这是我学习爬虫的笔记,作为备忘,如果可以帮到大家,那就更好了~
从零开始学爬虫(1):爬取房天下二手房信息
从零开始学爬虫(2):突破限制,分类爬取,获得全部数据
从零开始学爬虫(3):通过MongoDB数据库获取爬虫数据
一、MongoDB数据库是什么
MongoDB是一个基于分布式文件存储的数据库。他支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
一个MongoDB 实例可以包含一组数据库,一个DataBase 可以包含一组Collection(集合),一个集合可以包含一组Document(文档)。一个Document包含一组field(字段),每一个字段都是一个key/value pair。
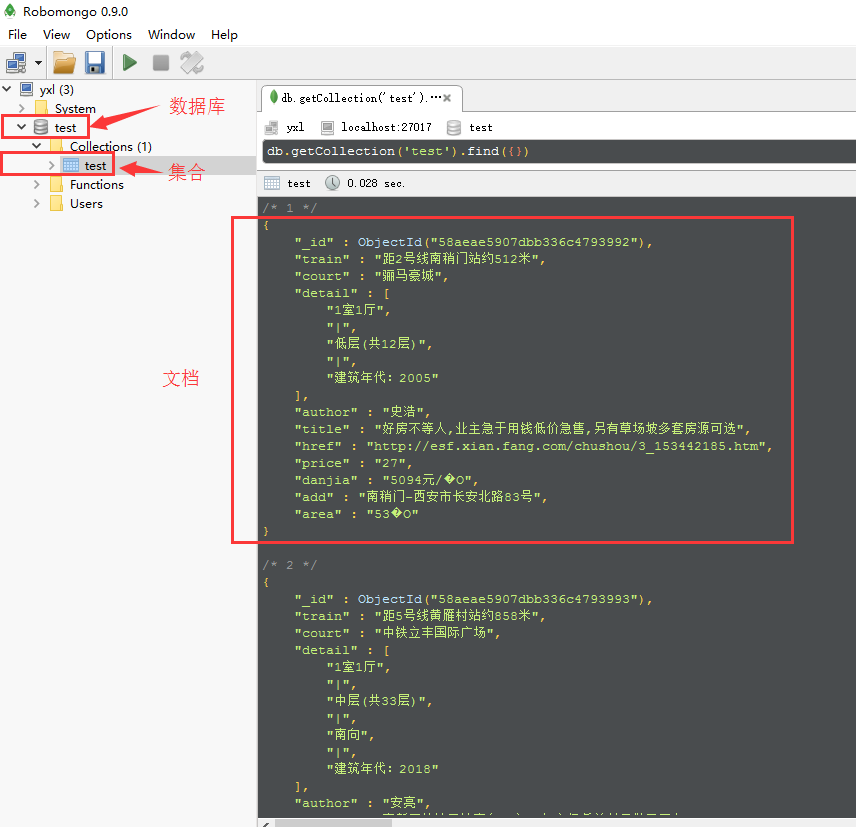
以上是百度百科的介绍,那么所谓的bson格式是什么东西呢?文档是什么样的?集合又是什么呢?下图是我在mongodb可视化管理工具上Robomongo截的图:
 图片.png
图片.png
好了,那我们可以看到一个集合里面有很多个文档,这类似于一个关系型数据库一个表里面有多条记录。
二、MongoDB安装与配置
安装MongoDB数据库
MongoDB数据库安装的详细过程参见 Windows下安装MongoDB
安装MongoDB数据库可视化管理工具Robomongo:直接去官网下载安装即可,下载地址:https://robomongo.org/download
安装Pymongo
以管理员身份打开命令行提示符,执行pip3 install pymongo,即可完成安装。
至此MongoDB数据库的安装与配置就已经完成了。
三、如何通过pymongo操作MongoDB
1、连接数据库
第一步,通过pymongo建立数据库连接,并且连接一个名为test的数据库(如果test不存在,这一步就是新建一个test数据库)
from pymongo import MongoClient
# 建立 MongoDB 数据库连接
conn = MongoClient('localhost', 27017)
# 新建一个test数据库
db = conn.test
2、数据库操作
假设向test数据库中的test集合中插入文档data(data = {"name": "xyl", "age": 25}),只需要一条语句db.test.insert_one(data)就行了;多个文档的插入用db.test.insert_many(data)。
db = conn.test
# 插入一条记录
data = {"name": "xyl", "age": 25}
db.test.insert_one(data)
# 插入多条记录
data = [{"name": "xyl", "age": 25}, {"name": "yxl", "age": 27}]
db.test.insert_many(data)
# 遍历coll = db.test.find()查询到的所有结果,以及它key=name的value
coll = db.test.find()
for i in col1:
print(i)
print(i["name"])
OK,其实MongoDB也是一个数据库,也是可以通过一些语句对其中的数据进行各种操作,这里我们先不深究,有兴趣的可以看一下官方文档。现在,我们来把上一篇文章最后的问题解决一下。
3、二手房信息存储与导出
基于pymongo的常用操作,我们来改写一下上篇文章中的代码(以下是修改后的数据存储的代码)
# -*- coding: utf-8 -*-
from pymongo import MongoClient
from bs4 import BeautifulSoup
import requests
import time
# 建立 MongoDB 数据库连接
conn = MongoClient('localhost', 27017)
# 新建一个test数据库
db = conn.test
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36',
'Cookie': 'global_cookie=gpe9gqaciutsnx2zke6bsyizp29iypii6li; polling_imei=231c34cb02f4f783; SoufunSessionID_Esf=3_1486111884_10590; SKHRecordsXIAN=%25e5%258d%258e%25e8%25bf%259c%25e6%25b5%25b7%25e8%2593%259d%25e5%259f%258e%257c%255e2017%252f2%252f13%2b16%253a13%253a18%257c%255e3610937652%257c%2523%25e6%259d%258e%25e5%25ae%25b6%25e6%259d%2591%25e4%25b8%2587%25e8%25be%25be%25e5%25b9%25bf%25e5%259c%25ba%25e9%259b%2581%25e5%25a1%2594%25e8%25b7%25af%25e6%2596%2587%25e8%2589%25ba%25e8%25b7%25af%25e5%258f%258b%25e8%25b0%258a%25e8%25b7%25af%25e9%2593%2581%25e4%25b8%2580%25e4%25b8%25ad215%25e5%25b9%25b3%25e5%2586%2599%25e5%25ad%2597%25e9%2597%25b4%257c%255e2017%252f2%252f16%2b21%253a41%253a27%257c%255e0; logGuid=1d724a5a-3c98-4e52-8e84-924a7ca9a1ac; __utmt_t0=1; __utmt_t1=1; __utmt_t2=1; city=xian; __utma=147393320.1839238857.1486108289.1487256095.1487298760.22; __utmb=147393320.87.10.1487298760; __utmc=147393320; __utmz=147393320.1486191809.5.3.utmcsr=esf.xian.fang.com|utmccn=(referral)|utmcmd=referral|utmcct=/; unique_cookie=U_6qx5dbebzr1btgohc0anj3f2p16iz97a455*29'
}
def spider_1(url):
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
titles = soup.select('dd > p.title > a') # 标题
hrefs = soup.select('dd > p.title > a') # 链接
details = soup.select('dd > p.mt12') # 建筑信息
courts = soup.select('dd > p:nth-of-type(3) > a') # 小区
adds = soup.select('dd > p:nth-of-type(3) > span') # 地址
areas = soup.select('dd > div.area.alignR > p:nth-of-type(1)') # 面积
prices = soup.select('dd > div.moreInfo > p:nth-of-type(1) > span.price') # 总价
danjias = soup.select('dd > div.moreInfo > p.danjia.alignR.mt5') # 单价
authors = soup.select('dd > p.gray6.mt10 > a') # 发布者
trains = soup.select('dd > div.mt8.clearfix > div.pt4.floatl > span.train.note') # 地铁房
for title, href, detail, court, add, area, price, danjia, author, train in zip(titles, hrefs, details, courts, adds, areas, prices, danjias, authors, trains):
data = {
'title': title.get_text(),
'href': 'http://esf.xian.fang.com' + href.get('href'),
'detail': list(detail.stripped_strings),
'court': court.get_text(),
'add': add.get_text(),
'area': area.get_text(),
'price': price.get_text(),
'danjia': danjia.get_text(),
'author': author.get_text(),
'train': train.get_text()
}
db.test.insert_one(data)
response = requests.get('http://esf.xian.fang.com/', headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
regions = soup.select('#list_D02_10 > div.qxName > a') # 区域
totprices = soup.select('#list_D02_11 > p > a') # 总价
housetypes = soup.select('#list_D02_12 > a') # 户型
areas = soup.select('#list_D02_13 > p > a') # 面积
# 对于大于等于100页的进行细分
n = 1
while n < 8:
i = 1
while i < 7:
resp1 = requests.get('http://esf.xian.fang.com' + regions[n].get('href') + '-' + housetypes[i].get('href')[7:], headers=headers)
soup1 = BeautifulSoup(resp1.text, 'lxml')
pages = soup1.select('#list_D10_01 > span > span') # 页数
if pages and pages[0].get_text().split('/')[1] == '100':
m = 1
while m < 10:
resp1 = requests.get('http://esf.xian.fang.com' + regions[n].get('href') + totprices[m].get('href')[7:-1] + '-' + housetypes[i].get('href')[7:], headers=headers)
soup1 = BeautifulSoup(resp1.text, 'lxml')
pages = soup1.select('#list_D10_01 > span > span') # 页数
if pages and pages[0].get_text().split('/')[1] == '100':
j = 1
while j < 10:
resp1 = requests.get('http://esf.xian.fang.com' + regions[n].get('href') + totprices[m].get('href')[7:-1] + '-' + housetypes[i].get('href')[7:-1] + '-' + areas[j].get('href')[7:], headers=headers)
soup1 = BeautifulSoup(resp1.text, 'lxml')
pages = soup1.select('#list_D10_01 > span > span') # 页数
if pages:
k = int(pages[0].get_text().split('/')[1])
while k > 0:
spider_1('http://esf.xian.fang.com' + regions[n].get('href') + totprices[m].get('href')[7:-1] + '-' + housetypes[i].get('href')[7:-1] + '-' + areas[j].get('href')[7:-1] + '-i3' + str(k))
k = k - 1
time.sleep(2)
else:
pass
j = j + 1
else:
if pages:
k = int(pages[0].get_text().split('/')[1])
while k > 0:
spider_1('http://esf.xian.fang.com' + regions[n].get('href') + totprices[m].get('href')[7:-1] + '-' + housetypes[i].get('href')[7:-1] + '-i3' + str(k))
k = k - 1
time.sleep(2)
else:
pass
m = m + 1
else:
if pages:
k = int(pages[0].get_text().split('/')[1])
while k > 0:
spider_1('http://esf.xian.fang.com' + regions[n].get('href') + housetypes[i].get('href')[7:-1] + '-i3' + str(k))
k = k - 1
time.sleep(2)
else:
pass
i = i + 1
n = n + 3 # 只取1/4/7
这段代码运行的时候我们就可以打开Robomongo去查看当前爬取下来的数据量,它支持三种模式的查看:
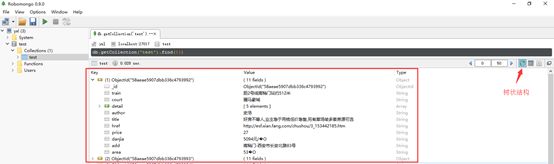

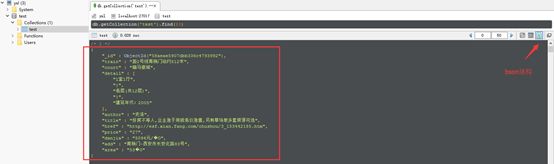
OK,没问题的话就让他一直运行下去,直至把我们需要的数据全部爬下来。虽然MongoDB是一种文件型数据库,但它毕竟不是数据分析工具,接下来,我们需要把这些数据导出为txt、csv、excel等文件类型,方便后续处理。
重写一段专门用来导出已经存储在test数据库test集合中的数据如下:
# -*- coding: utf-8 -*-
from pymongo import MongoClient
# 建立 MongoDB 数据库连接
conn = MongoClient('localhost', 27017)
# 新建一个test数据库
db = conn.test
Myfile = open('D:\ershoufang.txt', 'w', encoding='utf-8')
coll = db.test.find()
k = 1
for i in coll:
# 把字段名写入文件第一行
while k == 1:
m = 1
for j in i:
if m < 11:
Myfile.write(j + "\t")
else:
Myfile.write(j + "\n")
m = m + 1
k = k + 1
# 把字段值写入文件第2到x行
n = 1
for j in i:
if n < 11:
Myfile.write(str(i[j]) + "\t")
else:
Myfile.write(str(i[j]) + "\n")
n = n + 1
注意,在windows下面,新文件的默认编码是gbk,这样的话,python解释器会用gbk编码去解析我们的网络数据流txt,然而txt此时已经是decode过的unicode编码,这样的话就会导致解析不了,出现上述问题。 解决的办法就是,改变目标文件的编码:Myfile = open('D:\ershoufang.txt', 'w', encoding='utf-8')中加上encoding='utf-8'。
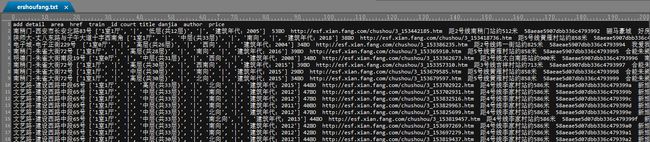
导出以tab分隔的txt数据:
 图片.png
图片.png
四、后记
到现在为止,简单的网页信息爬取和数据存储基本上可以搞定了,剩下的就是数据的整理和分析。
当然,其实在爬取网页信息的过程中我们还遇到一些问题:同一个网页每次爬取到的文档数不同,据了解,应该是因为目标网站有反爬虫策略(ban),对方可以根据你的访问频率和IP判断你是爬虫,而不是正常的浏览。知乎大神介绍了3个常用的防ban的策略:
1、设置随机漫步。访问间隔时间可以设为一个服从正态分布的随机数,模拟人类浏览网页的频率。
2、设置爬虫的工作周期。深更半夜就停止工作,早上就开始工作,尽量模拟人类的作息。
3、搭建集群,分布式爬虫。这样访问的IP会不固定,对方不容易判断出你是爬虫。这个开发成本就相对较高了。推荐NUTCH框架。
作者:淡泊明志
链接:https://www.zhihu.com/question/38123412/answer/75123814
来源:知乎
咱们有空再来研究研究~~~待续