上一篇文章我们着重分析了Task的提交过程,本文中我们将对Task的运行进行详细的分析。
我们从CoarseGrainedExecutorBackend接收到CoarseGrainedSchedulerBackend发过来的LaunchTask消息开始:
case LaunchTask(data) =>
if (executor == null) {
logError("Received LaunchTask command but executor was null")
System.exit(1)
} else {
// 反序列化
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId)
// 调用Executor的launchTask来运行Task
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
接着进入Executor的launchTask方法:
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
// 实例化TaskRunner
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
// 放入ConcurrentHashMap[Long, TaskRunner]的数据结构中
runningTasks.put(taskId, tr)
// 在线程池中运行刚才实例化的TaskRunner,也就是执行其中的run()方法
threadPool.execute(tr)
}
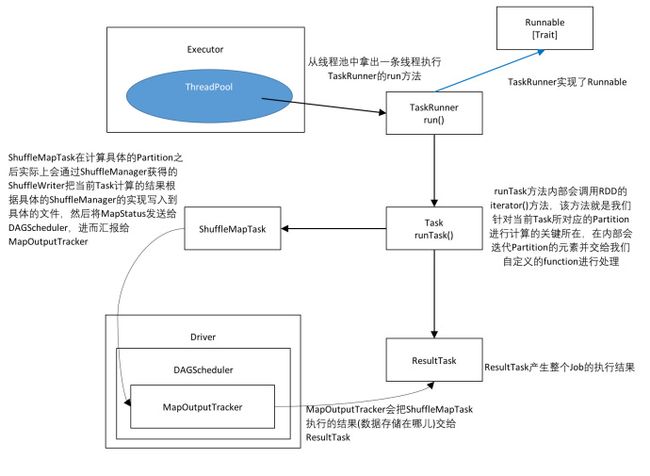
Executor的launchTask方法首先实例化一个TaskRunner(实现了Runnable接口),然后使用线程池中的线程执行实例化的TaskRunner中的run()方法,下面就进入到TaskRunner的run()方法中,为了便于大家阅读我们将该方法分成几个部分:
// 实例化TaskMemoryManager,即内存管理
val taskMemoryManager = new TaskMemoryManager(env.memoryManager, taskId)
// 记录反序列化的开始事件
val deserializeStartTime = System.currentTimeMillis()
// 设置ClassLoader
Thread.currentThread.setContextClassLoader(replClassLoader)
// 序列化器
val ser = env.closureSerializer.newInstance()
// 打印日志信息
logInfo(s"Running $taskName (TID $taskId)")
// 通过ExecutorBackend的statusUpdate方法向Driver发消息,汇报Task的状态为RUNNING状态
execBackend.statusUpdate(taskId, TaskState.RUNNING, EMPTY_BYTE_BUFFER)
var taskStart: Long = 0
// GC事件
startGCTime = computeTotalGcTime()
Driver(DriverEndpoint)接收到消息后的处理不是我们关注的重点,我们聚焦于Task是怎样运行的,继续阅读下面的源码:
try {
// 反序列化成Task的依赖关系,包括taskBytes
val (taskFiles, taskJars, taskBytes) = Task.deserializeWithDependencies(serializedTask)
// 更新依赖关系,也就是下载依赖(文件、jar),下载的时候使用了synchronized关键字
// 因为对于每个Executor中的Tasks而言,这些依赖是共享资源
updateDependencies(taskFiles, taskJars)
// 将taskBytes反序列化成Task
task = ser.deserialize[Task[Any]](taskBytes, Thread.currentThread.getContextClassLoader)
// 设置内存管理器
task.setTaskMemoryManager(taskMemoryManager)
// If this task has been killed before we deserialized it, let's quit now. Otherwise,
// continue executing the task.
if (killed) {
// Throw an exception rather than returning, because returning within a try{} block
// causes a NonLocalReturnControl exception to be thrown. The NonLocalReturnControl
// exception will be caught by the catch block, leading to an incorrect ExceptionFailure
// for the task.
throw new TaskKilledException
}
logDebug("Task " + taskId + "'s epoch is " + task.epoch)
env.mapOutputTracker.updateEpoch(task.epoch)
// 调用task的run()方法来执行任务并获得执行结果
// Run the actual task and measure its runtime.
taskStart = System.currentTimeMillis()
var threwException = true
val (value, accumUpdates) = try {
val res = task.run(
taskAttemptId = taskId,
attemptNumber = attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
} finally {
...
}
...
// 后面是对Task运行完成后返回结果进行的处理
首先就是反序列化依赖关系,关于序列化和反序列化我们会在本文的最统一的进行总结。然后将taskBytes反序列化成Task,最后调用Task的run()方法来执行具体的Task并获得执行结果,后面就是对Task运行完成后返回结果的处理,我们在Task运行完成后再进行分析,接下来我们进入Task的run()方法:
final def run(
taskAttemptId: Long,
attemptNumber: Int,
metricsSystem: MetricsSystem)
: (T, AccumulatorUpdates) = {
context = new TaskContextImpl(
stageId,
partitionId,
taskAttemptId,
attemptNumber,
taskMemoryManager,
metricsSystem,
internalAccumulators,
runningLocally = false)
TaskContext.setTaskContext(context)
context.taskMetrics.setHostname(Utils.localHostName())
context.taskMetrics.setAccumulatorsUpdater(context.collectInternalAccumulators)
taskThread = Thread.currentThread()
if (_killed) {
kill(interruptThread = false)
}
try {
(runTask(context), context.collectAccumulators())
} catch {
...
} finally {
...
}
}
可以看到内部实际上调用的是Task的runTask方法,而根据不同的Task类型运行的就是ShuffleMapTask或者ResultTask的runTask方法,下面我们就分别进行说明:
ShuffleMapTask
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
// 记录反序列化开始的时间
val deserializeStartTime = System.currentTimeMillis()
// 获取序列化/反序列化器
val ser = SparkEnv.get.closureSerializer.newInstance()
// 反序列化RDD及其ShuffleDependency
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
// 计算出反序列化所需要的时间
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
metrics = Some(context.taskMetrics)
var writer: ShuffleWriter[Any, Any] = null
try {
// 获得ShuffleManager,分成Hash和Sort的方式,默认是Sort的方式
// ShuffleManager是在SparkEnv中创建的(包括Driver和Executor)
// Driver使用它注册shuffles,而Executors可以向他读取和写入数据
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
因为Shuffle是影响整个Spark应用程序运行的关键所在,所以关于Shuffle的部分我们会单独用文章分析,现在关心的是Task的具体计算,可以看出最后执行的是RDD的iterator方法,该方法就是我们针对当前Task所对应的Partition进行计算的关键所在,在具体的处理内部会迭代Partition的元素并交给我们自定义的function进行处理。
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
SparkEnv.get.cacheManager.getOrCompute(this, split, context, storageLevel)
} else {
computeOrReadCheckpoint(split, context)
}
}
第一次肯定是没有缓存的,所以直接调用compute,而具体的RDD实现不同的compute逻辑,我们这里以MapPartitionsRDD的compute方法为例:
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
可以清楚的看见直接执行了我们编写的函数f,这里注意第二个参数,同样也是调用的父RDD的iterator方法,这样就将同一个Stage内的函数进行展开计算,形如:
// RDD1
x = 1 + y // 这里的y就可以代表从HDFS中读取的数据
// RDD2
z = x + 3
// 展开之后
z = (1 + y) + 3
// 这里只是打个比方,方便大家理解
ResultTask
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
// 记录反序列化事件
val deserializeStartTime = System.currentTimeMillis()
// 获取序列化/反序列化器
val ser = SparkEnv.get.closureSerializer.newInstance()
// 执行反序列化,和Shuffle不同返回的是RDD和我们编写的业务逻辑
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
metrics = Some(context.taskMetrics)
// 执行我们编写的业务逻辑代码
func(context, rdd.iterator(partition, context))
}
我们再来看ResultTask,和Shuffle不同的是ResultTask会直接产生最后的计算结果。
接下来我们回过头来看一下Task的run()方法对计算结果的处理:
override def run(): Unit = {
...
try {
...
// 记录task运行结束的时间
val taskFinish = System.currentTimeMillis()
// If the task has been killed, let's fail it.
if (task.killed) {
throw new TaskKilledException
}
// 序列化器
val resultSer = env.serializer.newInstance()
// 记录序列化开始时间
val beforeSerialization = System.currentTimeMillis()
// 对返回的结果进行序列化
val valueBytes = resultSer.serialize(value)
// 记录序列化结束的时间
val afterSerialization = System.currentTimeMillis()
// 记录一系列统计信息
for (m <- task.metrics) {
// Deserialization happens in two parts: first, we deserialize a Task object, which
// includes the Partition. Second, Task.run() deserializes the RDD and function to be run
m.setExecutorDeserializeTime(
(taskStart - deserializeStartTime) + task.executorDeserializeTime)
// We need to subtract Task.run()'s deserialization time to avoid double-counting
m.setExecutorRunTime((taskFinish - taskStart) - task.executorDeserializeTime)
m.setJvmGCTime(computeTotalGcTime() - startGCTime)
m.setResultSerializationTime(afterSerialization - beforeSerialization)
m.updateAccumulators()
}
// 使用DirectTaskResult对结果等信息进行封装
val directResult = new DirectTaskResult(valueBytes, accumUpdates, task.metrics.orNull)
// 对DirectTaskResult进行序列化
val serializedDirectResult = ser.serialize(directResult)
// 获取序列化后的大小
val resultSize = serializedDirectResult.limit
// directSend = sending directly back to the driver
val serializedResult: ByteBuffer = {
// 判断序列化后的大小是否大于maxResultSize的限制(默认大小为1GB)
if (maxResultSize > 0 && resultSize > maxResultSize) {
logWarning(s"Finished $taskName (TID $taskId). Result is larger than maxResultSize " +
s"(${Utils.bytesToString(resultSize)} > ${Utils.bytesToString(maxResultSize)}), " +
s"dropping it.")
ser.serialize(new IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize))
// 然后再判断序列化后的大小是否大于等于akkaFrameSize - AkkaUtils.reservedSizeBytes,默认大小为:128MB-200k
} else if (resultSize >= akkaFrameSize - AkkaUtils.reservedSizeBytes) {
// 获得blockId
val blockId = TaskResultBlockId(taskId)
// 通过blockManager写入,这里是存储级别是MEMORY_AND_DISK_SER
env.blockManager.putBytes(
blockId, serializedDirectResult, StorageLevel.MEMORY_AND_DISK_SER)
logInfo(
s"Finished $taskName (TID $taskId). $resultSize bytes result sent via BlockManager)")
// 序列化
ser.serialize(new IndirectTaskResult[Any](blockId, resultSize))
} else {
logInfo(s"Finished $taskName (TID $taskId). $resultSize bytes result sent to driver")
// 不经过BlockManager,直接返回序列化后的结果
serializedDirectResult
}
}
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)
} catch {
...
} finally {
runningTasks.remove(taskId)
}
}
具体的结果(serializedResult)需要通过判断序列化后的大小resultSize来决定:
- 如果resultSize的大于maxResultSize(通过“spark.driver.maxResultSize”进行配置),同时保证maxResultSize的值是大于0的,那么返回的就是对IndirectTaskResult[Any](TaskResultBlockId(taskId), resultSize)序列化后的结果,并打下Warning日志
- 如果resultSize的小于等于maxResultSize并且大于等于128MB-200k,就通过BlockManager进行存储,存储的级别为MEMORY_AND_DISK_SER,并且最后对封装的IndirectTaskResult进行序列化后的结果
- 如果resultSize的大小小于128MB-200k,则直接返回序列化后的结果
最后通过调用ExecutorBackend(Standalone下就是CoarseGrainedExecutorBackend)的statusUpdate方法将结果返回给DriverEndpoint,具体就是CoarseGrainedExecutorBackend向DriverEndpoint发送StatusUpdate来传输执行结果:
override def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer) {
// 将信息封装成StatusUpdate
val msg = StatusUpdate(executorId, taskId, state, data)
driver match {
case Some(driverRef) => driverRef.send(msg)
case None => logWarning(s"Drop $msg because has not yet connected to driver")
}
}
DriverEndpoint在接收到statusUpdate消息后进行的操作:
case StatusUpdate(executorId, taskId, state, data) =>
// 首先调用TaskSchedulerImpl的statusUpdate方法
scheduler.statusUpdate(taskId, state, data.value)
// 下面就是释放并重新分配刚才Task使用的计算资源
if (TaskState.isFinished(state)) {
executorDataMap.get(executorId) match {
case Some(executorInfo) =>
executorInfo.freeCores += scheduler.CPUS_PER_TASK
makeOffers(executorId)
case None =>
// Ignoring the update since we don't know about the executor.
logWarning(s"Ignored task status update ($taskId state $state) " +
s"from unknown executor with ID $executorId")
}
}
上面的操作分成两步:首先调用TaskSchedulerImpl的statusUpdate方法;然后就是释放并重新分配刚才Task使用的计算资源,我们直接进入TaskSchedulerImpl的statusUpdate方法:
def statusUpdate(tid: Long, state: TaskState, serializedData: ByteBuffer) {
var failedExecutor: Option[String] = None
synchronized {
try {
if (state == TaskState.LOST && taskIdToExecutorId.contains(tid)) {
// We lost this entire executor, so remember that it's gone
val execId = taskIdToExecutorId(tid)
if (executorIdToTaskCount.contains(execId)) {
removeExecutor(execId,
SlaveLost(s"Task $tid was lost, so marking the executor as lost as well."))
failedExecutor = Some(execId)
}
}
taskIdToTaskSetManager.get(tid) match {
case Some(taskSet) =>
if (TaskState.isFinished(state)) {
taskIdToTaskSetManager.remove(tid)
taskIdToExecutorId.remove(tid).foreach { execId =>
if (executorIdToTaskCount.contains(execId)) {
executorIdToTaskCount(execId) -= 1
}
}
}
if (state == TaskState.FINISHED) {
taskSet.removeRunningTask(tid)
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
} else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) {
taskSet.removeRunningTask(tid)
taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData)
}
case None =>
logError(
("Ignoring update with state %s for TID %s because its task set is gone (this is " +
"likely the result of receiving duplicate task finished status updates)")
.format(state, tid))
}
} catch {
case e: Exception => logError("Exception in statusUpdate", e)
}
}
// 防止产生死锁
// Update the DAGScheduler without holding a lock on this, since that can deadlock
if (failedExecutor.isDefined) {
dagScheduler.executorLost(failedExecutor.get)
backend.reviveOffers()
}
}
上面的源码中最主要的部分就是使用TaskResultGetter来处理Successful或是FailedTask,即分别调用了TaskResultGetter的enqueueSuccessfulTask方法和enqueueFailedTask方法,我们现在关注的是Task执行成功的情况(对于失败的情况简单来说就是进行重试),所以我们进入TaskResultGetter的enqueueSuccessfulTask方法:(注意下面只选取了主要的部分)
// 对结果进行了反序列化处理
val (result, size) = serializer.get().deserialize[TaskResult[_]](serializedData) match {
// 下面就是匹配受到结果的类型,进而进行不同的处理
case directResult: DirectTaskResult[_] =>
if (!taskSetManager.canFetchMoreResults(serializedData.limit())) {
return
}
// deserialize "value" without holding any lock so that it won't block other threads.
// We should call it here, so that when it's called again in
// "TaskSetManager.handleSuccessfulTask", it does not need to deserialize the value.
directResult.value()
(directResult, serializedData.limit())
case IndirectTaskResult(blockId, size) =>
if (!taskSetManager.canFetchMoreResults(size)) {
// dropped by executor if size is larger than maxResultSize
sparkEnv.blockManager.master.removeBlock(blockId)
return
}
logDebug("Fetching indirect task result for TID %s".format(tid))
scheduler.handleTaskGettingResult(taskSetManager, tid)
val serializedTaskResult = sparkEnv.blockManager.getRemoteBytes(blockId)
if (!serializedTaskResult.isDefined) {
/* We won't be able to get the task result if the machine that ran the task failed
* between when the task ended and when we tried to fetch the result, or if the
* block manager had to flush the result. */
scheduler.handleFailedTask(
taskSetManager, tid, TaskState.FINISHED, TaskResultLost)
return
}
val deserializedResult = serializer.get().deserialize[DirectTaskResult[_]](
serializedTaskResult.get)
sparkEnv.blockManager.master.removeBlock(blockId)
(deserializedResult, size)
}
// 使用统计系统记录ResultSize
result.metrics.setResultSize(size)
scheduler.handleSuccessfulTask(taskSetManager, tid, result)
具体就是根据发过来的结果的类型进行模式匹配,然后分情况进行处理:
如果接收到的是DirectTaskResult类型的数据,也就是说序列化后的大小小于128MB-200k的话,就返回(directResult, serializedData.limit())给(result, size);
如果接收到的是IndirectTaskResult,且序列化后的大小大于1GB的话,就dropped掉,否则就通过BlockManager获取上面使用BlcokManager存储的数据,然后进行反序列化处理,处理完成后返回(deserializedResult, size)给(result, size)。
最后调用TaskSchedulerImpl的handleSuccessfulTask方法:
def handleSuccessfulTask(
taskSetManager: TaskSetManager,
tid: Long,
taskResult: DirectTaskResult[_]): Unit = synchronized {
taskSetManager.handleSuccessfulTask(tid, taskResult)
}
进而调用TaskSetManager的handleSuccessfulTask方法:
def handleSuccessfulTask(tid: Long, result: DirectTaskResult[_]): Unit = {
...
sched.dagScheduler.taskEnded(
tasks(index), Success, result.value(), result.accumUpdates, info, result.metrics)
...
}
最主要的就是调用DAGScheduler的taskEnded方法:
def taskEnded(
task: Task[_],
reason: TaskEndReason,
result: Any,
accumUpdates: Map[Long, Any],
taskInfo: TaskInfo,
taskMetrics: TaskMetrics): Unit = {
eventProcessLoop.post(
CompletionEvent(task, reason, result, accumUpdates, taskInfo, taskMetrics))
}
通过eventProcessLoop.post将CompletionEvent加入到消息队列中,我们直接看DAGScheduler对该消息的处理:
case completion @ CompletionEvent(task, reason, _, _, taskInfo, taskMetrics) =>
dagScheduler.handleTaskCompletion(completion)
至此我们就不再往下追踪了,感兴趣的朋友可以继续追踪下去,接下来的文章我们开始对Shuffle部分进行细致的分析。
使用一张图来简单的概括一下上面的流程:
补充:Task的序列化和反序列化的总结:
序列化:
1、对RDD及其ShuffleDependency的序列化:
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef).array()
case stage: ResultStage =>
closureSerializer.serialize((stage.rdd, stage.func): AnyRef).array()
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
2、TaskSetManager:对Task依赖关系的序列化
val serializedTask: ByteBuffer = try {
Task.serializeWithDependencies(task, sched.sc.addedFiles, sched.sc.addedJars, ser)
} catch {
序列化完成后封装成TaskDescription:
return Some(new TaskDescription(taskId = taskId, attemptNumber = attemptNum, execId,
taskName, index, serializedTask))
3、CoarseGrainedSchedulerBackend中的DriverEndpoint:对TaskDescription的序列化:
// Launch tasks returned by a set of resource offers
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = ser.serialize(task)
反序列化:
1、CoarseGrainedExecutorBackend接收到LaunchTask消息后:反序列化成TaskDescription
case LaunchTask(data) =>
if (executor == null) {
logError("Received LaunchTask command but executor was null")
System.exit(1)
} else {
val taskDesc = ser.deserialize[TaskDescription](data.value)
2、Executor在使用线程池中的线程运行TaskRunner的run()方法的时候:反序列化依赖关系
try {
val (taskFiles, taskJars, taskBytes) = Task.deserializeWithDependencies(serializedTask)
3、Executor在使用线程池中的线程运行TaskRunner的run()方法的时候:反序列化成Task
task = ser.deserialize[Task[Any]](taskBytes, Thread.currentThread.getContextClassLoader)
4、ShuffleMapTask或者ResultTask在执行runTask()方法的时候:反序列化RDD及其ShuffleDependency
ShuffleMapTask:
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
ResultTask:
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
本文参照的是Spark 1.6.3版本的源码,同时给出Spark 2.1.0版本的连接:
Spark 1.6.3 源码
Spark 2.1.0 源码
本文为原创,欢迎转载,转载请注明出处、作者,谢谢!