Spark学习
一、Spark简介
- 1.Hadoop中Map-Reduce计算框架的替代品
- 2.运行在HDFS上,可以与Yarn配合
- 3.将中间结果保存在内存而不是磁盘中
- 4.提供了比Map、Reduce更多的高阶函数
- 5.提供了Scala、Python、Java的API以及Scala和Python的shell
二、Spark内置库
- 1.Spark Streaming 流式数据
- 2.SparkSQL JDBC API
- 3.MLlib 机器学习
- 4.GraphX 图
三、RDD
- 弹性分布式数据集
- transform RDD集合 -> RDD集合 变换函数
- action RDD集合 -> 单个值 行动操作
四、使用Spark的方式
- 1.私人机器上安装
- (1) standalone
- (2) with Mesos
- (3) with Yarn
- 2.使用cloudera等公司的虚拟机镜像
- 3.DataBricks
- 4.使用官网提供的脚本在AWS的EC2上构建Spark环境
- *.这里可以下载python2.7,包含大多数常用的科学计算和数据分析库,330M
五、配置Spark环境
| 软件 | 版本 |
|---|---|
| 操作系统 | Mint-16-64bit |
| Hadoop | 2.6.0 |
| Spark | 1.4.0 |
| Scala | 2.11.6 |
| 模式 | Spark on Yarn [Cluster] |
- 1.下载Spark,并解压到目录下
$ tar -xzvf spark-1.4.0.tar.gz
$ sudo chmod 777 -R spark-1.4.0/
$ sudo mv spark-1.4.0/ /usr/
- 2.添加环境变量
$ sudo vi /etc/profile
#添加以下三行
export HADOOP_CONF_DIR=$HADOP_HOME/etc/hadoop
export SPARK_HOME=/usr/spark-1.4.0/
export PATH="$PATH:$SPARK_HOME"
- 3.修改配置文件
$ cd /usr/spark-1.4.0/conf
$ sudo vi slaves
#添加worker节点
node
$ sudo cp log4j.properties.template log4j.properties
$ sudo cp spark-defaults.conf.template spark-defaults.conf
$ sudo vi spark-defaults.conf
#添加以下几行
[
spark.yarn.am.waitTime 10
spark.yarn.submit.file.replication 0
spark.yarn.preserve.staging.files false
spark.yarn.scheduler.heartbeat.interval-ms 5000 spark.yarn.max.executor.failures 6
spark.yarn.historyServer.address node:10020
spark.yarn.executor.memoryOverhead 512
spark.yarn.driver.memoryOverhead 512
]
$ sudo cp spark-env.sh.template spark-env.sh
$ sudo vi spark-env.sh
#添加以下几行
[
export SCALA_HOME=/usr/scala-2.11.6
export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64/
#standalone
SPARK_MASTER_IP=node
SPARK_WORKER_MEMORY=512M
#yarn
export HADOOP_HOME=/usr/hadoop-2.6.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_EXECUTOR_INSTANCES=1
SPARK_EXECUTOR_CORES=1
SPARK_EXECUTOR_MEMORY=256M
SPARK_DRIVER_MEMORY=256M
SPARK_YARN_APP_NAME="Spark 1.4.0"
]
- 4.启动Spark
确认Hadoop已经在运行
$ cd /usr/spark-1.4.0/sbin
$ ./start-all.sh
运行后执行jps命令,应该出现master和worker两个进程
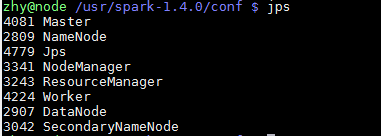
- 5.测试
(1) 运行示例程序
$ cd /usr/spark-1.4.0/bin
$ run-example SparkPi
(2) 以Yarn-Client模型运行示例程序
$ cd /usr/spark-1.4.0/bin
#yarn-cluster模式
spark-submit --class org.apache.spark.examples.JavaSparkPi --master yarn-cluster --driver-memory 256m --executor-memory 256m --executor-cores 1 ../lib/spark-examples-1.4.0-hadoop2.6.0.jar 10
#standalone模式
spark-submit --class org.apache.spark.examples.SparkPi --master local --driver-memory 128m --executor-memory 128m --executor-cores 1 /usr/spark-1.4.0/lib/spark-examples-1.4.0-hadoop2.6.0.jar 10
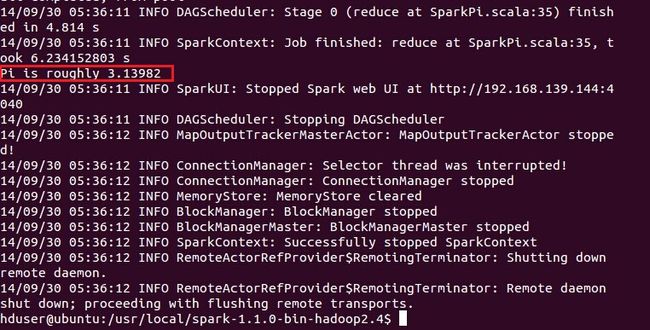
(3) spark-shell测试HDFS和Scala
$ cd /usr/spark-1.4.0/bin
$ spark-shell
# Wordcount for spark
val file=sc.textFile("hdfs://node:8020/tmp/2.txt")
val count=file.flatMap(line=>line.split(" ")).map(word=>(word,1)).reduceByKey(_+_)
count.collect()
count.saveAsTextFile("hdfs://node:8020/output")
(4) 出现的问题
- 1.spark-shell进程经常死掉
错误信息:
./spark-shell: 行 54: 5564 已杀死 "$FWDIR"/bin/spark-submit --class org.apache.spark.repl.Main "$@"
六、配置和使用Spark开发环境
- 1.下载Intellij IDEA14
- 2.下载Scala[插件]for intellij(https://confluence.jetbrains.com/display/SCA/)
- 3.开发环境下安装Scala
- 4.打开Intellij,新建Scala工程,对于依赖包比较简单的工程,选择Non-SBT类型;在工程中建立[Scala class]->[Object],添加Scala.jar和Spark-assembly-hadoop-*.jar包依赖
- 5.确认开发环境所使用的JDK版本与Spark集群相兼容
- 6.打开工程设置,新建[artifact]->[jar from dependencies],选择artifact使用的类,这里可以不将依赖包包含在jar文件中,前提是在Spark集群中设置依赖包的Classpath
- 7.build,并将jar包传输到Spark集群中
- 8.执行
#输入以下命令:standalone模式运行
spark-submit --class Your.Class --master local --driver-memory 128m --executor-memory 128m --executor-cores 1 /path-to/Your.jar
七、Spark读取二进制文件
使用SparkContext的binaryFiles方法读取二进制文件:
源码位于testSpark/loadBinary/loadBinary.java,输入以下命令
#输入以下命令
spark-submit --class main.Scala.loadBinary.loadBinary --master local --driver-memory 128m --executor-memory 128m --executor-cores 1 /home/zhy/spark-app/testSpark.jar
八、Spark + Kafka + Stream
| 软件 | 版本 |
|---|---|
| Kafka | 0.8.2.1-scala-2.11 |
| Zookeeper | 3.4.6 |
- 1.配置Zookeeper
$ tar -zxvf zookeeper-3.4.6.tar.gz
$ sudo mv zookeeper-3.4.6/ /usr/
$ cd /usr/zookeeper-3.4.6/conf
$ cp zoo_sample.cfg zoo.cfg
$ cd /usr/zookeeper-3.4.6/bin
$ ./zkServer.sh start
- 2.配置Kafka
$ tar -zxvf kafka-0.8.2.1.tgz
$ sudo mv kafka-0.8.2.1/ /usr/
$ cd /usr/kafka-0.8.2.1
$ bin/kafka-server-start.sh config/server.properties &
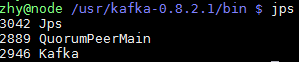
- 3.连接Spark与Kafka
编译后执行下面的们命令:
spark-submit --master local --driver-memory 128m --executor-memory 128m --executor-cores 1 --jars /home/zhy/spark-lib/zkclient-0.5.jar /home/zhy/spark-app/testSpark.jar
错误信息:
ERROR ReceiverTracker: Deregistered receiver for stream 0: Error starting receiver 0 - java.lang.NoSuchMe thodError: scala.Predef$.ArrowAssoc(Ljava/lang/Object;)Ljava/lang/Object;
at kafka.consumer.ZookeeperConsumerConnector.(ZookeeperConsumerConnector.scala:107)
at kafka.consumer.ZookeeperConsumerConnector.(ZookeeperConsumerConnector.scala:143)
at kafka.consumer.Consumer$.create(ConsumerConnector.scala:94)
at org.apache.spark.streaming.kafka.KafkaReceiver.onStart(KafkaInputDStream.scala:100)
at org.apache.spark.streaming.receiver.ReceiverSupervisor.startReceiver(ReceiverSupervisor.scala:125)
at org.apache.spark.streaming.receiver.ReceiverSupervisor.start(ReceiverSupervisor.scala:109)
at org.apache.spark.streaming.scheduler.ReceiverTracker$ReceiverLauncher$$anonfun$8.apply(ReceiverTracker.scala:308 )
at org.apache.spark.streaming.scheduler.ReceiverTracker$ReceiverLauncher$$anonfun$8.apply(ReceiverTracker.scala:300 )
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1765)
at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:1765)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:63)
at org.apache.spark.scheduler.Task.run(Task.scala:70)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:213)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744)
错误信息分析:可能是由于开源组件版本的兼容性问题引起的
九、Spark + Streaming
十、启动Hadoop与Spark集群
- 1.打开虚拟机,并确定虚拟机和主机能够Ping通,主要用来确认虚拟机OS获得了有效的IP地址,其次也保证了主机能够通过SSh登录虚拟机
#1.在虚拟机中输入下面一行命令,以获取虚拟机IP地址
$ ifconfig
#2.在windows中打开Cmd命令行,输入下面一行命令,其中yourIPAddress为ifconfig命令显示的IP地址
$ ping yourIPAddress
#3.确认能够ping通
- 2.使用如下命令修改虚拟机hosts文件与当前IP地址对应
$ ifconfig
$ sudo vi /etc/hosts
#修改172.20.10.4 node这一行为下面引号内的内容(不含引号),其中yourIPAddress为ifconfig命令显示的与主机能够相互ping通的IP地址:
"yourIPAddress node"
- 3.使用如下命令启动
Hadoop:
$ cd /usr/hadoop-2.*.*/sbin
$ ./start-all.sh
- 4.使用如下命令启动
Spark:
$ cd /usr/spark-1.4.0/sbin
$ ./start-all.sh
-
5.使用jps命令确认
Hadoop和Spark启动成功:
jps 6.使用Spark示例确认Spark集群能够工作
#运行示例程序
$ cd /usr/spark-1.4.0/bin
$ run-example SparkPi
#通过spark-submit运行示例程序
$ cd /usr/spark-1.4.0/bin
$ spark-submit --class org.apache.spark.examples.SparkPi --master local --driver-memory 128m --executor-memory 128m --executor-cores 1 /usr/spark-1.4.0/lib/spark-examples-1.4.0-hadoop2.*.*.jar 10
- 7.提交jar命令格式
$ cd /usr/spark-1.4.0/bin
# --class 指定运行的类
# --master 指定运行方式
# --driver-memory 指定为该task分配的driver内存
# --executor-memory 指定为该task分配的executor内存
# --executor-cores 指定为该task分配的executor运行核数
# ***.jar 最后一个参数是jar包的位置,之后的参数都作为task的参数传入
# arg0 arg1 可选 task的参数
$ spark-submit --class YourClass --master local --driver-memory 128m --executor-memory 128m --executor-cores 1 ***.jar arg0 arg1
十一、Client 远程执行Spark任务
对于Windows开发环境,远程执行Spark任务需要以下步骤:
- 1.下载SSH客户端
下载一个Windows的SSH客户端,这里选择的是MobaXterm,其便携版下载地址如下:
[下载地址] -> http://mobaxterm.mobatek.net/MobaXterm_v7.7.zip
下载后解压即可使用,界面是这样的:
- 2.连接Spark集群的Master节点
(1) 在MobaXterm软件中点击左边的Session侧边栏,在"Saved Session"文字上点击右键,在弹出菜单中点击"New Session",进入如下界面:
(2) 点击SSH,在Remote Host中填入节点的IP地址,勾选"specify usernam"并填入用户名,点击"OK"即可。
此时会自动尝试SSH连接,输入密码即可连接成功。下图左边为MobaXterm自带的可视化ftp工具,右边为SSH命令行:
- 3.上传任务所需Jar包
进入ftp中希望上传的文件夹,点击下图红框中的按钮即可选择要上传的文件并上传:
- 4.执行Jar任务
在右边命令行中以类似如下命令格式执行Spark任务:
$ spark-submit --class YourClass --master local --driver-memory 128m --executor-memory 128m --executor-cores 1 ***.jar arg0 arg1