不管是哪个行业的人,或多或少都能感受到人工智能那越来越强劲的风力,而机器学习作为其中非常重要的一环,也都在进入每一个人的工作和生活。了解它,学习它,掌握它的想法也就很自然而然了,但是学习并且掌握机器学习到底有多难?让我们来做一个有趣的思维实验去感受一下,驾驭机器学习的难度。
首先,我介绍一下这个思维实验怎么做:我会挑选一篇机器学习技术的论文,然后假设读者是个彻头彻尾的小白,然后试图剖析这个技术需要了解的每一个知识细节,然后使用思维导图追踪和展示我们学习和思考的过程,最后呈现一幅完整的知识图谱,看看要读懂机器学习的论文有多难。那么让我们开始吧。
第0步,对于计算机了解的人都知道为什么我总是从0开始(数组的第一个索引值是0),对于这一点看过我《深度机器学习的能力模型》的应该还记得,我对于最基本能力的定义是第0级。回到正题,我们先降低一个语言的难度,我会选用一篇描述机器学习技术的中文论文来做剖析,但是实际上深入机器学习的人都知道,英文是跳不过坎,现在就算是非英语国家的人做机器学习也都在使用英文沟通和交流,特别是比较正式的技术文章发表。另外,哪怕是现在有机器语言翻译,对于诘屈聱牙的技术文章来说,翻译的质量也是很差的。为了强调这一点,我们假设有一个神奇翻译机器,在第0步把语言的差异问题解决了,因此后面的就不再语言和翻译上多言了。
第1步,我选择了这篇《基于极性转移和LSTM递归网络的情感分析》的论文,下面是这篇论文的摘要。阅读是学习的基本方式,我将会使用思维导图展开这段论文摘要。

第2步,我先用思维导图表达这篇论文的题目,导图显示如下:

再往下走,我就不标步数了,开始一层一层的解释。“极性转移”只是借用化学名词的说法,就是指文字细微的差别导致意思的完全改变,比如“不”,这个概念看似简单,但是包含了一门很重要的学问--语义学,也就是通过逻辑形式系统中符号的推演来研究语言。而语义学包含了语言学,逻辑学,认知科学,心理学等多个领域的交叉,我就不继续展开了,但是通过“中国队大败美国队”和“中国队大胜美国队”这样的例子,你也应该知道语义学需要面对的挑战,而极性转移更加是属于更深层次情感分析。到这里,我们的导图应该在一个局部盛开了花朵(如下图)。

如果说上面“极性转移”可以浮光掠影的对于语言和语义走了个过场(没有贬低文科的意思),接下来的部分就无法跳过任何一个概念,因为跳过就意味着再也过不去了。现在我们来看LSTM = Long Short-Term Memory(翻译成长短期记忆模型)。这个模型是1997年施密德哈珀博士和赛普发表的一篇论文,这篇论文在当时并没有引起广泛的理解,为什么?很简单啊,当时的IBM大型机都算不过来这么复杂的模型。但是,现在连手机都能拥有4G内存的今天,证明了这篇论文对于数据的学习效率得到极大的提升,因为它让神经网络和人类一样拥有循环和记忆的机制,不会每次从头学习。因此,为了理解这个模型,我们需要一系列的基础知识,包括神经网络模型,特别是递归神经网络的很多知识。我的习惯是不管多难的概念,千万别一上来就看简版,白话版,或者戏说版,因为建立第一印象很重要,所以我们直接看LSTM长什么样子(如下图)
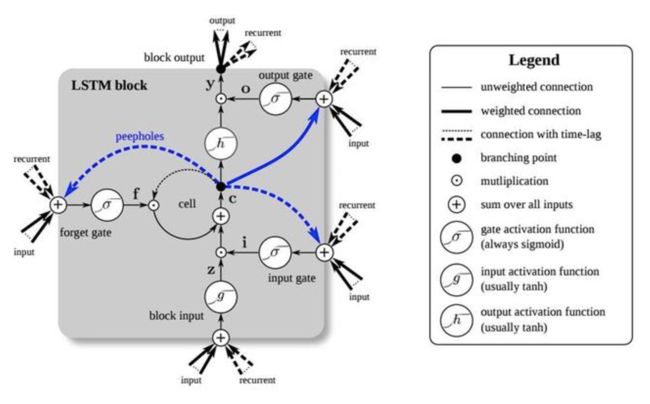
你知道我是从论文里抠出来的,也知道英文很重要了吧,不然看懂了图,看不懂字。我并不急于来解读这张图,因为我们还没有解释LSTM的基础,循环网络(RNN)是什么。还是看图,循环网络就是下面这个样子。怎么样,是不是更加有点蒙,不要紧,我们还没有讲神经网络的基本概念,所以这两张图会在神经网络的基本概念介绍之后回头来讲。
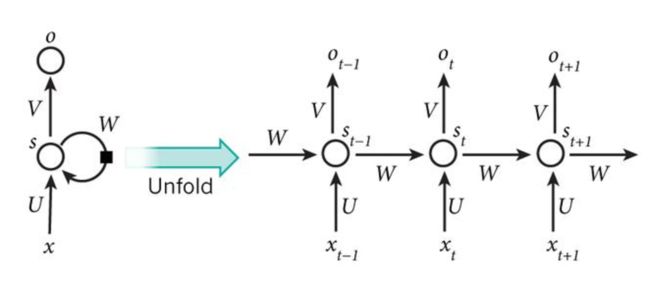
这里我想再次澄清一下,我这篇文章的目的并不是由浅到深介绍LSTM模型在文本情感分析上的机理和作用,我仅仅是拿它作为一个例子让大家感觉一下,机器学习,特别是主流的深度机器学习(经过大神背书的,详情见我的《深度机器学习的能力模型》)的掌握,会覆盖到哪些知识点。但是为了能够展开这个探索工作,我不得不顺着LSTM的道路往下走,并且时不时回头看一眼我们的思维导图,因为我们的目标就是生成一个完整的思维导图。现在它变成这个样子了(如下)

如果你没有耐心,请直接跳到最后去看那张最后版本的图,但是我建议如果你一次看不完,明天接着看。思维有时候就是在推导中变得清晰,信念在推导中得到坚定。这也是我为什么比较不愿意去读那些一上来就是密密麻麻一整张图,除了起到震撼你的作用,实际上你从中什么也得不到,比如下面这张40年认知架构图(我会以后单独写下面这张图的文章)。相反,一点一点的推演出来的东西就记得牢靠。
现在我们继续分解神经网络。我们这里的神经网络,准确来说叫“人工神经网络”,是一种模仿生物神经网络,特别是中枢神经系统的结构和功能的数学模型。所以让我们先看生物神经是个啥样子,同时再次强调英文重要性。(如下图)
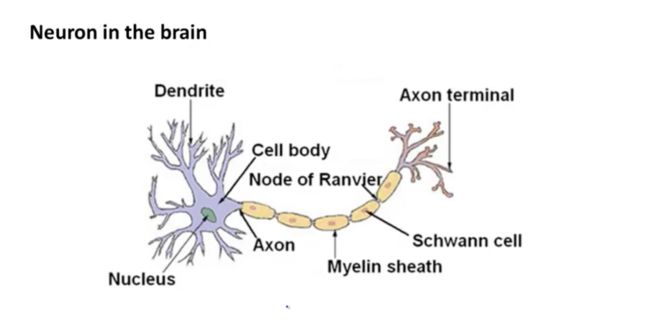
这是一个神经元的完整结构,不用看这么多组件,实际上给人工神经网络模型启发的是代表输入的“Dendrite”,代表处理单元的“Cell body”和代表输出和传递的“Axon”。因此,在数学上用数作为输入(实际工程应用,输入是向量,矩阵,张量),代表处理单元的部分有一点复杂,这个单元实际上包含了如何处理输入数据的权值矩阵和如何输出的激活函数,具体的样子参见下图:
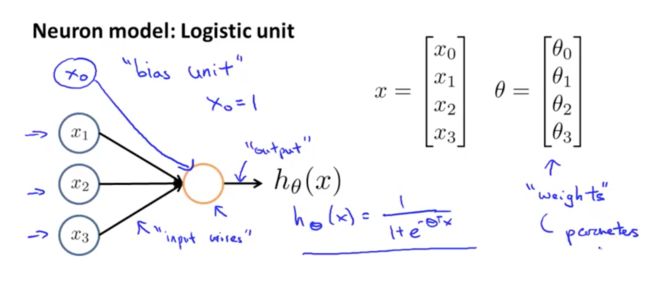
这张图是我在学习斯坦福大学机器学习在线课程时候的截屏。到现在为止,我一直没有给大家看公式,现在数学来了,我们看到输入的数是一个矩阵,这个神经单元的权值也是个矩阵,决定输出的计算是一个由输入向量和权值向量决定的函数。到这里,我们需要在此回到我们的导图,要在神经网络后面继续细分,为了能够建立和理解神经网络模型,我们需要具备的数学知识有哪些。首先,矩阵论是跑不掉的,你可以想象一下,基于矩阵的加减乘除,转置压缩等等;其次,看到了那个华丽的e没有,自然常数,一个比圆周率Pi还要神秘的数字,实际上它代表着一个无限靠近一个有限数的常量,这是个微积分学的概念,至此,我们的导图是这个样子:
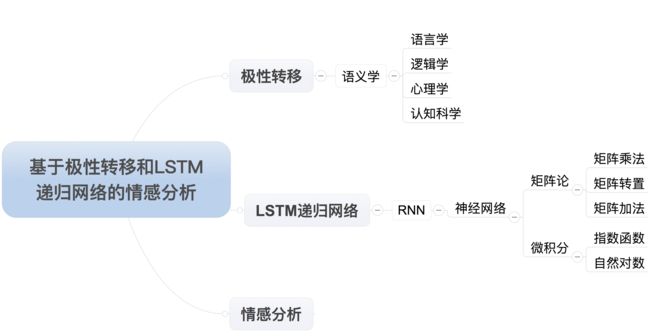
经过分析和鉴别,我们基本完成了这篇论文的题目解读,已经发现需要涉足的知识和领域如上图所示。我特定隐藏了要完成机器学习所需要的计算机知识,从计算机体系与架构,计算机数据结构,编程语言,数据库,操作系统,软件工程等等一系列知识,但是那并不意味着它们不存在,而且这些看上去牛皮哄哄的各路研究人员,面对商用软件设计和生产的时候,一样蒙圈,因为代码版本控制,单元测试,项目迭代,发布管理,集成测试,在线监控,运维等等一系列知识,在那个点都有可能搞死人。
洋洋洒洒写了一大篇,才解读完一个题目,要把这篇论文读完会有多长?以我的经验,任何事情第一次都是非常困难,坚持,坚持下来就好。大部分的人都死在坚持的半山腰,感觉很鸡汤。言归正传,我们来看摘要“长短时记忆(long short term memory,LSTM)是一种有效的链式循环神经网络(recurrent neural network,R2NN1),被广泛用于语言模型、机器翻译、语音识别等领域。但由于该网络结构还是一种链式结构,不能有效表征语言的结构层次信息,本文将LSTM扩展到基于树结构的递归神经网络(recursive neural network,RNN)上,用于捕获文本更深层次的语义语法信息,并根据句子前后词语间的关联性引入情感极性转移模型。实验证明本文提出的模型优于LSTM、递归神经网络等。”,这么一段话,我们一个词一个词的往导图里面增加,这么不解读了,直接看摘要阅读完成,覆盖的知识点有哪些:
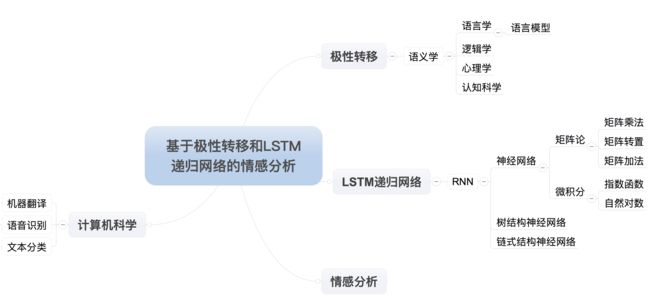
继续开始读正文了,我就不引述正文了,提纲挈领的描述一下它们研究的对象,过程和结果。首先,该论文回顾了利用机器学习做文本情感分析的历史,现状,面临的挑战,然后提出自己对于挑战的解决方案,并且编程实现了方案,并且和其它方案和过往方案做了横向对比,最后照例谦虚一下,谈谈不足和未来继续工作的方向。我按照这个逻辑结构开始丰富我们的导图。
回顾历史和论述现状的部分,论文就提到了文本情感分析的关键--文本建模,这就林林总总描述了一堆,让我们直接看导图(如下)。
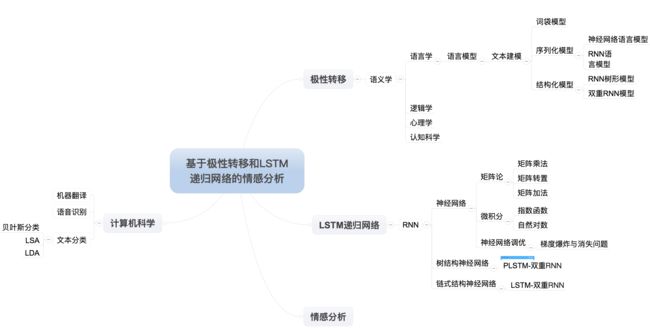
接近知识爆炸的时刻到了。我假设读者是一个彻头彻尾的小白,因此,我们需要根据导图上面每个叶结点逐个细化,目前是16个叶结点,我还是有耐心继续分解的。首先,我们来看贝叶斯分类。这是一类分类算法,皆以贝叶斯定理为基础,最有名的当属简单粗暴的朴素贝叶斯分类(所谓条件概率最大分类),类似的分类算法还有很多,我会在导图表示,但是这里需要重点提及贝叶斯网络。按照常识,我们粗暴假设分类属性是独立的,这个在现实中往往不存在,分类的属性都是相关的,因此采用贝叶斯网络(或者叫信念网络)解决这个问题。LSA=Latent Semantic Analysis是一种基于奇异矩阵分解SVD的文本分类算法,专门针对多义词造成分类准确度下降的问题。LDA=Linear discriminate analysis,主要是解决分类特征太多的问题。机器翻译和语音识别不在本文讨论范围,就不展开了。接着,我来看词袋模型,这是一种比较简单的语言建模,它把语言拆成单词,然后统计单词的频率,按照频率高低排序得出所谓特征向量,然后特征匹配的时候直接比对这些特征向量,毫无疑问,这种做法速度很快,简单,分类还是可以说得过去,但是对于比较精细的分析就不行了。所以,更加灵活的神经网络语言模型出现了,为了了解递归神经网络语言模型,还是要先了解递归神经网络,而递归神经网络的了解则是要回到神经网络本身去了,是不是感觉我们想要拓展知识,但是又回到了文章开始的神经网络本身去了,为什么?下一部分再聊。