前言
第一步我们配置了hadoop的伪分布式搭建,第二步的过程就是在第一步的基础上进行分布式的搭建。
配置环境
环境:已经搭建好伪分布式hadoop的CentOS6.4
目的
hadoop的集群搭建,一台主节点和三台子节点。
主节点和子节点的主机名由自己设置
(配置是使用的)ip和主机名
192.168.8.10 master
192.168.8.11 node1
192.168.8.12 node2
192.168.8.13 node3
子节点虚拟机的网关与主节点的设置一样,这样可以保证连通。
搭建过程
克隆主机
在我的计算机中,选择待克隆的主机右键->管理->克隆。可以先克隆一台进行设置,在去设置另外两台
选择创建完全克隆

设置虚拟机名称
CentOS的修改设置
修改主机名
打开虚拟机,打开命令提示符,进入root用户
$ vim /etc/sysconfig/network
修改ip
将主机名设置为node1保存退出
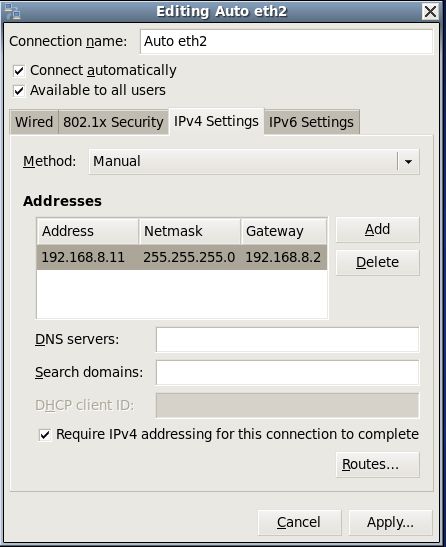
在虚拟机右上角有两个小电脑右键->Edit Connections

先将eth1的ipv4设置为DHCP,或者将eth1直接删除,在设置eth2,将eht2的ip和主节点的ip设置在一个网关下。

关闭防火墙
$ service iptables status #查看防火墙状态
$ service iptables stop #关闭防火墙
$ chkconfig iptables --list #查看防火墙开机启动状态
$ chkconfig iptables off #关闭防火墙开机启动
修改完主机名和ip后重启虚拟机
注:重启虚拟机是为了让新修改主机名生效,同时网卡也从新启动;如果自是修改了ip可以不必重启虚拟机,可以直接使用shell重启网卡
$ service network restart
按照以上方法克隆出另外两台虚拟机(node2和node3),然后修改主机名和ip
修改主节点master主机的hosts
$ vim /etc/hosts
在里面添加三台node的ip与主机名的映射。
192.168.8.10 master
192.168.8.11 node1
192.168.8.12 node2
192.168.8.13 node3
尝试主节点是否能ping通三个子节点,能ping的同说明ip设置正确,ping不通从新检测ip配置
将主节点的hosts文件复制到其它三个子节点
$ scp /etc/hosts node1:/etc/hosts
$ scp /etc/hosts node2:/etc/hosts
$ scp /etc/hosts node3:/etc/hosts
尝试其节点是否能ping通主节点。
子节点的ssh设置
进入.ssh目录
$ cd ~/.ssh
$ ssh-keygen -t rsa #生成`rsa`
$ ssh-copy-id node1 #给node1设设置免秘钥登录
$ ssh-copy-id localhost #也执行一遍
尝试登录自身
$ ssh node1
将生成的ssh公钥cp到其主机,实现免秘钥连接。
$ ssh-copy-id -i ~/.ssh/id_rsa.pub master #cp到主节点
并尝试登录主节点

注:
exit可以退出ssh登录,以上ssh配置在node2,node3中做同样的操作。
三台子节点的公钥都cp到主节点中,我们可以通过查看authorized_keys文件查看结果
$ more authorized_keys

将主机的
authorized_keys文件复制到三个子节点中
$ scp /root/.ssh/authorized_keys node1:/root/.ssh/authorized_keys
$ scp /root/.ssh/authorized_keys node2:/root/.ssh/authorized_keys
$ scp /root/.ssh/authorized_keys node3:/root/.ssh/authorized_keys
相互进行免密钥登录一次,第一次会输入一次密码。
至此子节点centOS配置结束。
hadoop修改
子节点中的hadoop的配置文件不用修改,只需要将tmp文件夹下的文件删除
hadoop的core-site.xml中hadoop.tmp.dir的value值就为tmp文件夹路径


$ rm -rf dfs/
$ rm -rf nm-local-dir
上面是三个子节点hadoop设置,都需要执行
hadoop主节点设置
修改hdfs-site.xml文件
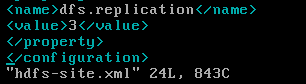
修改
slaver文件
将三个自己的主机名或则ip写入

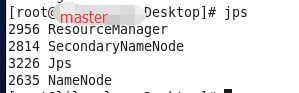
修改完后启动hadoop,查看节点个数
主节点四个服务

查看节点
$ hdfs dfsadmin -report
$ yarn node -list
注: 如果修改slavers文件前以启动hadoop,那么子节点需要单独启动
$ hadoop-daemon.sh start datanode
$ yarn-daemon.sh start nodemanager