本文作者:林伟兵,叩丁狼高级讲师。原创文章,转载请注明出处。
3.5.使用DBeaver客户端
Phoenix常见的客户端连接工具有SQuirrel和DBeaver,这里主要介绍DBeaver客户端的使用方式。
安装DBeaver,启动DBeaver,将 phoenix-[version]-client.jar 拷贝到客户端。
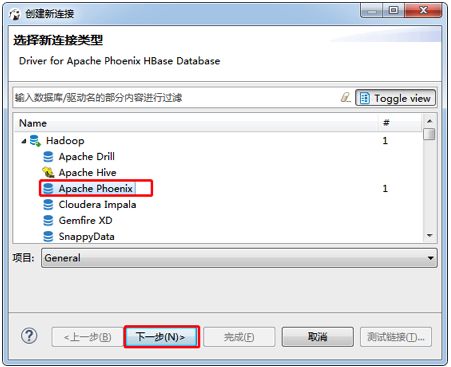

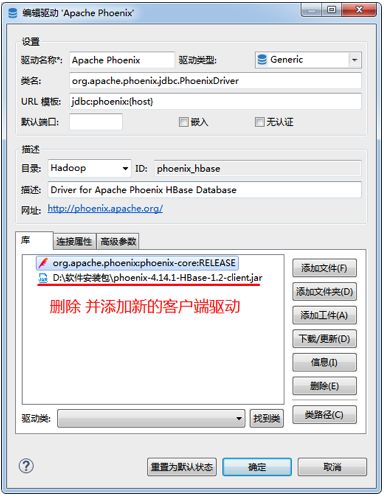
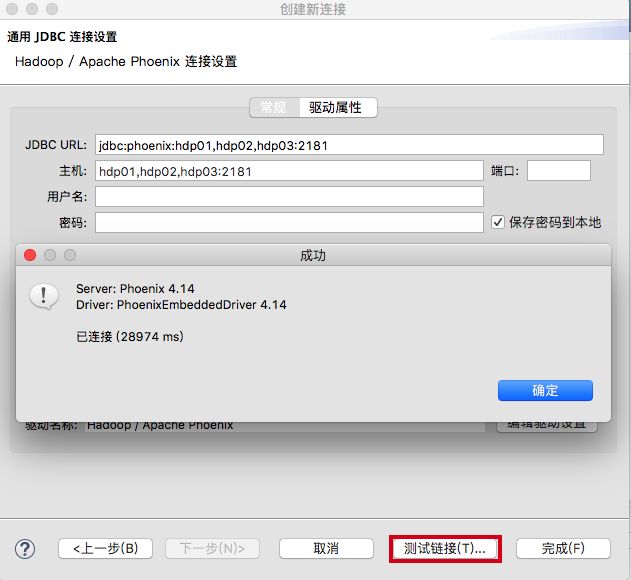
注意:客户端如何缺失某些参数配置,可以上面第4步的驱动属性添加再测试连接,这是因为DBeaver不支持hbase-site.xml配置文件的使用.
3.6.Phoenix二级索引
前一章介绍了Phoenix简单的DDL和CURD操作,接下来这一节主要介绍Phoenix独有的特性[二级索引](http://phoenix.apache.org/secondary_indexing.html),并在DBeaver中实践。
对HBase来说,我们通常使用字典序的RowKey来快速访问数据,除此之外也可使用自定义的Filter来搜索数据,但是它是基于全表扫描的。而Phoenix提供的二级索引是避开了全表扫描,其利用空间换时间的来解决查询过程中的缓慢问题;默认情况下客户端不支持二级索引,需要将以下配置添加到HBase的各个RegionServer节点的hbase-site.xml文件中:
hbase.regionserver.wal.codec
org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
覆盖索引 Covered Indexes
Phoenix提供了一种叫Covered Index的二级索引。这种索引在获取数据的过程中,内部不需再去HBase原表中获取任何数据,转而在索引表查询结果即可。
要想达到这种效果,你的select 的列,where 的列都需要在索引表中出现。举个例子,如果你的SQL语句是SELECT name FROM WOLFCODE_MDB.t_employee ORDER BY SALARY DESC;,要达到最大化查询效率和速度最快,你就需要建立覆盖索引:
CREATE INDEX salary_idx ON wolfcode_mdb.t_employee(salary DESC) INCLUDE (name);
## 原表的内容是:
+-----+-----------+----------+---------+
| ID | NAME | SALARY | GENDER |
+-----+-----------+----------+---------+
| 1 | zhangsan | 10800.0 | M |
| 2 | lisi | 9900.0 | M |
| 3 | wangwu | 7500.0 | F |
| 4 | zhaoliu | 10000.0 | M |
+-----+-----------+----------+---------+
## 索引表建立后内容是:
+-----------+------+-----------+
| 0:SALARY | :ID | 0:NAME |
+-----------+------+-----------+
| 1.08E+4 | 1 | zhangsan |
| 1E+4 | 4 | zhaoliu |
| 9.9E+3 | 2 | lisi |
| 7.5E+3 | 3 | wangwu |
+-----------+------+-----------+
## 当执行如下SQL时,系统会找到对应的二级索引表进行查询,二级索引表的表内容明显比原表的内容少,并且在查询的过程无需再次排序,这也大大减少了查询的时间。
## 但是索引表的建立无疑也降低了集群的存储能力。
SELECT name FROM WOLFCODE_MDB.t_employee ORDER BY SALARY DESC;
覆盖索引就是一种典型的全局索引,全局索引适合那些读多写少的场景。使用全局索引,读数据基本不损耗性能,所有的性能损耗都来源于写数据。数据表的添加、删除和修改都会更新相关的索引表。而查询数据的时候,Phoenix会通过索引表来快速低损耗的获取数据。
如下当在原表插入数据后,索引表也会插入对应的数据:
UPSERT INTO t_employee VALUES(5,'亦舒',8800,'F');
+-----------+------+-----------+
| 0:SALARY | :ID | 0:NAME |
+-----------+------+-----------+
| 1.08E+4 | 1 | zhangsan |
| 1E+4 | 4 | zhaoliu |
| 9.9E+3 | 2 | lisi |
| 8.8E+3 | 5 | 亦舒 |
| 7.5E+3 | 3 | wangwu |
+-----------+------+-----------+
如果某个查询已不在频繁,建议删除索引表以换取更多的空间,代码如下:
use wolfcode_mdb;
DROP INDEX SALARY_IDX ON wolfcode_mdb.t_employee;
函数索引 Functional Indexes
函数索引从4.3版本就有,这种索引的内容不局限于列,还能在表达式上建立索引。如果你使用的表达式正好就是索引的话,数据也可以直接从这个索引获取,而不需要从数据库获取。比如说,在一个表达式上建立索引,这个表达式是salary * 12,值得注意的是,函数索引不支持排序:
CREATE INDEX SALARY_PER_YEAR_IDEX2 ON t_employee(salary * 12);
SELECT * FROM wolfcode_mdb.SALARY_PER_YEAR_IDEX2;
## 查询结果如下
+-----------------+------+
| :(SALARY * 12) | :ID |
+-----------------+------+
| 9E+4 | 3 |
| 1.056E+5 | 5 |
| 1.188E+5 | 2 |
| 1.2E+5 | 4 |
| 1.296E+5 | 1 |
+-----------------+------+
本地索引 Local Indexes
本地索引适合那些写多读少或存储空间有限的场景。和全局索引一样,Phoenix也会在查询的时候自动选择是否使用本地索引。本地索引之所以是本地,主要是因为索引数据和真实数据存储在同一台机器上,这样做主要是为了避免网络数据传输的开销。
异步创建索引
注意:https://yq.aliyun.com/ask/438584/
注意:http://hbase.group/question/27
一般我们可以使用CREATE INDEX来创建一个索引,这是一种同步的方法。但是有时候我们创建索引的表非常大,我们需要等很长时间。Phoenix 4.5以后有一个异步创建索引的方式,使用关键字ASYNC来创建索引:
CREATE INDEX my_index ON t_employee(salary desc) async;
SELECT * FROM my_index;
这时候创建的索引表中不会有数据。你还必须要单独的使用命令行工具来执行数据的创建。当语句给执行的时候,后端会启动一个map reduce任务,只有等到这个任务结束,数据都被生成在索引表中后,这个索引才能被使用。启动工具的方法:
${HBASE_HOME}/bin/hbase org.apache.phoenix.mapreduce.index.IndexTool \
--schema wolfcode_mdb --data-table t_employee --index-table my_index \
--output-path /async_idx_hfiles
这个任务不会因为客户端给关闭而结束,是在后台运行。你可以在指定的文件ASYNC_IDX_HFILES中找到最终实行的结果。
3.7.JDBC API的实现
-
添加依赖。
org.apache.phoenix phoenix-core 4.14.1-HBase-1.2 -
添加日志。
### set log levels ### log4j.rootLogger = debug , stdout , D , E ### 输出到控制台 ### log4j.appender.stdout = org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target = System.out log4j.appender.stdout.layout = org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern = %d{ABSOLUTE} %5p %c 1 :%L - %m%n -
因为之前服务端已经添加了支持分组的功能,所以还要添加hbase-site.xml文件。
hbase.regionserver.wal.codec org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec phoenix.schema.isNamespaceMappingEnabled true -
测试JDBC客户端连接状况:
public class ConnectionTest { public static void main(String[] args) { Connection conn=null; Statement stmt = null; try { Class.forName("org.apache.phoenix.jdbc.PhoenixDriver"); conn = DriverManager .getConnection("jdbc:phoenix:hdp01,hdp02,hdp03:2181"); stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("select * from wolfcode_mdb.t_employee"); while (rs.next()) { String name = rs.getString("name"); double salary = rs.getDouble("salary"); String gender = rs.getString("gender"); System.out.println("name:" + name + ",salary:" + salary + ",gender:" + gender); } } catch (Exception e) { e.printStackTrace(); }finally { try { stmt.close(); conn.close(); }catch (SQLException e) { e.printStackTrace(); } } } } -
测试CURD:
public class CURDTest { private Connection _conn = null; private PreparedStatement _stmt = null; @Before public void init() { try { Class.forName("org.apache.phoenix.jdbc.PhoenixDriver"); _conn = DriverManager .getConnection("jdbc:phoenix:hdp01,hdp02,hdp03:2181"); } catch (Exception e) { e.printStackTrace(); } } @Test public void testQuery() throws SQLException { String sql = "select * from wolfcode_mdb.t_employee"; _stmt = _conn.prepareStatement(sql); ResultSet rs = _stmt.executeQuery(); while (rs.next()) { String name = rs.getString("name"); double salary = rs.getDouble("salary"); String gender = rs.getString("gender"); System.out.println("name:" + name + ",salary:" + salary + ",gender:" + gender); } } @Test public void testInsert() { try { String sql = "upsert into wolfcode_mdb.t_employee values (?,?,?,?)"; _stmt = _conn.prepareStatement(sql); _stmt.setLong(1, 6); _stmt.setString(2, "赵无眠"); _stmt.setDouble(3, 9700.00d); _stmt.setString(4, "F"); _stmt.execute(); // 如无自动提交任务,是不会生效的。 _conn.commit(); }catch (Exception e){ e.printStackTrace(); } } @Test public void testDelete() { try { String sql = "delete from wolfcode_mdb.t_employee where name=?"; _stmt = _conn.prepareStatement(sql); _stmt.setString(1, "赵无眠"); _stmt.execute(); // 如无自动提交任务,是不会生效的。 _conn.commit(); }catch (Exception e){ e.printStackTrace(); } } @Test public void testUpdate() { try { //更新数据必须携带主键,否则更新失败 String sql = "upsert into wolfcode_mdb.t_employee(id,name) values(?,?)"; _stmt = _conn.prepareStatement(sql); _stmt.setLong(1, 1); _stmt.setString(2, "张三"); _stmt.execute(); // 如无自动提交任务,是不会生效的。 _conn.commit(); }catch (Exception e){ e.printStackTrace(); } } @After public void destory() { try { if (null != _stmt && !_stmt.isClosed()) { _stmt.close(); } if (null != _conn && !_conn.isClosed()) { _conn.close(); } } catch (SQLException e) { e.printStackTrace(); } } }
4. 加盐表
什么是加盐?
加盐可以简单的理解为加密。
举个例子,假设我们要做一个人员管理系统,将用户登陆的账号密码直接保存到数据库上,用户登陆时先去数据库匹配,成功则登陆。但是实际的应用系统中这是非常不安全的,账户密码不论是在数据库中存储还是在网上传输过程中都应该是密文而不能是明文。
一般都是采用MD5或者SHA加密算法把密码加密,我们把这种方式称之为加盐,这个盐一般是一个字符串,在本案例中,该字符串是固定的,我们称之为固定盐。
固定盐也是不安全的,因为网上也有各种在线MD5解密的网站,黑客可以通过这些解密网站对密码进行破解测试。这时就可以采用动态加盐的方式来增加密码的安全性,比如,我们可以将需要这个固定的字符串改为每个用户的账号。每个用户都需要用一个库去比较,大大增加了破解所有账户的难度。
Phoenix的加盐有什么好处?
传统的加盐主要是用来增加数据的安全性,而Phoenix中加盐是指对primary key对应的字节数组插入特定的byte数据。因为primary key底层对应的是HBase的row key。在插入数据的时候,单调递增rowkey会存储在某一个RS上,使得负载集中在某一个RegionServer上引起的热点问题。加盐可以解决这一问题。
怎么对表加盐?
在创建表的时候指定属性值:SALT_BUCKETS,其值表示所分buckets(region)数量, 范围是1~256。
use wolfcode_mdb;
CREATE TABLE t_scores(id varchar primary key,student varchar,scores varchar array[3]) salt_buckets = 4;
加盐的过程就是在原来key的基础上增加一个byte作为前缀,计算公式如下:
new_row_key = (++index % BUCKETS_NUMBER) + original_key
原理:

测试:
upsert into t_scores values('100','aaa',ARRAY['75','75','75']);
upsert into t_scores values('200','bbb',ARRAY['75','75','75']);
upsert into t_scores values('300','ccc',ARRAY['75','75','75']);
upsert into t_scores values('400','ddd',ARRAY['75','75','75']);
upsert into t_scores values('500','eee',ARRAY['75','75','75']);
upsert into t_scores values('600','fff',ARRAY['75','75','75']);
upsert into t_scores values('700','ggg',ARRAY['75','75','75']);
upsert into t_scores values('800','hhh',ARRAY['75','75','75']);
upsert into t_scores values('900','iii',ARRAY['75','75','75']);
验证Region的个数:

想获取更多技术干货,请前往叩丁狼官网:http://www.wolfcode.cn/all_article.html