
链表
概念
说到链表,coder们都不会陌生,在日常开发中或多或少都会用到它。
它是链式存储的线性表,简称链表。链表由多个链表元素组成,这些元素称为节点。结点之间通过逻辑连接,形成链式存储结构。存储结点的内存单元,可以是连续的也可以是不连续的。逻辑连接与物理存储次序没有关系。
还是多说说概念上的东西,来说说链表的分类,从内存角度出发:链表可以分为静态链表和动态链表,从链表存储方式的角度出发:链表可以分为单链表,双链表以及循环链表。
- 静态链表:把线性表的元素放在数组中,不管物理上是不是连续存放的,它们之间的逻辑关系来连接,数组单位存放链表结点,结点的链域指向下一个元素的位置,也就是下一个元素所在的数组单元的下标。既然需要数组来实现,那么数组的长度是不能预支的。
- 动态链表:克服了静态链表的缺点。它动态地为节点分配存储单元。当有节点插入时,系统动态地为结点分配空间。在结点删除时,应该及时释放相应存储单元,以防止内存泄露。
- 单链表: 单链表是一种顺序存储的结构。
有一个头结点,没有值域,只有连域,专门存放第一个结点的地址。
有一个尾结点,有值域,也有链域,链域始终为NULL.
所以,在单链表中为找第i个结点或数据元素,必须先找到第i-1结点或数据元素,而且必须知道头结点,否则整个链表无法访问。

- 双链表
双链表也是基于单链表的,单链表是单向的。而双链表则在单链表的基础上添加了一个链域。通过两个链域,分别指向结点的前结点和后结点。这样的话可以通过双链表的任何结点访问到它的前结点和后结点。但是双链表还是不够灵活,在实际编程中比较常用的是循环双链表,但是循环双链表比较麻烦。
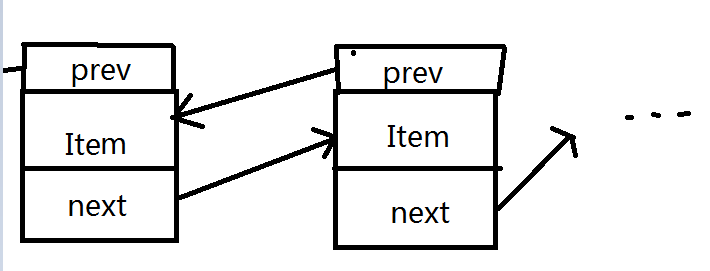
- 循环链接表
循环链表由单链表演化而来。单链表的最后一个结点的链域指向NULL,而循环链表的建立,不要专门的头结点,让最后一个结点的链域指向链表结点。它与单链表的区别:
区别一:链表的建立。单链表需要创建一个头结点,专门存放第一个结点的地址。单链表的链域指向NULL。而循环链表的建立,不要专门的头结点,让最后一个结点的链域指向链表的头结点。
区别二:链表表尾的判断。单链表判断结点是否为表尾结点,只需判断结点的链域值是否是NULL。如果是,则为尾结点;否则不是。而循环链表盘判断是否为尾结点,则是判断该节点的链域是不是指向链表的头结点。
链表的实现
单链表(Single-Linked List)
public class SingleLinkedList {
transient int size = 0;
private Node first;
private class Node {
E item;
Node next;
}
}
插入节点
由于我们SIngleLinkedList类中维护了一个指向FirstNode的引用,所以在表头插入节点是很容易的。
public void insert(E item) {
Node oldFirst = first;
first = new Node<>();
first.item = item;
first.next = oldFirst;
size++;
}
删除节点
/**
* 从头结点开始删除
* @return
*/
public E delete() {
if (first != null) {
E item=first.item;
//让头结点变成原来头结点的下一个结点
first=first.next;
return item;
} else {
throw new NullPointerException("This SingleLinkedList is empty!");
}
}
双向链表(DoubleLinkedList)
双向链表相比与单链表的优势在于它同时支持高效的正向及反向遍历,并且可以方便的在链表尾部删除结点(单链表可以方便的在尾部插入结点,但不支持高效的表尾删除操作)。
public class DoubleLinkedList {
transient int size = 0;
transient Node first;
transient Node last;
private static class Node {
E item;
Node next;
Node prev;
Node(Node prev, E element, Node next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
}
添加节点
public void addFirst(E e) {
Node f = first;
Node newNode = new Node(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
}
public void addLast(E e) {
Node l = last;
Node newNode = new Node(l, e, null);
last = newNode;
if(l==null){
first=newNode;
}else{
l.next=newNode;
}
size++;
}
在指定位置之前添加节点:
public void add(int index, E element) {
if (index < 0 || index > size) {
throw new IndexOutOfBoundsException("index is illegal");
}
if (index == size) {
addLast(element);
}
addBefore(element, node(index));
}
private void addBefore(E element, Node node) {
Node prev = node.prev;
Node newNode = new Node(prev, element, node);
node.prev = newNode;
if (prev == null)
first = newNode;
else
prev.next = newNode;
size++;
}
private Node node(int index) {
if (index < (size >> 1)) {
Node x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node x = last;
for (int i = size - 1; i > index; i++)
x = x.prev;
return x;
}
}
删除操作
private E deleteFirst(Node f) {//删除第一个
E element = f.item;
Node next = f.next;
f.item = null;
f.next = null;
first = next;
if (next == null) {
last = null;
} else {
next.prev = null;
}
size--;
return element;
}
private E deleteLast(Node node) {//删除最后一个
E element = node.item;
Node prev = node.prev;
node.item = null;
node.prev = null;
if (prev == null)
first = null;
else
prev.next = null;
size--;
return element;
}
E delete(Node x) {//删除指定的Node
E element = x.item;
Node next = x.next;
Node prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev=prev;
x.next=null;
}
x.item=null;
size--;
return element;
}
它们使用的地方
public boolean remove(Object o) {
if (o == null) {
for (Node x = first; x != null; x = x.next) {
if (x.item == null) {
delete(x);
return true;
}
}
} else {
for (Node x = first; x != null; x = x.next) {
if (o.equals(x.item)) {
delete(x);
return true;
}
}
}
return false;
}
直接看代码就知道所谓链表到底是怎么一回事了。
链表的特性
1 优点
链表的主要优势有两点:1,插入的时间复杂度为o(1);2,可以动态的改变大小。
2 缺点
由于其链式存储的特性,链表不具备良好的空间局部性,也就是说,链表是一种缓存不友好的数据结构。
LinkedList
java 中LinkedList中的源码中添加删除方法如我在上面写的双链表中的添加删除方法基本一致。
LinkedList是基于双向循环链表实现的(last.next=first,first.prev=last)。
LinkedList是非线程安全的,只在单线程下适合使用。
LinkedList实现了Serializable接口,因此它支持序列化,能够通过序列化传输,实现了Cloneable接口,能被克隆。
除了可以当作链表来操作外,它还可以当作栈,队列和双端队列来使用。
public E poll() {
final Node f = first;
return (f == null) ? null : unlinkFirst(f);
}
public boolean offer(E e) {
return add(e);
}
public void push(E e) {
addFirst(e);
}
public E peek() {
final Node f = first;
return (f == null) ? null : f.item;
}
public E pop() {
return removeFirst();
}
....
从源码可以看出LinkedList不仅有链表的特征方法还是栈和队列的特性方法。
对于LinkedList还有几点要说的。
* 在查找和删除某元素时,源码中都划分为该元素为null和不为null两种情况来处理,LinkedList中允许元素为null。
* LinkedList是基于链表实现的,因此不存在容量不足的问题,所以这里没有扩容的方法。
* 注意源码中的Entry entry(int index)方法。该方法返回双向链表中指定位置处的节点,而链表中是没有下标索引的,要指定位置出的元素,就要遍历该链表,从源码的实现中,我们看到这里有一个加速动作。源码中先将index与长度size的一半比较,如果indexsize/2,就只从位置size往前遍历到位置index处。这样可以减少一部分不必要的遍历,从而提高一定的效率(实际上效率还是很低)。
* LinkedList是基于链表实现的,因此插入删除效率高,查找效率低(虽然有一个加速动作)。
* 要注意源码中还实现了栈和队列的操作方法,因此也可以作为栈、队列和双端队列来使用。
## 一道链表的测试题
这道题来自[剑指offer](https://www.nowcoder.com/ta/coding-interviews?page=)上的一道题:
在一个排序的链表中,存在重复的结点,请删除该链表中重复的结点,重复的结点不保留,返回链表头指针。 例如,链表1->2->3->3->4->4->5 处理后为 1->2->5
public class ListNode {
int val;
ListNode next = null;
ListNode(int val) {
this.val = val;
}
}
public class Solution {
public ListNode deleteDuplication(ListNode pHead)
{
int maxNum = 0;
//int minNum = pHead.val;
//int length = 0;
for (ListNode x = pHead; x != null; x = x.next) {
// length++;
if (x.val > maxNum) {
maxNum = x.val;
}
}
int[] nums = new int[maxNum + 1];
for (ListNode x = pHead; x != null; x = x.next) {
nums[x.val]++;
}
ListNode first = null;
ListNode pFirst=null;
for (int index = 0; index <= maxNum; index++) {
if (nums[index] > 1) {
nums[index] = 0;
}
if (nums[index] > 0 && index > ( first==null?-1:first.val)) {
if (first != null) {
ListNode oldFirst = first;
first = new ListNode(index);
// first.val=index;
oldFirst.next = first;
} else {
first = new ListNode(index);
pFirst = first;
}
}
}
return pFirst;
}
}
这是我写出的一种答案,可能有待精简和优化,时间关系就在这里提供一种解法。等有时间加上注释。