首先需要编程应用的四层抽象:
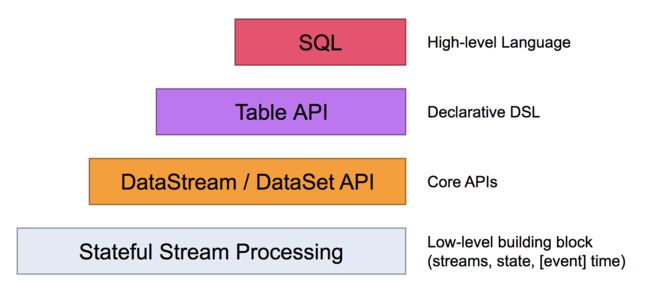
最底下的一层对用户是不可见的, 通过ProcessFunction集成到DataStream API. 我们的编程对象也都是DataStream API(bounded/unbounded streams) 和 DataSet API(bounded data sets)
FLink的应用主要包括stream 和 transformation, 当然DataSet也是被当成Stream. 概念上讲, stream指的是一条不会结束的数据记录, transformation所指的操作是把一个或者多个stream作为输入, 生成一个或者多个stream.
所谓的Stream dataflows也是包括streams和transformation操作. 每个dataflow开始于一到多个source, 结束于一到多个sink. 这个过程可以类似的用DAG图来表示, 不过确实通过一些迭代结构允许生成环, 但这种局部特例也可以忽略.
如下图是一个典型的dataflow:
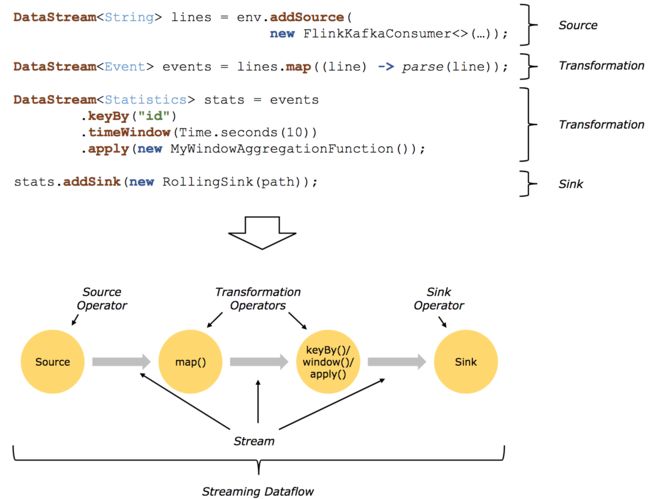
文字来描述的典型步骤的话是:
1 Obtain anexecution environment,
2 Load/create the initial data,
3 Specify transformations on this data,
4 Specify where to put the results of your computations,
5 Trigger the program execution
预定义的Connectors:
data sources: files, directories, sockets, 以及 collections和iterators的输入数据
data sinks: files, stdout, stderr, sockets
目前所支持的与第三方对接的Connectors, 与flink打包在一起的包括:
Apache Kafka(source/sink)
Apache Cassandra(sink)
Amazon Kinesis Streams(source/sink)
Elasticsearch(sink)
Hadoop FileSystem(sink)
RabbitMQ(source/sink)
Apache NiFi(source/sink)
Twitter Streaming API(source)
通过Apache Bahir发布的streaming connectors:
Apache ActiveMQ(source/sink)
Apache Flume(sink)
Redis(sink)
Akka(sink)
Netty(source)
常用的Transformations:
https://ci.apache.org/projects/flink/flink-docs-release-1.4/dev/stream/operators/index.html
1 Map, DataStream --> DataStream
一对一操作, 输入一个元素生成一个元素, 比如每个元素*2
dataStream.map{x => x*2}
2 FlatMap, DataStream --> DataStream
一对多操作, 输入一个元素, 生成0到多个元素, 比如字符串分词, 生成词数组
dataStream.flatMap{ w => w.split(" ")}
3 Filter, DataStream --> DataStream
通过一个bool function对元素进行过滤, 保留为true的元素. 比如过滤为0的元素
datastream.fliter{_ != 0}
4 KeyBy, DataStream --> KeyedStream
通过hash partitioning的方法将一个stream变成一组不想交的patitions, 每个patitions包含的元素具有相同的key. 返回类型为keyedStream, 一组partitions
dataStream.keyBy("someKey")
case class WordWithCount(someKey: String, count: Long)
dataStream.keyBy(0) // Key by the first element of tuple
5 Reduce, KeyedStream --> DataStream
Rolling reduce on a keyed data stream, 标准的reduce, 降维过程,
keyedStream.reduce {_+_}
6 Fold, KeyedStream --> DataStream
滚动折叠, 合并当前元素和上一个被折叠的值, 输入值和返回值可以不一样, 还没有场景用到, 原文: A "rolling" fold on a keyed data stream with an initial value. Combines the current element with the last folded value and emits the new value.A fold function that, when applied on the sequence (1,2,3,4,5), emits the sequence "start-1", "start-1-2", "start-1-2-3", ...
valresult:DataStream[String] = keyedStream.fold("start")((str,i)=>{str+"-"+i})
7 Aggregations, KeyedStream --> DataStream
滚动聚合, 很简单, 一个需要注意的, min返回最小值, minBy返回拥有最小值的元素, 可以是多个
keyedStream.sum(0), keyedStream.sum("key")
keyedStream.min(0), keyedStream.min("key")
keyedStream.max(0), keyedStream.max("key")
keyedStream.minBy(0), keyedStream.minBy("key")
keyedStream.maxBy(0), keyedStream.maxBy("key")
8 Window, KeyedStream --> AllWindowedStream
窗口可以被定义在已经被分区的 KeyedStreams 上。窗口会对数据的每一个 key 根据一些特征(例如,在最近 5 秒中内到达的数据)进行分组。查阅窗口了解关于窗口的完整描述。
dataStream.keyBy(0).window(TumblingEventTimeWindows.of(Time.seconds(5)));// Last 5 seconds of data
9 WindowAll, DataStream --> AllWindowedStream
窗口可以被定义在 DataStream 上。窗口会对所有数据流事件根据一些特征(例如,在最近 5 秒中内到达的数据)进行分组。查阅窗口了解关于窗口的完整描述。
警告:这在许多案例中这是一种非并行的转换。所有的记录都会被聚集到一个执行 WindowAll 操作的 task 中,这是非常影响性能的。
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));// Last 5 seconds of data
10 Window Apply: WindowedStream --> DataStream, AllWindowedStream --> DataStream
应用一个一般的函数到窗口上,窗口中的数据会作为一个整体被计算。下面的函数手工地计算了一个窗口中的元素总和。
注意:如果你正在使用一个 WindowAll 的转换,你需要用 AllWindowFunction 来替换。
windowedStream.apply{WindowFunction}
// applying an AllWindowFunction on non-keyed window streamallWindowedStream.apply{AllWindowFunction}
11 Window Reduce, WindowedStream --> DataStream
应用一个reduce函数到窗口上, 返回reduce的值
12 Window Fold, WindowedStream --> DataStream
应用一个 fold 函数到窗口上,然后返回折叠后的值。 在窗口上将序列 (1,2,3,4,5) 转换成 "start-1", "start-1-2", "start-1-2-3", ... 的一个 fold 函数长这个样子:
valresult:DataStream[String]=windowedStream.fold("start",(str,i)=>{str+"-"+i})
13 Aggregations on windows, WindowedStream -> DataStream
聚合一个窗口中的内容, min 与 minBy 的区别是 min 返回了最小值,而 minBy 返回了在这个字段上是最小值的所有元素(max 和 maxBy 也是同样的)
14 Union, DataStream* --> DataStream
Union 两个或多个数据流,生成一个新的包含了来自所有流的所有数据的数据流。注意:如果你将一个数据流与其自身进行了合并,在结果流中对于每个元素你都会拿到两份。
dataStream.union(otherStream1,otherStream2,...)
15 Window Join, DataStream , DataStream --> DataStream
grades.join(salaries).
where(_.name).equalTo(_.name).
window(TumblingEventTimeWindows.of(Time.milliseconds(windowSize))).
apply { (g,s) =>Person(g.name,g.grade,s.salary) }
16 Window CoGroup: DataStream, DataStream --> DataStream
在一个给定的 key 和窗口上 co-group 两个数据流dataStream.coGroup(otherStream)
.where(0).equalTo(1)
.window(TumblingEventTimeWindows.of(Time.seconds(3)))
.apply(newCoGroupFunction(){...});
17 Connect: DataStream, DataStream --> ConnectedStreams
"连接"两个数据流并保持原先的类型, Connect 可以让两条流之间共享状态.
someStream:DataStream[Int]=...
otherStream:DataStream[String]=...
valconnectedStreams=someStream.connect(otherStream)
18 CoMap, CoFlatMap: ConnectedStreams --> DataStream
在一个 ConnectedStreams 上做类似 map 和 flatMap 的操作
connectedStreams.map(
(_:Int)=>true
,(_:String)=>false)
connectedStreams.flatMap((_:Int)=>true, (_:String)=>false)
19 Split & Select: DataStream --> SplitStream & SplitStream --> DataStream
根据规则把一个stream切分成多个Stream, 并且选择.
针对基于元组的数据流, 可以只选取部分其中部分的字段.
val in:DataStream[(Int,Double,String)] = // [...]
val out = in.project(2,0)