数据结构与算法--最短路径之Floyd算法
我们知道Dijkstra算法只能解决单源最短路径问题,且要求边上的权重都是非负的。有没有办法解决任意起点到任意顶点的最短路径问题呢?如果用Dijkstra算法,可以这样做:
Dijkstra[] all = new Dijkstra[graph.vertexNum()];
for (int i = 0; i < all.length; i++) {
all[i] = new Dijkstra(graph, i);
}
for (int s = 0; s < all.length; s++) {
for (int i = 0; i < graph.vertexNum(); i++) {
System.out.print(s + " to " + i + ": ");
System.out.print("(" + all[s].distTo(i) + ") ");
System.out.println(all[s].pathTo(i));
}
System.out.println();
}
其实就是有n个顶点,创建了n个实例对象,每个实例传入了不同的参数而已。我们想要一次性得到任意起点到任意顶点的最短路径集合,可以尝试Floyd算法。
解决多源最短路径的Floyd算法
首先,Floyd算法可以处理负权边,但是不能处理负权回路,也就是类似 a -> b -> c ->a,a -> b、b -> c、c -> a三条边的权值和为负数。因为只要我们一直围着这个环兜圈子,就能得到权值和任意小的路径!负权回路会使得最短路径的概念失去意义!
Floyd算法需要两个二维矩阵,因此使用邻接矩阵实现的有向加权图最为方便,不过我一直用邻接表实现的。为此需要将邻接表转换为相应的邻接矩阵。很简单,先将整个二维数组用0和正无穷填充,对角线上权值为0,其余位置正无穷。然后将邻接表中的元素覆盖原数组中对应位置的值,这样邻接表就转换为邻接矩阵了。邻接矩阵在代码中我们用dist[][]表示,这里面存放的就是任意顶点到其他顶点的最短路径!另外需要另外一个二维数组edge[][],像edge[v][w]存放的是v到w的路径中途经的某一个顶点(或叫中转点),具体来说edge[v][w]表示v -> w这条路径上到w的前一个顶点。v -> w途径的顶点可能有多个,都在v那一行即edge[v][i]里找。
算法的精华在下面几行:
if (dist[v][k] + dist[k][w] < dist[v][w]) {
dist[v][w] = dist[v][k] + dist[k][w];
edge[v][w] = edge[k][w];
}
其中k是v -> w路径中途径的某一个顶点,判断条件其实和Dijkstra的判断条件如出一辙,即:到底是原来v -> w的路径比较短;还是先由v经过k,再从k到w的这条路径更短,如果是后者,那么需要更新相关数据结构。Floyd依次把图中所有顶点都当做一次中转点,判断任意顶点经过该中转点后,路径会不会变得更短。
先放代码...
package Chap7;
import java.util.LinkedList;
import java.util.List;
public class Floyd {
private double[][] dist;
private int[][] edge;
public Floyd(EdgeWeightedDiGraph graph) {
dist = new double[graph.vertexNum()][graph.vertexNum()];
edge = new int[graph.vertexNum()][graph.vertexNum()];
// 将邻接表变成了邻接矩阵
for (int i = 0; i < dist.length; i++) {
for (int j = 0; j < dist.length; j++) {
// 赋值给
edge[i][j] = i;
if (i == j) {
dist[i][j] = 0.0;
} else {
dist[i][j] = Double.POSITIVE_INFINITY;
}
}
}
for (int v = 0; v < graph.vertexNum(); v++) {
for (DiEdge edge : graph.adj(v)) {
int w = edge.to();
dist[v][w] = edge.weight();
}
}
for (int k = 0; k < graph.vertexNum(); k++) {
for (int v = 0; v < dist.length; v++) {
for (int w = 0; w < dist.length; w++) {
if (dist[v][k] + dist[k][w] < dist[v][w]) {
dist[v][w] = dist[v][k] + dist[k][w];
edge[v][w] = edge[k][w];
}
}
}
}
}
public boolean hasPathTo(int s, int v) {
return dist[s][v] != Double.POSITIVE_INFINITY;
}
public Iterable pathTo(int s, int v) {
if (hasPathTo(s, v)) {
LinkedList path = new LinkedList<>();
for (int i = v; i != s; i = edge[s][i]) {
path.push(i);
}
// 起点要加入
path.push(s);
return path;
}
return null;
}
public double distTo(int s, int w) {
return dist[s][w];
}
public static void main(String[] args) {
List vertexInfo = List.of("v0", "v1", "v2", "v3", "v4", "v5", "v6", "v7");
int[][] edges = {{4, 5}, {5, 4}, {4, 7}, {5, 7}, {7, 5}, {5, 1}, {0, 4}, {0, 2},
{7, 3}, {1, 3}, {2, 7}, {6, 2}, {3, 6}, {6, 0}, {6, 4}};
double[] weight = {0.35, 0.35, 0.37, 0.28, 0.28, 0.32, 0.38, 0.26, 0.39, 0.29,
0.34, 0.40, 0.52, 0.58, 0.93};
EdgeWeightedDiGraph graph = new EdgeWeightedDiGraph<>(vertexInfo, edges, weight);
Floyd floyd = new Floyd(graph);
for (int s = 0; s < graph.vertexNum(); s++) {
for (int w = 0; w < graph.vertexNum(); w++) {
System.out.print(s + " to " + w + ": ");
System.out.print("(" + floyd.distTo(s, w) + ") ");
System.out.println(floyd.pathTo(s, w));
}
System.out.println();
}
}
}
关键的地方就是那三个嵌套for循环了,最外层k一定是中转点,第二层是路径的起点v, 第三层是路径的终点w, 它们是这样的关系 v -> k -> w。v -> w途中可能有多个顶点,k可能只是其中一个。k = 0时,对所有经过0的路径,都更新为当前的最短路径,注意是当前,也就是说是暂时的,随着最外层k的循环,dist[][]和edge[][]也会不断发生变化;当k = 1时需要用到刚k = 0更新后的dist[][]和edge[][]的状态,也就是说每一轮k的循环都是以上一轮为基础的,到最后一次循环结束,对于经过任意顶点的的所有路径都已是最短路径。可以看出这其实是一个动态规划(DP)问题。
关于路径的存放edge[][],有两句代码很关键
// 初始化中
edge[i][j] = i;
// if条件中
edge[v][w] = edge[k][w];
-
edge[v][w]存放的是v -> w路径中,终点w的前一个顶点。其实和深度优先和广度优先里用到的edgeTo[]差不多,这里的edge[][]对于任意一条v -> w的路径都是一个树形结构,从终点w开始不断往上找其父结点,最后到根结点(即起点v)处停止。 -
edge[i][j] = i;一开始初始化为起点i的值。意思是i -> j路径中到j的前一个顶点就是i。也就是说我们先假设不经过任何其他顶点的从v到w的直接路径是最短的。在之后的循环中,如果经过其他顶点的i -> j更短就更新;否则就保持默认值。我们将看到,这样初始化在edge[v][w] = edge[k][w]这句中也适用。
[0, 0, 0, 0, 0, 0, 0, 0]
[1, 1, 1, 1, 1, 1, 1, 1]
[2, 2, 2, 2, 2, 2, 2, 2]
[3, 3, 3, 3, 3, 3, 3, 3]
[4, 4, 4, 4, 4, 4, 4, 4]
[5, 5, 5, 5, 5, 5, 5, 5]
[6, 6, 6, 6, 6, 6, 6, 6]
[7, 7, 7, 7, 7, 7, 7, 7]
- 我们知道v -> k -> w的路径中,v -> k已经是最短路径了,所以只需要更新v -> w,从代码中也可以看出来,我们确实是只对
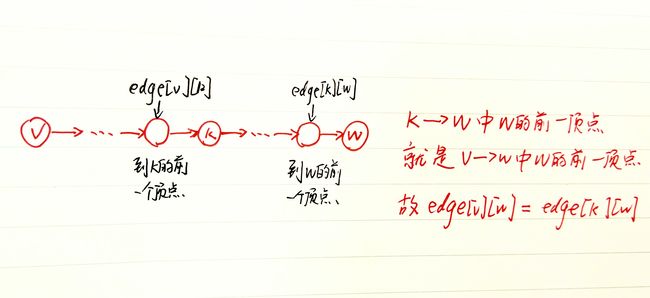
dist[v][w]和edge[v][w]操作。但为什么是edge[v][w] = edge[k][w]?现在v -> k -> w这条路径更短,k -> w中到w的前一个顶点也就是v -> w路径中到w的前一个顶点。结合edge[v][w]的定义:存放的是v -> w路径中,w的前一个顶点,可得到edge[v][w] = edge[k][w]。画个图加深理解。
下图是v -> w第一次更新时:k - > w中到w的前一个顶点应该是k,同时它也是v -> w路径中到w的前一个顶点。所以edge[k][w]应该为k。而事实确实是这样的!因为在初始化时候我们是这样做的edge[i][j] = i。
edge[v][w] = edge[k][w] = k,这里其实就是用了初始值而已。

再看下图,是若干次更新v -> w时,此时v -> k和k -> w路径中可能有多个顶点,但是edge[k][w]存的始终是终点w的前一个顶点。当v -> w的最短路径更新后,k -> w中到w的前一个顶点就是v -> w路径中到w的前一个顶点。
这就解释了edge[v][w] = edge[k][w]是怎么来的。
最后得到的edge[][]如下:
[0, 5, 0, 7, 0, 4, 3, 2]
[6, 1, 6, 1, 6, 7, 3, 2]
[6, 5, 2, 7, 5, 7, 3, 2]
[6, 5, 6, 3, 6, 7, 3, 2]
[6, 5, 6, 7, 4, 4, 3, 4]
[6, 5, 6, 1, 5, 5, 3, 5]
[6, 5, 6, 7, 6, 7, 6, 2]
[6, 5, 6, 7, 5, 7, 3, 7]
by @sunhaiyu
2017.9.24