1、Java编码基础
对于Java文件中,是采用的双字节编码utf-16be;
其中,中文占用2个字节,英文占用2个字节;
对于文本文件,实际上就是字节序列;可以是任意编码的字节序列;
如果我们在中文机器上直接创建文本文件,那么该文本文件只认识ANSI编码;对于在该机器上创建的文件,该系统只会认识ANSI编码文件,其他类型编码的会识别成乱码;而对于在其他器件上创建的编码格式复制到该机器上时,该机器是能够识别的;但是如果是直接将文本文件里面的内容复制粘贴到该机器中新建的文件中时,机器会自动进行转换,而不会出现乱码。
utf-8中一个中文占3个字节
gbk中一个中文占2个字节
2、file类中常用的API
java.io.File类用于表示文件(或者 目录);
File类只用于表示文件(目录)的信息(名称、大小等),不能用于文件内容的访问;
file类的构造函数类型;File file=new File("E:\\javaio");或者File file1=new File("e:"+File.separator); 其中,由于Java中“\”表示转义字符,所以要用双斜杠\\来表示文件夹目录,或者用一个“/”也行;另外一种构造方法的File.separator为设置分隔符,无论任何系统,都能够识别该分隔符表示;
判断是否是一个目录或者文件:file.isDirectory();或者file.isFile();
file文件是否存在:file.exists();
如果不存在,则创建该file文件:file.mkdir(); 创建多级目录:file.mkdirs();
删除file文件:file.delete();
当直接打印“file”,则打印的是file.toString()的内容,即目录,而不是file文件内部的内容;此时该方法也可以使用“获取绝对路径”的方法:file.getAbsolutePath();
获取文件的名字:file.getName();获取目录文件最后的目录名;如果是一个文件的名字时,该方法得到的是具体文件的名字;
父目录:file.getParent(); 或者 file.getParentFile();
3、常用函数
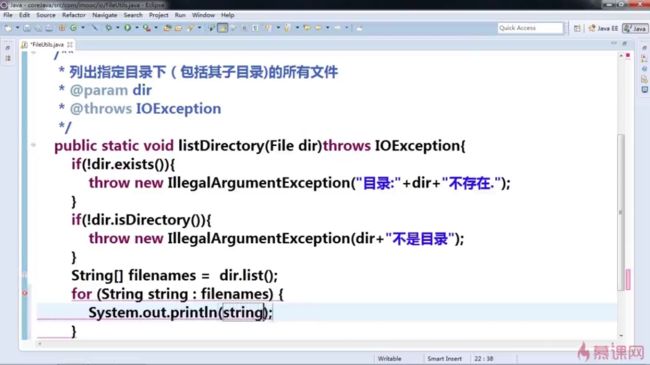
list()方法用于列出当前目录下的子目录和文件,返回的是字符串数组(直接子目录的名称,不包含子目录里面的内容)
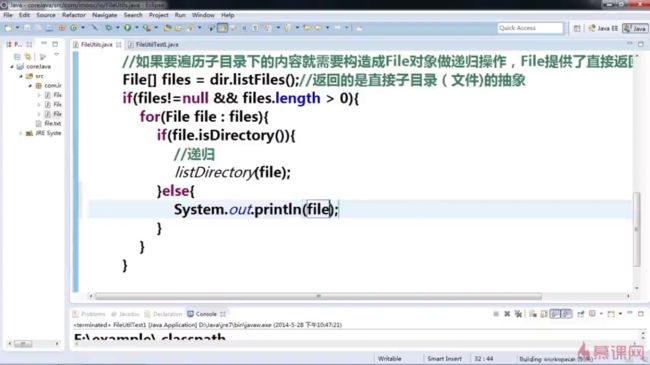
如果要遍历子目录下的内容就需要构造File对象做递归操作,File提供了直接返回File对象的API;File[] files=dir.listFiles();//返回的是直接子目录(文件)的抽象;
4、RandomAccessFile 随机获取文件(对文件的内容进行操作)
是Java提供的对文件内容的访问,既可以读文件,也可以写文件;并且该类型还支持随机访问文件,可以访问文件的任意位置;
1)Java文件模型:在硬盘上的文件是byte byte byte存储的,是数据的集合;
2)打开文件:有两种模式“rw” “r”(只读);
RandomAccessFile raf = new RandomAccessFile(file, "rw");指定要打开的文件,以及读取的方式;
因为是随机访问文件,所以内部还包含有一个文件指针;打开文件时,指针在开始的位置,pointer = 0;
3)写方法:raf.write(int); 内部可以写一个整数或者其他的;write只能写一个字节(后八位),同时指针指向下一个位置,准备再次写入;
4)读方法:int b = raf.read(); 从指针所在的位置开始读一个字节,将该字节转化成整数;
5)文件读写完成以后一定要关闭:
5、IO流(输入流、输出流)
分别有字节流、字符流

《1》字节流
inputstream和outputstream的相关子类
如:
1)FileInputStream:具体实现了在文件上读取数据;
2)FileOutputStream:具体实现了向文件中写出byte数据的方法;
3)DataInputStream / DataOutputStream:是对“流”功能的扩展,可以更加方便地读取int、long、字符等类型数据;
4)DataOutputStream中的方法有:writeInt() / writeDouble() / writeUTF();这些方法实际上是将OutputStream中的方法进行了封装,从而可以直接写出int等类型;
5)BufferedInputStream / BufferedOutputStream:这两个流类为IO提供了带缓冲区的操作,一般打开文件进行写入或读取操作时,都会加上缓冲,这种流模式提高了IO的性能;
对于上述各种IO流的比较:当从应用程序中把输入放入文件中时,相当于将一缸水倒入到另一个缸中:
FileOutputStream中write()方法相当于一滴一滴地把水“转移”过去;
DataOutputStream中的writeXxx()方法会方便一些,相当于一瓢一瓢地把水“转移”过去;
BufferedOutputStream中的write方法更方便,相当于一瓢一瓢地先放入桶中,再从桶中倒入到另一个缸中;
《2》字符流——操作的基本都是文本文件

字符流的基本实现:
InputStreamReader:完成byte流解析为char流,按照编码规则解析;
OutputStreamWriter:提供char流到byte流的编码,按照编码规则处理;
FileReader/ FileWriter:可以直接对文件进行操作;这两个类无法识别其他类型的编码格式,在自己的项目中,只能识别自己的编码格式,所以在编码的时候一定要统一成项目的编码格式;
BufferedReader/ BufferedWriter 字符流的过滤器 每次可以读、写一行readLine();
PrintWriter:向文本输出流打印对象的格式化表示形式,方便打印输出。
《3》对象的序列化和反序列化问题

4)transient 关键字修饰的变量不会进行JVM默认的序列化操作,但是可以自己完成这个元素的序列化;
在某些情况下能够提高性能(不用序列化的就不序列化,需要序列化的自行序列化,从而提高性能);
4)序列化时,当父类实现了序列化接口,则子类也必然是实现了序列化,所以子类不用再实现序列化接口,只用继承父类即可;(子类会递归调用父类的构造函数,无论父类是否实现了序列化接口)
5)反序列化时,当对子类对象进行反序列化操作时,如果其父类没有实现序列化接口,那么其父类的构造函数将被调用;如果父类实现了序列化接口,则该父类的构造函数将看不到被调用,即子类不会递归调用父类的构造函数(调用的前提是该父类没有实现序列化接口);
因为当子类实现了序列化接口时,相当于对于这个子类中的对象已经可以从存储的那个文件中直接读取了,则在反序列化时,就不会调用父类的构造函数;而当子类不能进行序列化时,那么其父类的构造函数会被调用,那么在反序列化时,其父类对象相应地就将会被调用;