笔者之前写过一篇关于JDK8特性以及基于JDK8的服务端架构设计思想(此文已丢失),如今回头去看,显然当年还是太嫩了,并没有完全明晰函数式编程于服务端架构设计的关联性。但有一个宗旨我觉得还是对的,那就是现下应用开发仍要解决的是数据处理而非过去式的数据存储问题。
0. 思考的起点:阿里闲鱼开源Fish-Redux框架
作为一名混迹于中小型企业的developer,我所构建的大部分应用都是体量偏小的且业务逻辑相对简单。所以虽然我个人比较热衷于探索新技术,但是在此之前构建的工程当中,即使使用React/React Native构建前端或者移动端,但并没有过深的引入redux技术。而后端往往采用MVC结构足以应付。但在以往构建前端react工程或者移动端RN工程当中,我也常常体会到逻辑代码迅速膨胀,以至于失去可维护性,同时也被散碎在各个组件当中的数据(state)维护所困扰。时常想剥离一些高可复用的编程模型,但限于业务和工作的安排,这些想法往往也是最终被冷处理。而在昨天看咸鱼团队的开源直播中,通过大神对于Redux的讲解,让我深受启发。
昨日晚上七点半(2019-03-07),闲鱼团队在钉钉直播平台上,首次讲解其开源的Fish-Redux框架。直播间很热闹,因为作为一个跨平台技术——Flutter本身从诞生之日起就备受期待,更是被冠以未来跨平台解决方案之名。同时,Google团队对Flutter于近期又做了依此更新,让Web前端也可以使用Flutter框架。无论是从目前跨平台(Android/IOS/WP)考虑,还是基于未来快平台(Fuchsia)考虑,无疑都让Flutter成为各个技术团队的重要储备技术之一。而闲鱼的开源框架更是给国内开发者打了一剂强心剂。
1. Fish-Redux框架设计核心思想
要说起Fish-Redux框架,就还是绕不过Flutter框架这个话题。正如闲鱼直播当中所说,目前移动端跨平台的解决方案有三种:
- 基于浏览器的HTML5技术;
- 编译原生代码技术, 例如RN;
-
基于系统C++层次构建的跨平台技术,例如Flutter,其使用的Dart Engine是构建于移动端系统的C++层当中。
 转自闲鱼Flutter应用框架Fish Redux
转自闲鱼Flutter应用框架Fish Redux
Flutter在设计时采用了一个高效的分治策略, 即UI完全组件化(Widgets),再由组件构建Layout/Page,例如一个简单的页面实现
// Flutter 官方给出的一个示例
class MyApp extends StatelessWidget {
@override
Widget build(BuildContext context) {
// Page
return MaterialApp(
title: 'Flutter layout demo',
// App Bar
home: Scaffold(
appBar: AppBar(
title: Text('Flutter layout demo'),
),
// body container
body: Center(
child: Text('Hello World'),
),
),
);
}
}
组件化是现代前端框架的一个设计特点,其主要目的是实现组件逻辑间的解耦,以及提高组件的复用性。而对于状态(state)的维护,Flutter给出了一个设计思想公式

这其实是与React(无Redux)的设计是相似的,我们可以对比来看
class Example extends React.Component{
constructor(props){
super(props);
this.state = {title:"Hello World"}
}
render(){
return(
{ this.state.title}
)
}
}
同样的对于Flutter来说也可以
class MyHomepage extends StatefulWidget {
@override
_MyHomepageState createState() => _MyHomepageState();
}
class _MyHomepageState extends State {
String title = "Hello world";
@override
Widget build(BuildContext context) {
return MaterialApp(
body: Center(
child: Text(title),
),
);
}
}
虽然这样一个分治策略看起来能够解决组件复用性和解耦等问题,但是在实际操作中,由于State的特异性和业务逻辑的复杂性,这种分治策略反而会拖垮我们的架构的简洁,也无法真正的做到复用和解耦。因此,实际工程中,如果采用这种规范,往往使得代码变得不可控制的膨胀,以及代码的重复率大大提升,且往往组件之间的通信问题变得异常复杂甚至不可解。为了解决该问题,Facebook于2014年提出了Flux架构,2015年Redux诞生,将Flux架构与函数式编程进行了整合,使其自身成为前端技术栈当中十分重要的一个架构。其核心思想是构建store来存储包含所有数据的state, view并不能直接修改state数据片段,而是需要从action.creator中创建的action,并由store.dispatch对action进行分发,当store接受到一个action后,他需要变更相应的state数据片段,该过程则由Reducer 来完成。具体可参考阮一峰的系列博客,这里不再赘述。
而Fish-Redux框架的核心就是在Flutter framework层次与Application层次之间,实现了Redux这样一个框架规范。并且在此基础之上,根据dart语言的特点(js对象不需要setter/getter)实现了connector部分,以及为优化帧率问题而抽象出的adapter部分。实现了一个完全由数据驱动的架构方案
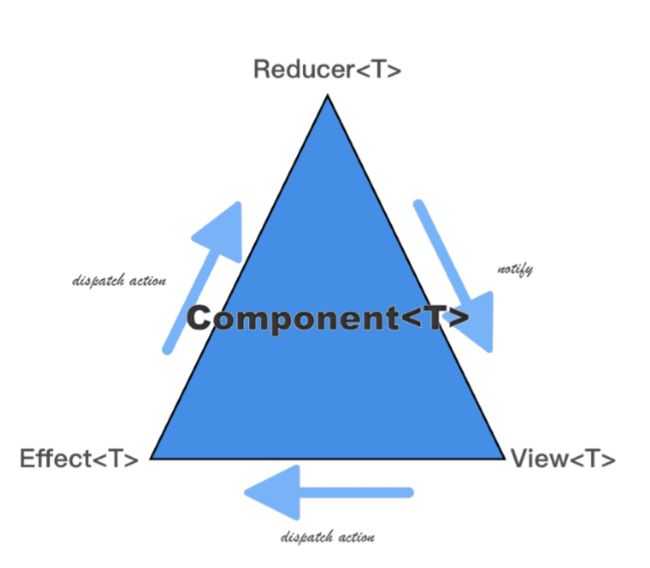
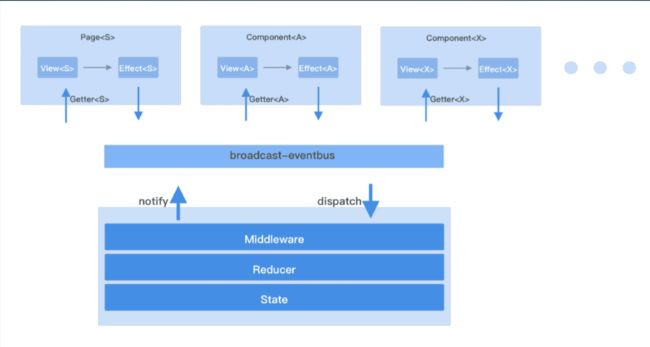
当然,正如闲鱼团队在直播当中所说,他们从众多解决方案中筛选出该方案其目的也是为了迎合业务场景的需求。而其函数编程模型的目的也是为了保证架构的可持续演进。特别是他们提到前端未来可能的NN(神经网络)根据设计草稿生成前端代码的黑盒问题,很有启发性。
2. 存疑:OOP与MVC
OOP在诞生之初,其目的就是能够在低耦合的前提下对代码与数据进行聚合,提高代码的可读性,可维护性和延展性。在我的个人经历中,主要是以java语言来构建服务端应用,当然期间不乏有采用nodejs,python,.Net以及Go语言构建服务端的业务场景。可以说Java是最典型的OOP语言,然而实际业务当中往往有OOP思想不得不被削弱的情况发生,例如多线程情境下
// 这里不考虑线程安全问题
class ThreadExample implements Runnable{
private int exampleResource = 0;
@Override
public void run(){
exampleResource ++;
}
public void main(String...args){
ThreadExample te = new ThreadExample();
new Thread(te).start();
new Thread(te).start();
}
}
在该例子当中,我们构建ThreadExample这样一个类仅仅是为了实现Runnable接口的run方法,并让线程共享exampleResource这样一个资源。而这个类本身并没有很强的OOP聚合概念,也就是说我们为了得到一个run函数而不得不去构建一个对象,其代价不能不说是有些昂贵了。
同样的事情在java以及C#语言技术体系当中并不少见。例如java中采用Spring MVC框架实现MVC三层架构,其Controller和Service往往只是一些函数的聚合,而数据则往往是放在Model中展现的。这就给我们提出了一个问题,我们是不是应该放弃Controller和Service实现过程中采用类的概念聚合代码,而采用函数式编程模型呢?事实上,这个问题的答案应该是肯定的,jdk8 对Function的补充,以及C#混合F#开发的过程中,我们可以看到在这个主要以数据驱动的时代,用函数式编程模型来处理业务逻辑代码的聚合和解耦问题已然是一种趋势。Spring技术栈在5.0版本之后也同样实现了Flux架构。
不过也不得不说,类似Java这种传统的OOP语言,对于实现函数式编程仍有困难,一个典型的例子就是Carrying(科里化),在Java当中实现Carrying会让代码变得异常复杂难懂,其主要原因就是受到泛型的限制。
OOP编程模型思想的削弱,似乎给了函数式编程模型一个铺垫,而如下情景可能更需要函数式编程模型的介入。
3. PaaS/FaaS与无处不在的黑盒
相信很多人对于Container, PaaS以及微服务这些后端技术已经不再陌生。其实这些历史进程不难让我们想到,我们正在以更细小的粒度来拆分我们的业务逻辑。从而提高应用的稳定性和可维护性。FaaS诞生也恰恰符合这样一个历史规律。即函数既是服务的概念。我觉得这一概念的提出,其目的主要有两点:
- 在云服务部署过程当中更具有弹性,(要知道云资源即是成本,所以更好的弹性控制是十分重要的)
- 更为容易控制算力
举一个业务场景的例子,最近在客户的业务当中拆解出了一些NLP(自然语义处理)的需求,这驱使我想去构建一个基于内网服务器进行集中训练神经网络或其他机器模型应用的想法。那么像构建这样一个应用,首先考虑的问题也有两个:
- 算力使用权控制
- 神经网络或机器学习模型可热插拔
所以在设计系统时把Julia实现的机器学习模型看作是本地化的FaaS,而采用java构建一个web应用统一根据时间和算力资源来调度模型的训练过程。如此可见FaaS的概念的必要性。
不过,在细粒度拆分业务时,我们由不得不面临一个问题就是黑盒。当一个复杂的应用在组织这些FaaS时,往往面对的问题,就是时我们并不知道FaaS是如何实现的,当然,我们可以利用OOP数据对Function进行配置以确保黑盒能够对接入我们的系统。而这恰恰是一个数据驱动的例子,该过程可以看为数据(配置)驱动FaaS分发一个Function给我们的系统,而我们的系统则可以根据数据状态来决定是否消费该Fanction。而这个过程恰恰提供给我们一个将黑盒接入系统的策略——数据驱动。
4. 分治策略与数据驱动
最近,客户公司的一个需求是做数据的聚合整理(Grouping),该聚合过程有些特殊,它不同于传统聚合过程构建树形结构的数据,而是由于关联性构建了一个无向图的数据结构,继而对图进行区块划分,以此来聚合数据。
另外值得一提的就是该应用的原始代码已经膨胀的无可救药,很难再进行维护,不夸张的说,轻轻改一行代码,就会毁掉一大片功能,其耦合程度可见一斑。
那么在这样的前提下,我尝试了混合OOP和Function编程模型,其思想就是构建一个无向图的计算引擎,由他装配图的节点和区块数据,而具体的装配过程是通过调度dispatch来根据业务代码的需求配置一个function并分发给计算引擎。而业务代码每次修改数据都会触发dispatch调度function给计算引擎,实现自动组装节点数据和区块数据,最终由计算引擎根据函数配置来给出数据的处理结果,并重新整理数据。
就这样,一个看似复杂的业务逻辑,通过区块和节点的分治策略就给解决了。而且由于function都是可配置的,且由dispatch统一调度,那么该段业务代码的复用性很好。虽然对比传统的MVC结构没有明显的添加业务层次。但是在处理分治过程中,在效率方面确实付出了一定的让步。
不过总而言之,采用以数据驱动业务逻辑,以及采用函数式编程模型,确实给我们解决了一些传统架构上带来的问题。至于效率的优化,在有限的未来中,我相信会有新的技术突破和工具来处理,这也就引出了如下一个话题。
5. 未来与持续演进
总结来说,采用单向数据驱动和分治策略的函数式编程模型可以作为我们未来服务端可持续演进框架的一个思路。而这里我们要立足未来着眼的可能的问题有两点:
- 利用机器学习等非硬编码过程优化分治策略。不同于前端,在服务端进行硬编码时分治策略的目的往往是解决某个数据处理过程的通用性,然而通用性势必导致分治策略执行的效率下降,其可能的一个思路是采用机器学习等非硬编码手段通过搜集和发现数据模式来优化分治策略,继而达到效率优化的效果。
- 单向数据驱动过程中,容纳黑盒服务接入的能力。往往在最初框架设计过程中,我们很难考虑到所有的业务场景,那么框架的可持续演进就显得尤为重要。在单向数据驱动的链路中,我们同样无法为更多黑盒服务预设位置,此时FaaS与应用的函数式编程模型就显得更为优秀,因为我们总可以在业务链路当中随时对黑盒FaaS进行插拔,并同时保证系统的稳定性。
以上,便是我对未来服务端开发思路的一个浅显的理解。希望能与更多相同的朋友交流。