本文通过分析webpy代码学习python编程技巧、系统设计以及web编程的基本方法
我是边看代码代码边写此文的,所以代码中的有些问题可能会放在后序的文章中详细阐述。
webpy简单介绍
webpy是个使用python编写的轻量级web服务器
相关资料
webpy源码
webpy官网
测试用代码
# test_webpy.py
import web #指向源码中的web目录
urls = (
'/(.*)', 'hello'
)
app = web.application(urls, globals()) # 初始化
class hello:
def GET(self, name):
if not name:
name = 'World'
return 'Hello, ' + name + '!'
if __name__ == "__main__":
app.run() #启动
运行结果
服务端:

浏览器:

application类基本功能分析
在继续之前请了解wsgi相关概念,可以参考我的这篇文章。
1. 初始化步骤
即test_webpy.py第9行
app = web.application(urls, globals())
1. 参数urls用于存放用户请求与处理逻辑的关系(此处是hello类)
对于是否是iter的判断在py3helpers.py中有更完善的写法。

2. web.config
- 框架对web.config进行了初始化。我在application初始化以前将其内容print了出来,并将其初始化的地方分别列了出来。其中_is_dev_mode函数实现中有说到一个sys不存在argv成员的问题,有兴趣的同学可以看下注释中的连接。
- 其中debug配置项的具体功能有个描述,也体现了框架的一些功能:“ when True, enables reloading, disabled template caching and sets internal error to debug error”。我对reloading和template caching的实现还是比较感兴趣的,后续会详细研究下实现方法。
- Storage扩展了dict,增加了通过"."访问键值的功能。
3. handle_with_processors()与self.processor[]
其作用为在响应每个http请求前后做一些额外处理。此处先不关注processor具体是什么,只关注这些processor是如何注入的,你可以把这种方式作为一种设计模式来理解。(作者认为所有设计模式的目的只有一个:解耦)。
我在每个processor以及http请求处理函数中增加了一条日志,额外增加了一个unload test的processor,后面会提供代码。先来看看执行结果,注意执行顺序:

再来看看代码:
图注:
- 初始化
- self.processors[]用于存放所有的processor,其初始化与5个processor的添加都在__init__()中进行,其中我新加的那个已经在图中指出。
- loadhook()和unloadhook()为两个辅助函数,分别用于在处理Http前后增加processor。
- 注意代码执行顺序与之前的日志输出顺序做比较,尤其是新加的那个unload test的执行顺序。
为其中一个load processor的内容,参考用
loadhook()和unloadhook()
这两个辅助函数用于注册processor用。
- 其中processor函数的参数handler请理解为“下一步处理”或“下一步要做的事情”
- processor函数中的h即为实际的processor,而此处的processor函数则是对实际函数的包装
- unloadhook与loadhook主要的不同是只有unloadhook需要负责“传递”结果,因为用其注册的processor是在http请求完成处理以后执行的
- 如果http请求处理返回的结果形式为generator,则需要对其进行wrap(注意其中的wrap函数),以确保所有结果都遍历完毕以后才执行processor
4.实际执行processor的地方
- 方块里面是调用processor的代码。之前说过,每个processor函数接收的handler参数表示“下一步处理”,所以这里不能传processors(表示“剩余任务”)或者process(processors)(表示“剩余任务执行结果”)
- 倒数第二行的那个注释所指的是unloadhook添加与执行的顺序是相反的,具体请看我添加的那个unload test的代码执行与日志输出顺序与self._unload的进行比较
此设计模式总结:
- 适用性
- 要向外部提供接口,此处为向下层提供的handle_with_processors回调接口
- 任务有明确的第三方处理者,此处已封装为self.handle函数
- 要向两者之间增加额外的处理逻辑,即把自己作为第三方处理者的代理,对接口参数或处理结果透传或者再加工(本例子中并未再加工参数或结果,但是很容易实现)
- 代理逻辑可以无限拓展
2.伪代码
基础代码:
def 外部接口(请求参数):
return 第三方处理函数(请求参数)
应用该设计模式以后:
def 外部接口(请求参数):
预处理逻辑一(请求参数)
预处理逻辑二(请求参数)
...
结果 = 第三方处理函数(请求参数)
结果 = 再处理逻辑一(请求参数,上一步结果)
结果 = 再处理逻辑二(请求参数,上一步结果)
...
return 结果
3. mapping和fvars
此为__init()__的第二、第三个参数,其与webpy框架的使用方法有很大的关系。
先来修改下测试代码:
import web
class hello:
def __init__(self):
self.str = 'I am %s\n' % self.__class__.__name__
def GET(self, *args):
self.str += 'args len is %d(%s)' % (len(args), args)
return self.str
class hello2(hello):
pass
urls = (
'/hello', r'hello',
'/hello_cls', hello,
'/hello_arg/(\w*)', r'hello',
'/hello_arg/(\w*)/(\w*)', r'hello',
'/\w*', r'hello2',
'/1/(\w*)', r'\1',
'/2/(\w*)/(\w*)', r'\1',
'/3/(\w*)/(\w*)/(\w*)', r'\1\2',
'/4/hello_redi', r'redirect /2/hello/redi',
)
app = web.application(urls, globals())
if __name__ == "__main__":
app.run()
定义两个类hello和hello2(继承自hello),__init__的逻辑用来区分我是hello还是hello2,GET函数用来打印传进来的参数。
在urls中定义了更多的条目用来进行测试,其中条目是两两成对的,前者表示url请求,后者表示对应的处理方式。webpy会按顺序查找urls中的条目,如果找到则停止查找并进行处理。
接下来我们对每一对条目进行解释:
-
'/hello', r'hello',
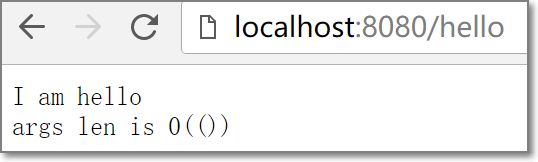 image.png
image.png
精确匹配,无任何参数传递
'/hello_cls', hello,
精确匹配,可以直接填写处理的类,即hello-
'/hello_arg/(\w*)', r'hello',
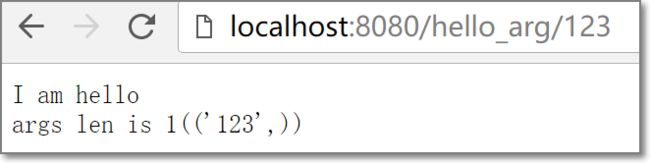 image.png
image.png
/hello_arg/用来对应到hello类,而括号中的内容将作为参数传递给处理逻辑
- '/hello_arg/(\w)/(\w)', r'hello',
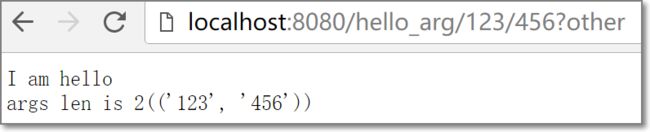 image.png
image.png
多个参数的情况,注意querystring不会作为参数传递
-
'/\w*', r'hello2',
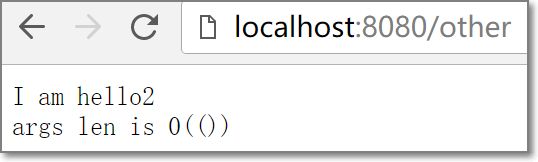 image.png
image.png
其他情况,由hello2处理
-
'/1/(\w*)', r'\1',
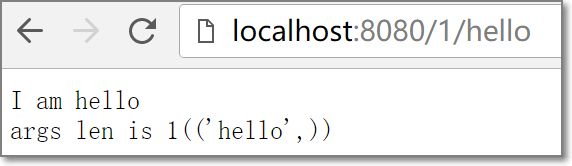 image.png
image.png
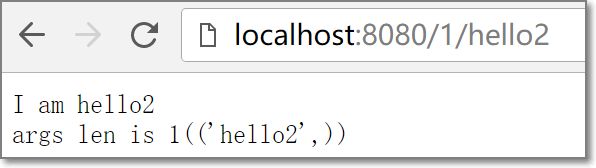
根据访问请求指定处理的类名,并且会作为参数传递
-
'/2/(\w)/(\w)', r'\1',
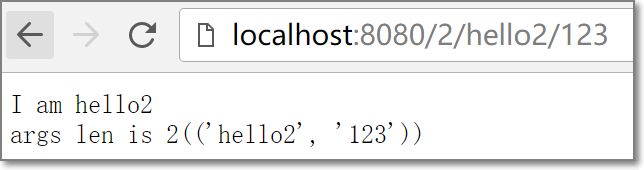 image.png
image.png
带额外参数的情况 -
'/3/(\w)/(\w)/(\w*)', r'\1\2',
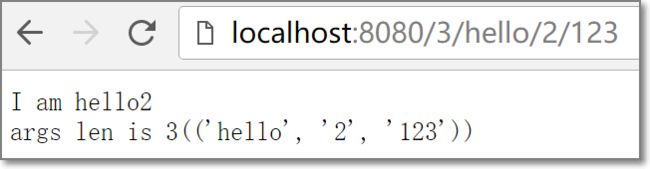 image.png
image.png
类名由多个参数组装而来 -
'/4/hello_redi', r'redirect /2/hello/redi',
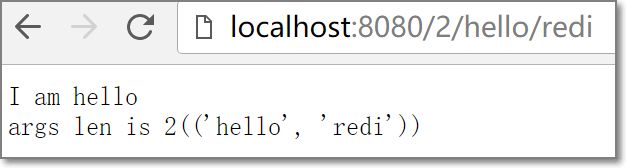 image.png
image.png
重定向,相当于访问了http://localhost/2/hello/redi,访问后url会有变化
接下来我们看看webpy代码的实现:
图注:
- 在初始化时传给application的第二个参数主要用于符号的查找。具体的使用看箭头的指向,fvars储存的就是globals(),从中可以找到hello类等符号
- mapping存放的就是对照表,也就是urls中的内容。在初始化的时候将其进行了两两分组
- 在之前讲到processor的时候,我们有提过handle(),它负责处理http请求。其中self._match()用于查找mapping,获得具体处理的对象(fn),以及URI相关信息(args);self._delegate()则负责执行处理逻辑
- re_subm的实现可以看一下其__doc__中的举例
- cls = fvars[f]这行代码在实际运行过程中可能会有问题,当cls不存在时后端会直接抛出异常在浏览器中看到500的错误
4. reload mod功能
__init__()最后一个参数表示是否开启reload的功能。reload功能指无需重启后端服务就可以修改http处理逻辑并使之生效。包括对照表urls和对应的处理逻辑(比如hello类)

图注:
- 通过注册两个processor,在每次响应http请求前进行mod是否更新的检查(Reloader)以及mapping与fvars的更新(reload_mapping)。注意, main模块是不能reload的,所以在__init__中将其作为一个非main模块重新import。相关的代码有一些问题,我做了一些调整,见图
- Reloader()检查所有mod的时间戳是否有变化,并reload有变化的mod。但是已经被引用的mod除非重新赋值引用其的变量,否则无法更新。个人认为从性能考虑,只用检查application对应的mod,其他的可以忽略。如果使用python3执行代码,需要将765的代码改成:
except Exception as e:
下一篇
webpy源码分析(二): application的run()