该系列文章为,观看“吴恩达机器学习”系列视频的学习笔记。虽然每个视频都很简单,但不得不说每一句都非常的简洁扼要,浅显易懂。非常适合我这样的小白入门。
本章含盖
- 1.1 引言
- 1.2 机器学习是什么?
- 1.3 监督学习
- 1.4 无监督学习
引言
机器学习发源于人工智能领域 我们希望能够创造出具有智慧的机器 我们通过编程来让机器完成一些基础的工作。比如,“如何找到从A到B的最短路径”,但在大多数情况下我们并不知道如何显式地编写人工智能程序来做一些更有趣的任务,比如,“网页搜索”、“标记照片”和“拦截垃圾邮件”等
你也许曾经接触过自然语言处理和计算机视觉。事实上,这些领域都是试图通过人工智能来理解人类的语言和图像。如今大多数的自然语言处理和计算机视觉都是对机器学习的一种应用,机器学习算法也在用户自定制化程序(self-customizing program)中有着广泛的应用。每当你使用亚马逊 Netflix或iTunes Genius的服务时都会收到它们为你量身推荐的电影或产品,这就是通过学习算法来实现的。
最后,机器学习算法已经被应用于探究人类的学习方式并试图理解人类的大脑。我们也将会了解到研究者是如何运用机器学习的工具来一步步实现人工智能的梦想。
1.2 机器学习是什么?
Tom Mitchell (来自卡内基梅隆大学)定义的机器学习是:一个程序被认为能从经验 E 中学习,解决任务 T,达到性能度量值 P,当且仅当,有了经验 E 后,经过 P 评判,程序在处理 T 时的性能有所提升。
举个例子,下棋 ——— 我认为经验 E 就是程序上万次的自我练习(下棋)的经验而任务 T 就是(同未知的对手)下棋。性能度量值 P 呢,就是它在与一些新的对手比赛时,赢得比赛的概率。
目前存在几种不同类型的学习算法。主要的两种类型被我们称之为“监督学习”和“无监督学习”。此外你将听到诸如,强化学习和推荐系统等各种术语。这些都是机器学习算法的一员,以后我们都将介绍到,但学习算法最常用两个类型就是监督学习、无监督学习。
给你讲授学习算法就好像给你一套工具,相比于提供工具,可能更重要的,是教你如何使用这些工具。我喜欢把这比喻成学习当木匠。想象一下,某人教你如何成为一名木匠,说这是锤子,这是螺丝刀,锯子,祝你好运,再见。这种教法不好,不是吗?你拥有这些工具,但更重要的是,你要学会如何恰当地使用这些工具。
1.3 监督学习
例一:根据房屋大小,对房屋价格进行预期(回归问题)
用一条直线拟合数据如下数据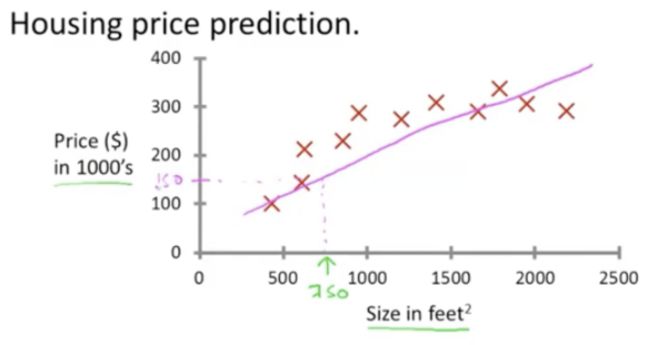
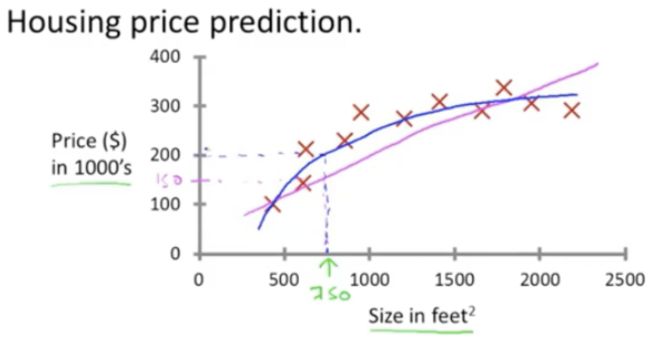
这是监督学习算法的一个例子。
监督学习指的就是我们给学习算法一个数据集。这个数据集由“正确答案”组成。在房价的例子中,我们给了一系列房子的数据,我们给定数据集中每个样本的正确价格, 即它们实际的售价。然后,运用学习算法得到更多的正确答案(即,算法的目的就是得到更多的正确答案)。
用更专业的术语来定义,它也被称为“回归问题”。这里的“回归问题”我指的是:我们想要预测连续的数值输出,即价格。
例二:根据肿瘤大小,对肿瘤是良性还是恶性的预测(分类问题)

横轴:肿瘤尺寸
纵轴:1或0,代表 是或否(恶性肿瘤)
机器学习的问题是,能否估计出肿瘤是良性还是恶性的概率。
用更专业的术语来说,这是一个分类问题。分类指的是,我们试着推测出离散的输出值。
eg:0 或 1 良性或恶性,而事实上在分类问题中,输出可能不止两个值。比如说可能有三种乳腺癌,所以你希望预测离散输出 0、1、2、 3。0 代表良性,1 表示第 1 类乳腺癌,2 表示第 2 类癌症,3 表示第 3 类,但这也是分类问题。
在其他机器学习问题中,我们通常有更多的特征,比如肿块密度,肿瘤细胞尺寸的一致性和形状的一致性等等。
你想用无限多种特征,好让你的算法可以利用大量的特征,或者说线索来做推测。那你怎么处理无限多个特征,甚至怎么存储这些特征都存在问题,你电脑的内存肯定不够用。后面我们会讲一个算法,叫支持向量机,里面有一个巧妙的数学技巧,能让计算机处理无限多个特征。
无监督学习
对于监督学习里的每条数据, 我们已经清楚地知道,训练集对应的正确答案。
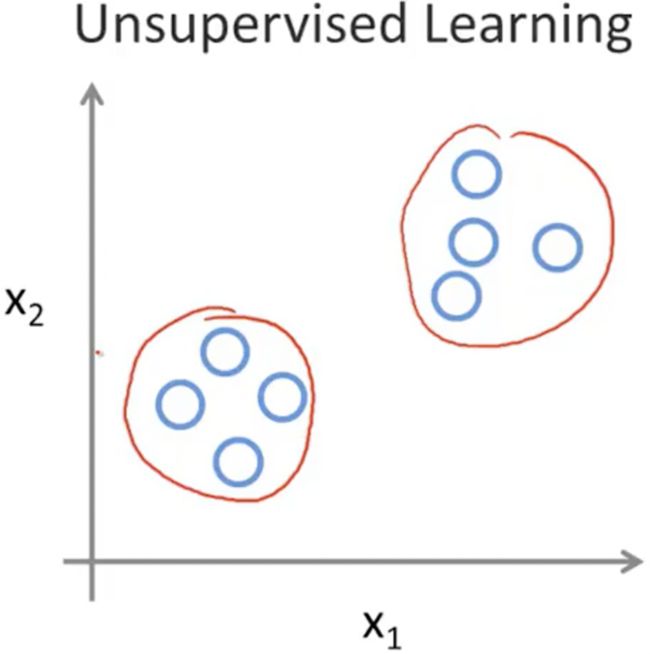
在无监督学习中,我们已知的数据。看上去有点不一样,不同于监督学习的数据的样子, 无监督学习中没有任何的标签。所以我们已知数据集,却不知如何处理,也未告知每个数据点是什么。别的都不知道,就是一个数据集。你能从数据中找到某种结构吗?针对数据集,无监督学习就能判断出数据有两个不同的聚集簇。 这是一个,那是另一个,二者不同。是的,无监督学习算法可能会把这些数据分成两个不同的簇。所以叫做聚类算法。事实证明,它能被用在很多地方。
聚类应用的一个例子就是在谷歌新闻中。如果你以前从来没见过它,你可以到这个 URL 网址 news.google.com 去看看。谷歌新闻每天都在收集非常多非常多的网络的新闻内容。 它再将这些新闻分组,组成有关联的新闻。所以谷歌新闻做的就是搜索非常多的新闻事件, 自动地把它们聚类到一起。所以,这些新闻事件全是同一主题的,并会显示到一起。
所以这个就是无监督学习,因为我们没有提前告知算法一些信息。我们只是说,是的,这是有一堆数据。我不知道这些数据是什么。我不知道谁是什么类型。我甚至不知道有哪些不同的类型,你能自动地找到数据中的结构吗?就是说你要自动地聚类那些个体到各个类,我没法提前知道哪些是哪些。因为我们没有给算法正确答案来回应数据集中的数据,所以这就是无监督学习。
无监督学习或聚类有着大量的引用:
- 它用于组织大型计算机集群。我有些朋友在大数据中心工作,那里有大型的计算机集群,他们想解决什么样的机器易于协同地工作,如果你能够让那些机器协同工作,你就能让你的数据中心工作得更高效。
- 第二种应用就是社交网络的分析。所以已知你朋友的信息,比如你经常发 email 的,或是你 Facebook 的朋友、谷歌+圈子的朋友,我们能否自动地给出朋友的分组呢?即每组里的人们彼此都熟识,认识组里的所有人?
- 还有市场分割。许多公司有大型的数据库,存储消费者信息。所以,你能检索这些顾客数据集,自动地发现市场分类,并自动地把顾客划分到不同的细分市场中,你才能自动并更有效地销售或不同的细分市场一起进行销售。这也是无监督学习,因为我们拥有所有的顾客数据,但我们没有提前知道是什么的细分市场,以及分别有哪些我们数据集中的顾客。我们不知道谁是在一号细分市场,谁在二号市场,等等。那我们就必须让算法从数据中发现这一切。
- 最后,无监督学习也可用于天文数据分析,这些聚类算法给出了令人惊讶、有趣、有用的理论,解释了星系是如何诞生的。
这些都是聚类的例子,聚类只是无监督学习中的一种。
无监督学习,它是学习机制,你给算法大量的数据,要求它找出数据的类型结构。