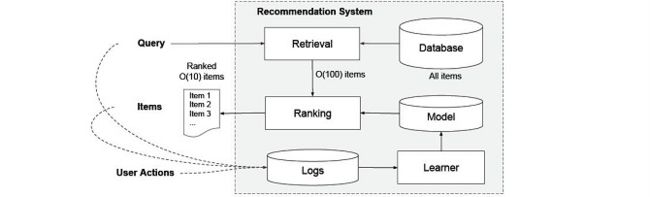
当一个用户访问App Store时,会产生一个请求,请求到达推荐系统后,推荐系统为该用户返回推荐的apps列表。
在实际的推荐系统中,通常将推荐的过程分为两个部分,检索系统(retrieval)和排序系统(ranking),retrieval从数据库中检索出与用户相关的最匹配query的一些apps,这里的检索通常会结合采用机器学习模型和人工定义规则两种方法。从大规模样本中召回最佳候选集后,ranking负责对这些检索出的apps打分、排序,最终按照分数的高低返回相应的列表给用户。分数P(y|x),y是用户采取的行动(例如下载),x是特征包括:
- user features:eg, country, language, demographics
- contextual features: eg, device, hour of the day, day of the week
- impression features: eg, app age, historical statistics of an app
WDL就是用在排序系统中。
3.2、apps推荐的特征
模型的训练之前,最重要的工作是训练数据的准备以及特征的选择,在apps推荐中,可使用到的数据包括用户数据和曝光数据,因此,每一条样本对应了一条曝光数据。样本点标签为1表示安装,0表示未安装。
对于类别特征,通过词典(vocabularies)将其映射成向量;对于连续的实值特征,将其归一化到区间[0,1]。
3.3、度量的标准
度量的指标有两个,分别针对在线的度量和离线的度量,在线时通过A/B test,最终利用安装率(acquisition);离线则使用AUC作为评价模型的指标。
4、代码介绍
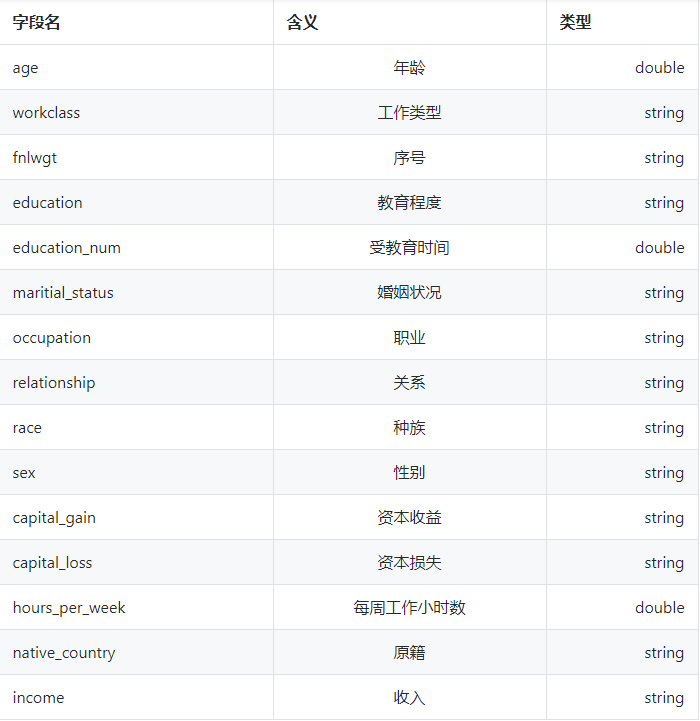
数据源:UCI开源数据集Adult
针对美国某区域的一次人口普查结果,共32561条数据,具体字段如下:
from __future__ import print_function
import tensorflow as tf
import tempfile
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
# Categorical base columns.构建低维离散特征
gender = tf.contrib.layers.sparse_column_with_keys(column_name="gender", keys=["Female", "Male"])
race = tf.contrib.layers.sparse_column_with_keys(column_name="race", keys=["Amer-Indian-Eskimo", "Asian-Pac-Islander", "Black", "Other", "White"])
education = tf.contrib.layers.sparse_column_with_hash_bucket("education", hash_bucket_size=1000)
relationship = tf.contrib.layers.sparse_column_with_hash_bucket("relationship", hash_bucket_size=100)
workclass = tf.contrib.layers.sparse_column_with_hash_bucket("workclass", hash_bucket_size=100)
occupation = tf.contrib.layers.sparse_column_with_hash_bucket("occupation", hash_bucket_size=1000)
native_country = tf.contrib.layers.sparse_column_with_hash_bucket("native_country", hash_bucket_size=1000)
# Continuous base columns.
age = tf.contrib.layers.real_valued_column("age")#构建连续型实数特征
age_buckets = tf.contrib.layers.bucketized_column(age, boundaries=[18, 25, 30, 35, 40, 45, 50, 55, 60, 65])
education_num = tf.contrib.layers.real_valued_column("education_num")
capital_gain = tf.contrib.layers.real_valued_column("capital_gain")
capital_loss = tf.contrib.layers.real_valued_column("capital_loss")
hours_per_week = tf.contrib.layers.real_valued_column("hours_per_week")
wide_columns = [
gender, native_country, education, occupation, workclass, relationship, age_buckets,
#构建离散组合特征
tf.contrib.layers.crossed_column([education, occupation], hash_bucket_size=int(1e4)),
tf.contrib.layers.crossed_column([native_country, occupation], hash_bucket_size=int(1e4)),
tf.contrib.layers.crossed_column([age_buckets, education, occupation], hash_bucket_size=int(1e6))]
deep_columns = [
#构建embedding特征
tf.contrib.layers.embedding_column(workclass, dimension=8),
tf.contrib.layers.embedding_column(education, dimension=8),
tf.contrib.layers.embedding_column(gender, dimension=8),
tf.contrib.layers.embedding_column(relationship, dimension=8),
tf.contrib.layers.embedding_column(native_country, dimension=8),
tf.contrib.layers.embedding_column(occupation, dimension=8),
age, education_num, capital_gain, capital_loss, hours_per_week]
model_dir = tempfile.mkdtemp()
'''
定义分类模型
n_classes// 分类数目,默认是二分类,>2进行多分类 ;weight_column_name // 训练实例的权重;
linear_optimizer = tf.train.FtrlOptimizer( ...) // 线性模型权重更新的optimizer;
dnn_optimizer=tf.train.AdagradOptimizer( ...) // DNN模型权重更新的optimizer
'''
m = tf.contrib.learn.DNNLinearCombinedClassifier(
model_dir=model_dir,#模型目录
linear_feature_columns=wide_columns,#输入线性模型的feature columns
dnn_feature_columns=deep_columns,#输入DNN模型的feature columns
dnn_hidden_units=[100, 50])#DNN模型隐层单元数
# Define the column names for the data sets.
COLUMNS = ["age", "workclass", "fnlwgt", "education", "education_num",
"marital_status", "occupation", "relationship", "race", "gender",
"capital_gain", "capital_loss", "hours_per_week", "native_country", "income_bracket"]
LABEL_COLUMN = 'label'
CATEGORICAL_COLUMNS = ["workclass", "education", "marital_status", "occupation",
"relationship", "race", "gender", "native_country"]
CONTINUOUS_COLUMNS = ["age", "education_num", "capital_gain", "capital_loss",
"hours_per_week"]
# Download the training and test data to temporary files.
# Alternatively, you can download them yourself and change train_file and
# test_file to your own paths.
#train_file = tempfile.NamedTemporaryFile()
#test_file = tempfile.NamedTemporaryFile()
#urllib.request.urlretrieve("http://mlr.cs.umass.edu/ml/machine-learning-databases/adult/adult.data", train_file.name)
#urllib.request.urlretrieve("http://mlr.cs.umass.edu/ml/machine-learning-databases/adult/adult.test", test_file.name)
# Read the training and test data sets into Pandas dataframe.
df_train = pd.read_csv('F:/method codes/adult.data.csv', names=COLUMNS, skipinitialspace=True)
df_test = pd.read_csv('F:/method codes/adult.test.csv', names=COLUMNS, skipinitialspace=True, skiprows=1)
df_train[LABEL_COLUMN] = (df_train['income_bracket'].apply(lambda x: '>50K' in x)).astype(int)
df_test[LABEL_COLUMN] = (df_test['income_bracket'].apply(lambda x: '>50K' in x)).astype(int)
def input_fn(df):#定义如何从输入的dataframe构建特征和标记:
# Creates a dictionary mapping from each continuous feature column name (k) to
# the values of that column stored in a constant Tensor.
'''
tf.constant构建constant tensor,df[k].values是对应feature column的值构成的list
'''
continuous_cols = {k: tf.constant(df[k].values)
for k in CONTINUOUS_COLUMNS}
# Creates a dictionary mapping from each categorical feature column name (k)
# to the values of that column stored in a tf.SparseTensor.
#tf.SparseTensor构建sparse tensor,SparseTensor由indices,values, dense_shape三个dense tensor构成,
#indices中记录非零元素在sparse tensor的位置,values是indices中每个位置的元素的值,dense_shape指定
#sparse tensor中每个维度的大小。
'''
以下代码为每个category column构建一个[df[k].size,1]的二维的SparseTensor。
'''
categorical_cols = {k: tf.SparseTensor(
indices=[[i, 0] for i in range(df[k].size)],
values=df[k].values,
dense_shape=[df[k].size, 1])
for k in CATEGORICAL_COLUMNS}
# Merges the two dictionaries into one.
'''
用以下示意图来表示以上代码构建的sparse tensor label是一个 constant tensor,记录每个实例的 label
'''
feature_cols = dict(list(continuous_cols.items()) + list(categorical_cols.items()))
# features是continuous_cols和categorical_cols的union构成的dict
# dict中每个entry的key是feature column的name,value是feature column值的tensor
# Converts the label column into a constant Tensor.
label = tf.constant(df[LABEL_COLUMN].values)
# Returns the feature columns and the label.
return feature_cols, label
def train_input_fn():
return input_fn(df_train)
def eval_input_fn():
return input_fn(df_test)
print('df_train shape:',np.array(df_train).shape)
print('df_test shape:',np.array(df_test).shape)
m.fit(input_fn=train_input_fn, steps=200)#训练模型
results = m.evaluate(input_fn=eval_input_fn, steps=1)#模型评测
for key in sorted(results):
print("%s: %s" % (key, results[key]))
#https://blog.csdn.net/a819825294/article/details/71080472
#https://www.sohu.com/a/190148302_115128
参考资料:https://www.jianshu.com/p/28a1849f6707
https://blog.csdn.net/google19890102/article/details/78171283