前言
工作加实习两年了,想总结和记录这几天的面试重点和题目,尽量把答案写出来,由于大多网上搜的或者查阅书籍,如有错误还忘指出。
大多数好的公司面的比较有深度,主要还是要靠自学和积累,文章中答案都不深度讨论,后续会细细分析。
基础篇
集合和多线程是Java基础的重中之重
1. Map 有多少个实现类?
Java自带了各种 Map 类,这些 Map 类可归为三种类型:
- 通用 Map,用于在应用程序中管理映射,通常在 Java.util 程序包中实现:
HashMap Hashtable Properties LinkedHashMap IdentityHashMap TreeMap WeakHashMap ConcurrentHashMap - 专用 Map,你通常不必亲自创建此类 Map,而是通过某些其他类对其进行访问:
java.util.Attributes javax.print.attribute.standard.PrinterStateReasons java.security.Provider java.awt.RenderingHints javax.swing.UIDefaults - 一个用于帮助实现你自己的 Map 类的抽象类:
AbstractMap
不用记住所有的,根据自己比较常用和了解的来回答就可以。
2. HashMap 是不是有序的?有序的 Map 类是哪个?Hashtable 是如何实现线程安全的?
HashMap 不是有序的,下一题通过源码来解析HashMap的结构。
LinkedHashMap 是有序的,并且可以分为按照插入顺序和访问顺序的链表,默认是按插入顺序排序的。在创建的时候如果是new LinkedHashMap,true就代表按照访问顺序排序,那么调用 get 方法后,会将这次访问的元素移至尾部,不断访问可以形成按访问顺序排序的链表。
根据源码可以看到,Hashtable 中的方法都加上了 synchronized 关键字。
3. HashMap 的实现原理以及如何扩容?
众所周知 HashMap 是数组和链表的结合,如下图所示:
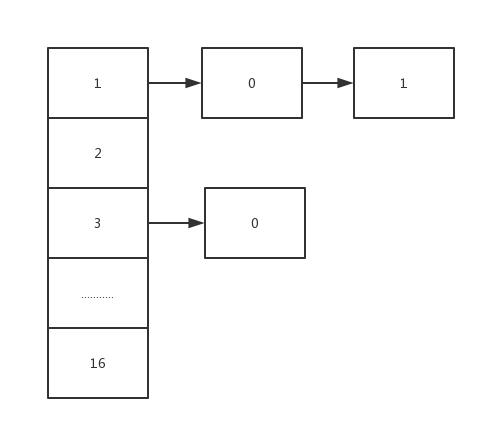
左边是连续的数组,我们可以称为哈希桶,右边连接着链表。
具体如何实现我们来看源码,在 HashMap 定义中有一个属性Entry属性,所以可以看到 HashMap 的实质是一个 Entry 数组。
看 HashMap 的初始化:
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity]; //初始化
initHashSeedAsNeeded(capacity);
}
我们看到table = new Entry[capacity]这行,这行就是 HashMap 的初始化。capacity 是容量,容量的默认大小是16,最大不能超过2的30次方。然后我们来看 put() 方法:
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if (key == null)
return putForNullKey(value);
int hash = hash(key); //计算出key的hash值
int i = indexFor(hash, table.length); //通过容量来找到key对应哈希桶的位置
//在对应的哈希桶上的链表查找是否有相同的key,如果有则覆盖
for (Entry e = table[i]; e != null; e = e.next) {
Object k;
//这里解释了map就是根据对象的hashcode和equals方法来决定有没有重复的key
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
//添加一个键值对
addEntry(hash, key, value, i);
return null;
}
可以看到,addEntry 才是真正在添加一个键值对,addEntry 方法中有扩容的操作,这个等会儿再看,所以我们直接看添加的键值对的操作:
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry e = table[bucketIndex]; //拿到哈希桶中存放的地址
//新建的entry指向刚刚那个地址,并且哈希桶指向新建的entry
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
以上注释就说明当加入一个新键值对的时候,新的键值对找到对应的哈希桶之后就插入到链表的头结点上。
接下来看扩容,我们说到数组有容量,默认16,在 HashMap 的定义中还有负载因子,默认为0.75,一旦数组存放的元素超过16*0.75=12个就需要增大哈希桶。我们看 addEntry方法:
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length); //如果是默认16,则增大到32
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
接下来看 resize 方法:
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity]; //创建新的数组,大小为原来数组的两倍
//将所有元素按照存放规则重新存放到新的数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
每次扩容都会重新计算所有 key 的哈希值以及将所有元素重排,比较浪费资源,所以在创建 HashMap 时,我们尽量初始化适当的容量以减少元素重排带来的开支。
4. List的实现类以及区别?
- ArrayList 是最常用的 List 实现类,内部是通过数组实现的,它允许对元素进行快速随机访问。数组的缺点是每个元素之间不能有间隔,当数组大小不满足时需要增加存储能力,就要将已经有数组的数据复制到新的存储空间中。当从 ArrayList 的中间位置插入或者删除元素时,需要对数组进行复制、移动、代价比较高。因此,它适合随机查找和遍历,不适合插入和删除,允许空元素。
- LinkedList 是用链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢。另外,接口中没有定义的方法get、remove、insertList,专门用于操作表头和表尾元素,可以当作堆栈、队列和双向队列使用。LinkedList 没有同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步,一种解决方法是在创建List时构造一个同步的List:
List list = Collections.synchronizedList(new LinkedList()) - 应该避免使用 Vector,它只存在于支持遗留代码的类库中。
- CopyOnWriteArrayList 是 List 的一个特殊实现,专门用于并发编程。
5. 如何实现线程并发?
用 Lock 接口的实现类或者 synchroized 关键字。
6. Lock 类比起 synchroized,优势在哪里?
Lock 接口是 JavaSE5 引入的新接口,最大的优势是为读和写分别提供了锁。
延伸:如果需要实现一个高效的缓存,它允许多个用户读,但只允许一个用户写,以此来保证它的完整性,如何实现?
读写锁 ReadWriteLock 拥有更加强大的功能,它可以分为读锁和解锁。读锁可以允许多个进行读操作的线程同时进入,但不允许写进程进入;写锁只允许一个写进程进入,在这期间任何进程都不能再进入。
要注意的是每个读写锁都有挂锁和解锁,最好将每一对挂锁和解锁操作都用 try、finally 来套入中间的代码,这样就会防止因异常发生而造成死锁的情况。
下面是一段示例:
import java.util.Random;
import java.util.concurrent.locks.ReadWriteLock;
import java.util.concurrent.locks.ReentrantReadWriteLock;
public class ReadWriteLockTest {
//用于关闭线程
public volatile static boolean blag= true;
public static void main(String[] args) throws InterruptedException {
final TheData myData = new TheData(); //各线程的共享资源
for (int i = 0; i < 3; i++) { //开启三个读线程
new Thread(new Runnable() {
@Override
public void run() {
while(blag){
myData.get();
}
}
}).start();
}
for (int i = 0; i < 3; i++) { //开启三个写线程
new Thread(new Runnable() {
@Override
public void run() {
while (blag) {
myData.put(new Random().nextInt(10000));
}
}
}).start();
}
Thread.sleep(5000);
BLAG = false;
}
}
/**
* 模拟同步读写
* @author hedy
*
*/
class TheData{
private Object data=null;
private ReadWriteLock rwl = new ReentrantReadWriteLock();
public void get(){
rwl.readLock().lock(); //读锁开启,读线程均可进入
try {
System.out.println(Thread.currentThread().getName()+" is ready to read");
Thread.sleep(new Random().nextInt(100));
System.out.println(Thread.currentThread().getName()+" have read data "+data);
} catch (InterruptedException e) {
e.printStackTrace();
}finally {
rwl.readLock().unlock(); //读锁解锁
}
}
public void put(Object data){
rwl.writeLock().lock(); //写锁开启,这时只有一个写线程进入
try {
System.out.println(Thread.currentThread().getName()+" is ready to write");
Thread.sleep(new Random().nextInt(100));
this.data = data;
System.out.println(Thread.currentThread().getName()+" have write data "+data);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
rwl.writeLock().unlock(); //写锁解锁
}
}
}
7. java中的 wait() 和 sleep() 方法有何不同?
最大的不同是在等待 wait 时会释放锁,而 sleep 一直持有锁,wait
通常被用于线程间交互,sleep 通常被用于暂停执行。
其他不同有:
- sleep 是 Thread 类的静态方法,wait 是 Object 方法
- wait,notify 和 notifyAll 只能在同步控制方法或者同步控制块里面使用,而 sleep 可以在任何地方使用
- sleep 必须捕获异常,而 wait,notiry 和 notifyAll 不需要捕获异常
8. 如何实现阻塞队列(BlockingQueue)?
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作是:在队列为空时,获取元素的线程会等待队列为飞控;当队列满时,存储元素的线程会等待队列可用。阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
阻塞队列的简单实现:
import java.util.LinkedList;
import java.util.List;
public class BlockingQueue {
private List延伸:利用 Executors 创建线程池中的消息队列情况,ThreadPoolExecutor 是 Executors 的底层,建议使用 Executors ,想了解的可以自己查找资料。
9. 创建一千个线程对一个 static 的数据进行++,之后会不会是1000,为什么?如果将 static 的数据加上 volatile 呢?
首先我们直接用代码执行一下看结果:
public class VolatileTest {
public static int count = 0;
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(1000,4000,
60l, TimeUnit.SECONDS, new LinkedBlockingQueue());
for (int i = 0; i < 4000; i++) { //由于1000个线程结果测试对比不明显,所以创建4000个
executor.execute(new ThreadPoolTask());
}
executor.shutdown(); //执行完毕后关闭线程池
while(!executor.isTerminated()){
Thread.sleep(1000);
}
System.out.println(VolatileTest.count); //线程都关闭之后输出结果
}
}
class ThreadPoolTask implements Runnable{
@Override
public void run() {
VolatileTest.count++;
}
}
结果都不尽相同,大约在4000以下徘徊。接下来分析一下原因。Java 内存模型是这样的:
- 所有的变量都存储在主内存中
- 每个线程都有自己独立的工作内存,里面保证该线程是使用到的变量副本(即内存中变量的拷贝)
JVM 还规定:
- 线程共享变量的所有操作必须在自己的工作内存中进行,不能直接从主内存中读写;
- 不同线程之间无法直接访问其他线程工作内存中的变量,线程间变量值得传递需要通过主内存来完成;
通过以上规定我们想象一下4000个线程在同时操作count++的场景:
首先 A 线程从主内存中拿到 count 值,比如说 0,放到了自己的工作内存中,在 A 没处理完,B 线程就去主内存拿 count 值,也是 0,当 A、B 线程处理完之后将 count 值再放入主内存时 count 变成了1,实际我们要的结果是 2,这时候就出现了错误。
接下来,如果我们将 count 前加 volatile 关键字,运行结果依然不保证是4000。先了解一下线程的可见性和原子性的定义:
- 可见性:一个线程对共享变量的修改,能够及时的被其他线程见到
- 原子性:一旦操作开始,那么它一定可以在可能发生的“上下文切换”之前执行完毕
而* volatile保证变量对线程的可见性,但不保证原子性 * ,如果要看volatile为什么不保证原子性可以看这篇文章。
而如果把 count 改为 AtomicInteger 类型,则即可以保证对线程的可见性以及原子性。
10. 在 synchroized 方法上加 static 和不加 static 的区别是什么?
synchroized 在修饰方法时称为对象锁,加了 static 则是类锁,对象锁则是每个对象都有一把锁,而类锁只有一个,即所有对象在调用此方法的时候共同用同一把锁。