We propose an energy efficient inference engine (EIE) that performs inference on this compressed network model and accelerates the resulting sparse matrix-vector multiplication with weight sharing.
- Going from DRAM to SRAM gives EIE 120× energy saving
- EIE is 189× and 13× faster when compared to CPU and GPU implementations of the same DNN without compression
Introduction
The total energy is dominated by the required memory access if there is no data reuse. Large networks do not fit in on-chip storage and hence require the more costly DRAM accesses.
EIE takes advantage of dynamic input vector sparsity, static weight sparsity, relative indexing, weight sharing and extremely narrow weights (4bits).
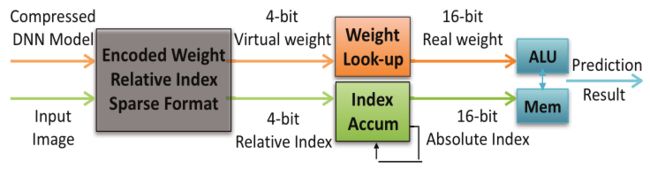
Approach
-
Computation
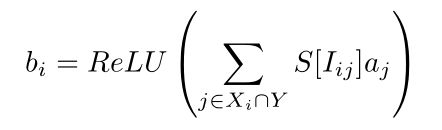
To exploit the sparsity of activations we store our encoded sparse weight matrix W in a variation of compressed sparse column (CSC) format. We encode the following column [0,0,1,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,3] as v = [1,2,0,3], z = [2,0,15,2].
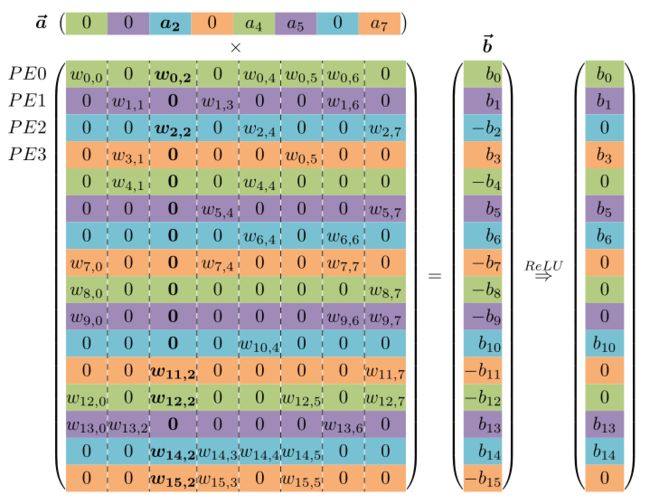
Parallelizing
We perform the sparse matrix × sparse vector operation by scanning vector a to find its next non-zero value a_j and broadcasting a j along with its index j to all PEs. Each PE then multiplies a_j by the non-zero elements in its portion of column W_j — accumulating the partial sums in accumulators for each element of the output activation vector b. To address the output accumulators, the row number i corresponding to each weight W ij is generated by keeping a running sum of the entries of the x array.Hardware implementation
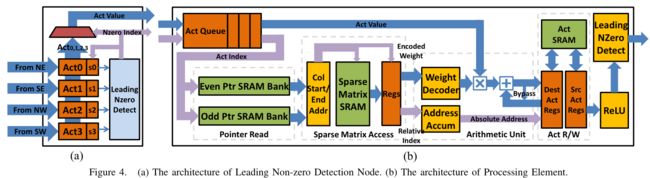
A Central Control Unit (CCU) receives non-zero input activations from a distributed leading non-zero detection network and broadcasts these to the PEs.
Non-zero elements of the input activation vector a j and their correspond-ing index j are broadcast by the CCU to an activation queue in each PE. The activation queue allows each PE to build up a backlog of work to even out load imbalance that may arise.
Sparse Matrix Read Unit: The sparse-matrix read unit uses pointers p_j and p_j+1 to read the non-zero elements of this PE’s slice of column I_j from the sparse-matrix SRAM. Each entry in the SRAM is 8-bits in length and contains one 4-bit element of v and one 4-bit element of x. For efficiency the PE’s slice of encoded sparse matrix I is stored in a 64-bit-wide SRAM. Thus eight entries are fetched on each SRAM read. The high 13 bits of the current pointer p selects an SRAM row, and the low 3-bits select one of the eight entries in that row. A single (v,x) entry is provided to the arithmetic unit each cycle.
Arithmetic Unit:The arithmetic unit receives a (v,x) entry from the sparse matrix read unit and performs the multiply-accumulate operation b_x = b_x + v × a_j.
References:
EIE: Efficient Inference Engine on Compressed Deep Neural Network, Song Han, 2016, International Symposium on Computer Architecture