JavaScript正则表达式
1.了解正则表达式的语法。
2.在IDE中使用正则表达式处理规则复杂的字符串查找,替换需求。
3.在JavaScript程序设计中使用正则表达式处理字符串。
正则表达式概念:
Regular Expression使用单个字符串来描述,匹配一系列符合某个句法规则的字符串。简单说,就是按照某种规则去匹配符合条件的字符串。regexper
正则表达式工具:http://regexper.com
RegExp对象:
JavaScript通过内置对象RegExp支持正则表达式
有两种实例化RegExp对象的方法:
1.使用字面量
2.使用构造函数
字面量:
var reg = / \bis\b /g; 替换is \b单词边界,确保匹配的是is不是this这种。 最后那个g是用来表示全局global,如果加g是全局匹配,如果不加是匹配完了第一个,后面的不匹配。
.replace(reg, ' ') 这个replace方法,第一个参数可以传字符串,也可以传正则表达式。第二个参数传递的是要替换成为的内容。
'this is xxx, that is ooo'.replace(reg,'IS')
构造函数:
var reg = new RegExp('\\bis\\b' , 'g' );
'this is xxx, that is ooo'.replace(reg,'IS')
修饰符:
g:global全局搜索,不添加此项则搜索到第一个就匹配停止
i:ignore case忽略大小写,正常的正则表达式,是默认对大小写敏感的。
m:multiple lines多行搜索。当被处理的字符串有换行符的时候,吧换的行全部当做新的一行。
eg: 'this is xxx, that is ooo'.replace(/\bis\b/gi,'IS')
元字符:
正则表达式由两种基本字符类型组成:
1.原义文本字符:写啥就代表啥
2.元字符:在正则表达式中有特殊含义的非字母字符。比如\b,这个就表达匹配并不是\b而是字符边界。
* + ? $ ^ . | \ ( ) { } [ ]

字符类:
1.一般情况下,正则表达式一个字符,对应字符串一个字符。
eg:ab\t的含义 --"ab"--tab--
2.我们可以使用元字符[ ]来构建一个简单的类。所谓类,就是指符合某些特性的对象,一个泛指。
eg:[abc]的含义 "a" or "b" or "c" 有abc中一个即可。
'a1b2c2'.replace(/[abc]/g, 'x') ------"x1x2x3"
字符类取反:
1.使用元字符^创建反向类/负向类:即不属于某类的内容
eg:[^abc]的含义 不是字符a or b or c的内容。
'a1b1c3d4'.replace(/[^abc]/g, 'X') ---------"aXbXcXXX"
范围类:
正则提供了范围类,来简化范围类型过滤。
eg:[a-z]的含义是 从a-z的任意字符,且这是闭区间,包含a和z本身。
'a1b2d3x4z9'.replace(/[a-z]/g, 'Q') ---------Q1Q2Q3Q4Q9
eg:[a-zA-Z]组成类内部连写,表示 大写,或者小写a-z都可以匹配。
ps:短横线在字符之间,表示的是范围,在最后,表示匹配短横线
'2018-09-08'.replace(/[0-9]/g, 'A') -------AAAA-AA-AA
'2018-09-08'.replace(/[0-9-]/g, 'A') -------AAAAAAAAAA
预定义类:
正则表达式提供了预定义类,来匹配常见的字符类。
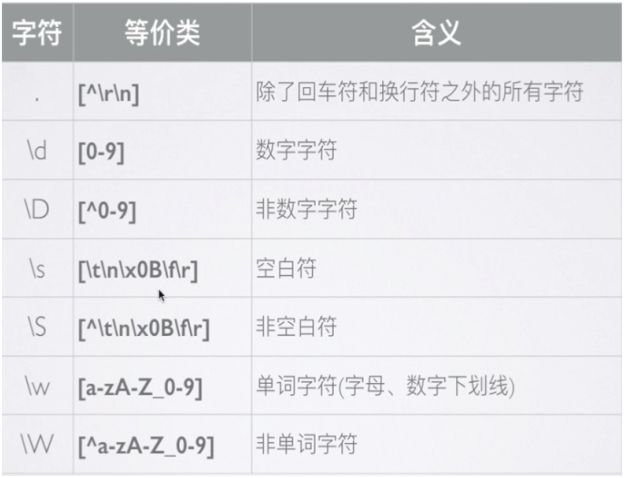
eg:匹配一个ab + 数字 + 任意字符 的字符串
/ab\d./
边界:

eg:'this is a test'.replace(/\Bis\b/g , '0'); ------th0 is a test
'this is a test'.replace(/\bis\b/g , '0'); ------this 0 a test
'@123@bxd@'replace(/@./g, 'Q'); -------Q123Qbxd@
'@123@bxd@'replace(/^@./g, 'Q'); ----------Q123@bxd@
'@123@bxd@'replace(/.@$/g, 'Q'); ----------@123@bxdQ
量词:

贪婪模式&非贪婪模式:
贪婪模式:默认
'12345678'.replace(/\d{3,6}/g, 'X'); ---------X78
在这种模式下是匹配3-6次。会选择匹配6次,尽可能多的匹配。
非贪婪模式:在量词后面加?
'12345678'.replace(/\d{3,6}?/g, 'X'); ---------XX78
尝试最少可能就匹配成功。
分组:
eg:匹配字符串Byron连续出现三次的场景。
使用Byron{3}此处是匹配n循环3次,量词只能作用于紧挨着他的字符。不可以作用于全局。所以需要分组,使用()可以达到分组的功能,使量词作用于分组。(Byron){3}
'a1b2c4'.replace(/([a-z]\d){3}/, 'x'); --------x
或:使用 |
eg:'ByronsperByrCasper'.replace(/Byr(on|Ca)sper/g, 'x'); -----------xx
反向引用:
eg:2015-12-25 => 12/25/2015
'2015-12-25'.replace(/(\d{4})-(\d{2})-(\d{2})/g, '$3-$2-$1')
首先,需要注意,只有用()分组后,才能使用$1 $2 $3这种。
其次,需要replace替换的时候需要加引号。
忽略分组:
不希望捕获某些分组,只需要在分组内加上?:就可以了
(?:Byron).(OK) 此处ok就是分组1
前瞻:
正则表达式,从文本的头部向文本的尾部开始解析,文本尾部的方向,称为‘前’
前瞻,就是在正则表达式匹配到规则的时候,向前检查是否符合断言。与后顾/后瞻相反,js不支持后顾。
类似于。匹配到一个儿子符合规则,他老子符合规则吗。或者匹配到他老子符合规则,他儿子符合吗。
对于符合特定断言的称为肯定/正向匹配。
对于不符合的称为否定/负向匹配。

'a2*34v8'.replace(/\w(?=\d)/g, 'x'); ----------x2*x4X8
ps:其中(?=\d)部分只是断言,并非正则,他只是条件,不参与过滤。
对象属性:
global:是否是全局搜索,默认false
ignore case:是否是大小写铭感,默认false
multiline:多行搜索,默认false
lastIndex:当前表达式匹配内容后,表示当前表达式最后一个字符的下一个位置
source:正则表达式的文本字符串
test & exec 方法:
RegExp.prototype.test(str) 参数是字符串
用来测试字符串参数中是否存在匹配正则表达式模式的字符串。存在返回true,反之返回false。
RegExp.prototype.exec(str) 参数是字符串
使用正则表达式模式对字符串执行搜索,并将更新全局RegExp对象的属性以反映匹配结果。
如果没有匹配的文本则返回null,否则返回一个结果数组:
--index 声明匹配文本的第一个字符的位置
--input 存放被检索的字符串string
字符串对象方法:
String.prototype.search(reg)
参数可以是字符串也可以是正则表达式。用于检索字符串中指定子字符串,或者检索与正则表达式相匹配的子字符串。如果有,返回第一个匹配结果index,查不到返回-1。此方法不执行全局匹配,总是从字符串的开始进行检索。
String.prototype.match(reg)
是用于检索字符串,找到一个或者多个与regexp匹配的文本,对全局g敏感。
String.prototype.split(reg)
用于吧字符串切割成数组,在一些负责的情况,我们可以使用正则表达来切割。
String.prototype.replace(reg)
第一个参数查找匹配内容,第二个替换内容。
匹配内容可以是正则,可以是字符串
替换内容可以是字符串,可以是function函数返回值。
如果替换的是function函数,function可以传入4个参数,
匹配字符串;正则表达式分组内容,木有分组则没有该参数;匹配项目在字符串中的index;原字符串;