https://github.com/ygidtu/Flask-peewee-datatables上我挂了一个demo
datatables:官网【https://datatables.net/】
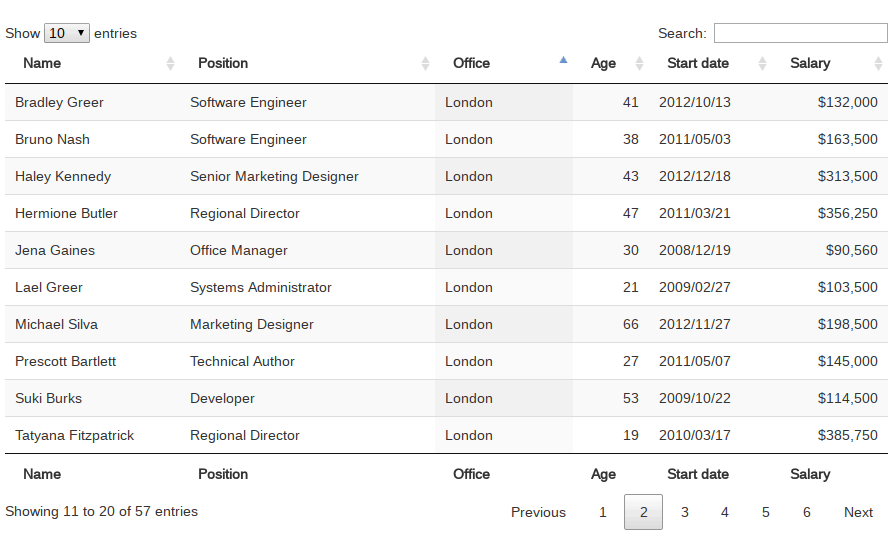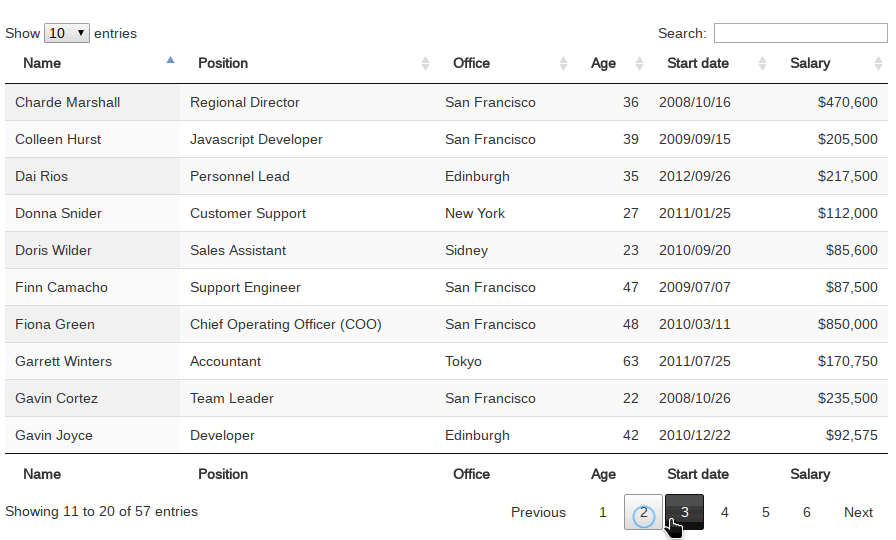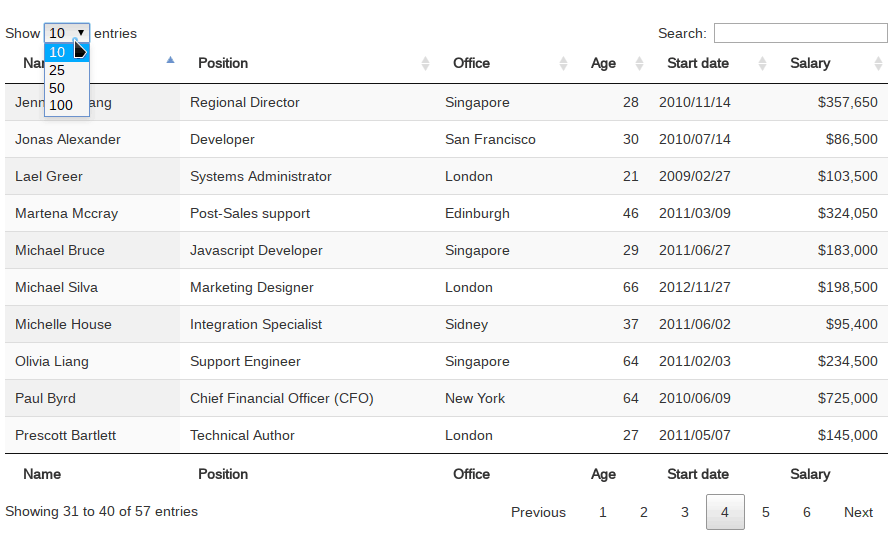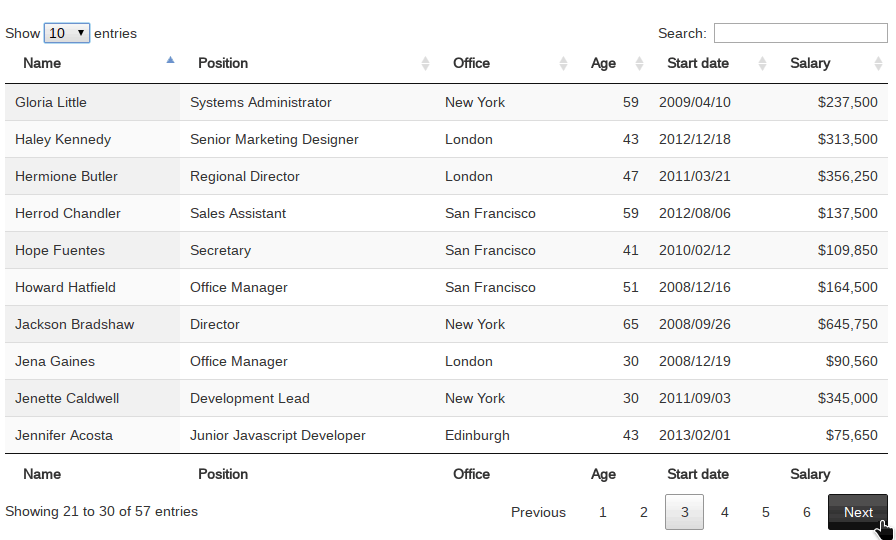
如上图所示,datatables是一个非常好用的js库,方便在网页中展示各种结果
一、安装
Download:https://datatables.net/download/index
我常用两种:
- 下载到本地以static文件的方式引入,但是,除了默认主题,其他的主题会存在图片定位不到的问题
- CDN
二、基础用法
官方最简单的教学:https://datatables.net/examples/basic_init/zero_configuration.html
什么都不加,直接在HTML页面中生成一个table,
id
chrom
start
end
eid
tissue
order
predict
然后直接通过JQuery调用DataTable即可,直接使用
$(document).ready(function() {
$('#tfbs').DataTable( );
} );
当然,各种细节也可以自行调整,具体请自行查询官方文档
三、ajax
当然,这种成熟的JS库当然支持ajax的用法,它需要有特定的ajax格式
所需要的特定的json格式,格式如下:这只是非常基本的格式之一
{
"draw": 1,
"recordsTotal": 57,
"recordsFiltered": 57,
"data": [
[
"Airi",
"Satou",
"Accountant",
"Tokyo",
"28th Nov 08",
"$162,700"
]
}
ajax的JavaScript脚本如下:
$(document).ready(function() {
$('#example').DataTable( {
"processing": true,
"serverSide": true,
"ajax": {
"url": "scripts/jsonp.php",
"dataType": "jsonp"
}
} );
} );
三、Flask的配合问题
现成的Flask的API支持flask-rest、flask-restful和flask-peewee都无法修正为datatables的格式,因此,还是得自己动手丰衣足食
为了能够ajax的交互操作,必须搞清楚datatables是通过何种方式向服务器传递参数的
- 最基础的,datatables会通过在url后附加各种参数来完成数据传递
- 可以自己指定向api借口post数据
1. 拆分url参数
以最开始的例子为例,我开了一个/api/enhancer的接口,默认datatables会通过如下的url获取数据
GET /api/enhancer/?draw=17&columns%5B0%5D%5Bdata%5D=id&columns%5B0%5D%5Bname%5D=&columns%5B0%5D%5Bsearchable%5D=true&columns%5B0%5D%5Borderable%5D=true&columns%5B0%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B0%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B1%5D%5Bdata%5D=chrom&columns%5B1%5D%5Bname%5D=&columns%5B1%5D%5Bsearchable%5D=true&columns%5B1%5D%5Borderable%5D=true&columns%5B1%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B1%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B2%5D%5Bdata%5D=start&columns%5B2%5D%5Bname%5D=&columns%5B2%5D%5Bsearchable%5D=true&columns%5B2%5D%5Borderable%5D=true&columns%5B2%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B2%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B3%5D%5Bdata%5D=end&columns%5B3%5D%5Bname%5D=&columns%5B3%5D%5Bsearchable%5D=true&columns%5B3%5D%5Borderable%5D=true&columns%5B3%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B3%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B4%5D%5Bdata%5D=eid&columns%5B4%5D%5Bname%5D=&columns%5B4%5D%5Bsearchable%5D=true&columns%5B4%5D%5Borderable%5D=true&columns%5B4%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B4%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B5%5D%5Bdata%5D=tissue&columns%5B5%5D%5Bname%5D=&columns%5B5%5D%5Bsearchable%5D=true&columns%5B5%5D%5Borderable%5D=true&columns%5B5%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B5%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B6%5D%5Bdata%5D=order&columns%5B6%5D%5Bname%5D=&columns%5B6%5D%5Bsearchable%5D=true&columns%5B6%5D%5Borderable%5D=true&columns%5B6%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B6%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B7%5D%5Bdata%5D=myself&columns%5B7%5D%5Bname%5D=&columns%5B7%5D%5Bsearchable%5D=true&columns%5B7%5D%5Borderable%5D=true&columns%5B7%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B7%5D%5Bsearch%5D%5Bregex%5D=false&order%5B0%5D%5Bcolumn%5D=5&order%5B0%5D%5Bdir%5D=desc&start=0&length=10&search%5Bvalue%5D=&search%5Bregex%5D=false&_=1510720968919
返回的数据data类,如下:
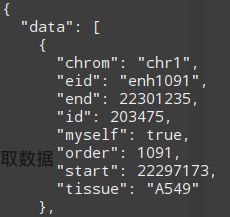
目前,已经拆分出几个参数
- draw:页数,所需第几页的数据
- %5B、%5D:
- 根据Stack OverFlow所讲,分别代表[, ]
- columns%5B0%5D%5Bdata%5D=id:
- 原义为columns[0][data]=id,经过
cprint(get_parameter("columns[0][data]"), 'red')证实,确实如此。这一大段,表明我的表格的第一列使用的是json中key值为id的这一项的数据,
- 原义为columns[0][data]=id,经过
- columns%5B0%5D%5Bname%5D=:
- columns[0][name]=,这一项不是何意,估计是可以该列名
- columns%5B0%5D%5Bsearchable%5D=true:
- columns[0][searchable]=true,能够查询
- columns%5B0%5D%5Borderable%5D=true:
- columns[0][orderable]=true,该列能够排序
- columns%5B0%5D%5Bsearch%5D%5Bvalue%5D=:
- columns[0][search][value]= ,按照什么数据来查询该列
- columns%5B0%5D%5Bsearch%5D%5Bregex%5D=false:
- columns[0][search][regex]=false,该列是否通过正则来匹配
- 然后重复,因此,通过这些调整就将各行各列的所有数据都调整好了
2. 参数的详细用法
首先,将数据只调整到一列,开始解析各个参数的详细用法
order
通过调整order调整到这样一条url
api/enhancer/?draw=1&columns%5B0%5D%5Bdata%5D=id&columns%5B0%5D%5Bname%5D=&columns%5B0%5D%5Bsearchable%5D=true&columns%5B0%5D%5Borderable%5D=true&columns%5B0%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B0%5D%5Bsearch%5D%5Bregex%5D=false&order%5B0%5D%5Bcolumn%5D=0&order%5B0%5D%5Bdir%5D=asc&start=0&length=10&search%5Bvalue%5D=&search%5Bregex%5D=false&_=1510727303124
order%5B0%5D%5Bcolumn%5D=0&order%5B0%5D%5Bdir%5D=asc:
order[column]=0&order[0][dir]=asc或者dir=desc
- draw:第几次向该api发出请求
- order:column指定第几列调整顺序,order[0][dir=asc]或者order[0][dir=desc]指定排序方式
- start=0&length=10,length 代表每一页上有多少数据,start是这一页最开始的那一条是第几条
search
GET /api/enhancer/?draw=13&columns%5B0%5D%5Bdata%5D=id&columns%5B0%5D%5Bname%5D=&columns%5B0%5D%5Bsearchable%5D=true&columns%5B0%5D%5Borderable%5D=true&columns%5B0%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B0%5D%5Bsearch%5D%5Bregex%5D=false&columns%5B1%5D%5Bdata%5D=chrom&columns%5B1%5D%5Bname%5D=&columns%5B1%5D%5Bsearchable%5D=true&columns%5B1%5D%5Borderable%5D=true&columns%5B1%5D%5Bsearch%5D%5Bvalue%5D=&columns%5B1%5D%5Bsearch%5D%5Bregex%5D=false&order%5B0%5D%5Bcolumn%5D=1&order%5B0%5D%5Bdir%5D=asc&start=0&length=10&search%5Bvalue%5D=chr1&search%5Bregex%5D=false&_=1510727522537 HTTP/1.1
不出所料
- search%5Bvalue%5D=chr1
- search[value]=chr1
3. Python配置
通过以上的参数,相信参数的事情就解析清楚了,那么就可以自行动手,设计API来处理这些数据了,我使用的是peewee来处理底层的数据库,因此,写了一个类来处理这个问题
用法已经放在github库上了:https://github.com/ygidtu/Flask-peewee-datatables
#!/usr/bin/env python3
# -*- coding:utf-8 -*-
u"""
serverside的datatables配合flask和peewee使用的方法
"""
import re
from collections import OrderedDict
from flask import request
from peewee import BooleanField
from peewee import IntegerField
from peewee import FloatField
# flask配合datatables使用的类
class WorkWithDataTables(object):
u"""
2017.11.15
开始设计类,想办法自行处理dtatables返回的参数
"""
def __init__(self, table, columns=None, join=None):
u"""
初始化
:param columns: 列表,传入查询的columns, 如果不指定columns,默认使用表中所有的列
:param join: 列表,传入查询的如果需要join表,可以通过这个join指定实现,目前只能join一个表
"""
# 构建
if columns is None:
columns = list(table._meta.fields.values())
if join:
columns += list(join._meta.fields.values())
start = 0
tem = []
for i in columns:
tem.append([start, i])
start += 1
self.columns = OrderedDict(tem)
self.table = table
self.join = join
@staticmethod
def get_parameter(label, default=None):
u"""
:param label: url中指定的参数是
:param default: 如果url中没有这个参数,返回的默认值,一般为None
:return:返回strip之后的参数
"""
tem = request.args.get(label)
if tem is None:
return default
return tem.strip()
def _searchable_(self, index):
u"""
datatables可以通过JavaScript的设置指定某些列可以被查询,某些不可以,
于是变有了这个函数,只有能够被查询的列,我才会查询
"""
if self.get_parameter("columns[%d][searchable]" % index) == "true":
return True
else:
return False
def _set_order_(self):
u"""
根据datatables提交的参数,判定查询结果的排序方式
:return: 返回特定排序方式的peewee Expression语句
"""
# 指定排序方式
order = self.get_parameter("order[0][column]")
order_by = None
if order:
order = int(order)
order_by = self.columns.get(order)
order_dir = self.get_parameter("order[0][dir]")
if order_by and order_dir == "desc":
order_by = order_by.desc()
return order_by
def _set_search_(self):
u"""
根据url参数,设定查询的语句
:return:peewee的查询Expression语句
"""
# 指定查询的值是多少
search = self.get_parameter("search[value]")
# 判断一下输入的是否是boolean值,true、false、yes、no均可,不分大小写
if search is not None:
if re.search(r"^(true|yes)$", search, re.I):
search = True
elif re.search(r"^(false|no)$", search, re.I):
search = False
else:
search = search
#指定查询的peewee Expression语句
search_condition = None
if search: #如果开启search需求
for i in self.columns: # 遍历所有的列,然后分别根据特定情形指定查询语句,目前仅支持bool、float、int
if self._searchable_(i):
# 如果遇到布尔型,需要独特的处理方法
if isinstance(self.columns[i], BooleanField) and\
not isinstance(search, bool):
if search_condition is None:
search_condition = (self.columns[i] == None)
else:
search_condition = (
self.columns[i] == None) | search_condition
continue
# if this column is integer type
if isinstance(self.columns[i], IntegerField):
try:
search = int(search)
if search_condition is None:
search_condition = (self.columns[i] == search)
else:
search_condition = (
self.columns[i] == search
) | search_condition
except:
continue
continue
# if this column is float type
if isinstance(self.columns[i], FloatField):
try:
search = float(search)
if search_condition is None:
search_condition = (self.columns[i] == search)
else:
search_condition = (
self.columns[i] == search
) | search_condition
except:
continue
continue
# 如果符合要求就不用管了,正常处理即可
if search_condition is None:
search_condition = (
self.columns[i].regexp(str(search) + ".*"))
else:
search_condition = (self.columns[i].regexp(
str(search) + ".*")) | search_condition
return search_condition
def query(self, condition=None, search=True, order=None, **kwargs):
u"""
查询语句
:param condition: 外部指定的特定查询要求,peewee Expression
:param search: boolean值,在后期是否能支持datatables的查询框输入值查询
:param order: 指定初始化的顺序,如果不设定,就使用默认顺序
:return:
"""
# 获取参数
page = int(self.get_parameter("start", 1)) / 10 + 1
per_page = int(self.get_parameter("length", 10))
draw = int(self.get_parameter("draw", 1))
querys = self.table.select(*self.columns.values())
if order:
querys = querys.order_by(order)
# 指定非第一次的查询,才会通过这个排序方式排序
if draw > 1:
order = self._set_order_()
querys = querys.order_by(order)
# 如果有外链表,就外链
if self.join:
querys = querys.join(self.join)
# 如果有查询条件或者搜索条件,就分别指定不同的条件
if condition and search:
search_condition = self._set_search_()
if search_condition:
condition = condition & search_condition
elif search:
condition = self._set_search_()
if condition:
querys = querys.where(condition)
# 如果有的表数据量比较大,查询起来特别慢,就可以手动指定一个值,加快速度
if kwargs.get("total") is not None:
total = kwargs["total"]
else:
total = querys.count()
querys = querys.paginate(page, per_page)
# 构建最终的json文件
data = [x for x in querys.dicts()]
return {
"data": data,
"draw": draw,
"start": page,
"length": per_page,
"recordsTotal": total,
"recordsFiltered": total
}