目的爬取链家网租房信息,对北京市各个区域房源量、租房价格、房屋面积有个大致的分析了解
欲爬取以下信息,使用Scrapy自动爬虫
title 标题
link 链接
price 租金
unit 租金单位
square 面积
house_type 居室
height 层高
orientation 朝向
location 区域
business_region 商圈
village 小区
traffic 地铁信息
longitude 经度
latitude 纬度
第一步,创建爬虫项目 lianjia
第二步,配置items,
title = scrapy.Field()
link = scrapy.Field()
price = scrapy.Field()
unit = scrapy.Field()
square = scrapy.Field()
house_type = scrapy.Field()
height = scrapy.Field()
orientation = scrapy.Field()
location = scrapy.Field()
business_region = scrapy.Field()
village = scrapy.Field()
traffic = scrapy.Field()
longitude = scrapy.Field()
latitude = scrapy.Field()
第三步,重要的是爬虫文件,rent.py
def start_requests(self):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:57.0) Gecko/20100101 Firefox/57.0'} # 伪装成浏览器
for i in range(2, 62): # 考虑到百度地图api接口对未认证的开发者每天只能访问2000次,所以限制了页数,
url = 'https://bj.lianjia.com/zufang/pg%s/' % str(i)
yield Request(url,headers = headers, meta = {'proxy':'http://127.0.0.1:8888'}) # 代理ip地址一定要加上 http://否则有可能报错
rules = (
Rule(LinkExtractor(allow=r'https://bj.lianjia.com/zufang/[0-9]+?.html'), callback='parse_item', follow=True),
)
# 自动爬虫需要设置rules来自动获取下一页要爬的链接,观察链家网的网址可以发现,房源网址是由 https://bj.lianjia.com/zufang/加上房源编号得到的,所以,
# 设置为 https://bj.lianjia.com/zufang/[0-9]+?.html
接下来比较麻烦的就是 xpath 各种所需信息了,不再赘述
i['price'] = response.xpath('//span[@class="total"]/text()').extract()
i['unit'] = response.xpath('//span[@class="unit"]//span/text()').extract()
i['square'] = response.xpath('//div[@class="zf-room"]/p[i[text()="面积:"]]/text()').extract()
i['house_type'] = [response.xpath('//div[@class="zf-room"]/p[i[text()="房屋户型:"]]/text()').extract()[0].split(' ')[0]]
i['height'] = response.xpath('//div[@class="zf-room"]/p[i[text()="楼层:"]]/text()').extract()
i['orientation'] = response.xpath('//div[@class="zf-room"]/p[i[text()="房屋朝向:"]]/text()').extract()
i['location'] = [response.xpath('//div[@class="zf-room"]/p[i[text()="位置:"]]/a/text()').extract()[0]]
i['business_region'] = [response.xpath('//div[@class="zf-room"]/p[i[text()="位置:"]]/a/text()').extract()[1]]
i['village'] = [response.xpath('//div[@class="zf-room"]/p[i[text()="小区:"]]/a/text()').extract()[0]]
i['traffic'] = response.xpath('//div[@class="zf-room"]/p[i[text()="地铁:"]]/text()').extract()
比较重要的一点,小区的经纬度是将小区名称作为参数,通过百度地图api接口调用经纬度数据,开发文档地址:http://lbsyun.baidu.com/index.php?title=webapi/guide/webservice-geocoding
url = http://api.map.baidu.com/geocoder/v2/?output=json&ak=****自己申请的key****&city=%E5%8C%97%E4%BA%AC%E5%B8%82&address=天安门
# city 表示城市,address输入小区地址
# 如上url,直接粘贴到浏览器中会返回json数据
{
status: 0,
result: {
location: {
lng: 116.40390583019587,
lat: 39.9151754663074
},
precise: 0,
confidence: 25,
level: "UNKNOWN"
}
}
BUT 不造为什么,有时候会获取不到经纬度信息,所以只能加个判断了
try:
i['longitude'] = [result['result']['location']['lng']]
i['latitude'] = [result['result']['location']['lat']]
except Exception as e:
print('Error:这个地点没有查到对应的经纬度---- %s' % str(e))
i['longitude'] = [0]
i['latitude'] = [0]
最后,使用pymysql存储数据,需要注意的是,由于字段较多,写sql的时候可能会出现小错误。。。没错,这是一个吃过亏的人的肺腑之言
sql = '''insert into lianjia(link, title, price, unit, square, house_type, height, orientation, location,
business_region,village,traffic,longitude, latitude) values ('%s','%s','%s','%s','%s','%s','%s','%s',
'%s','%s','%s','%s', %.6f, %.6f);''' % (title,link, price, unit,square, house_type, height, orientation, location,
business_region,village,traffic,longitude, latitude)
然后就开始爬吧,爬啊爬
担心链家网有什么反爬手段,再给我封了,所以加上了随机暂停,爬的比较慢,最后爬了四百多条
a = random.randint(0,5)
time.sleep(a)
不行了,我要去睡觉了。。。直接暂停爬虫睡觉,
.
.
.
等会儿,睡觉前做个热力图看看先

修改一下比例
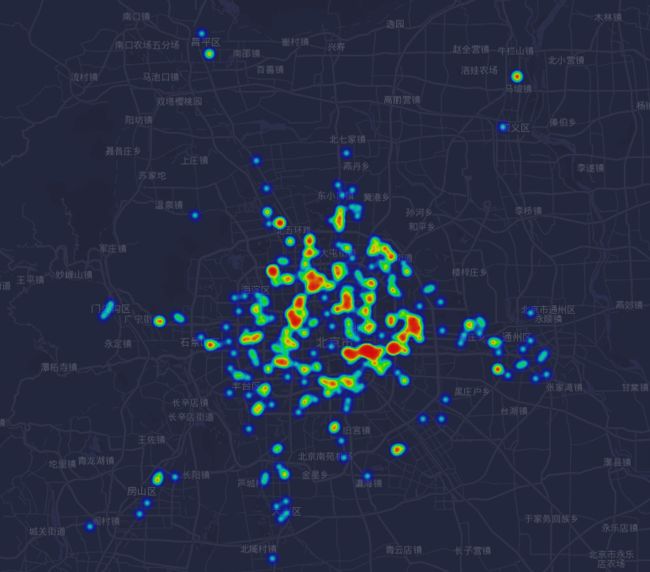
额,你看出了什么?困了,睡觉。。。zzZZ
附:项目地址 https://gitee.com/vvaganvv/python/tree/master/spider/lianjia