在使用Solr来解析docx的时候报错:
java.lang.ClassNotFoundException: solr.extraction.ExtractingRequestHandler
需要修改solr (core)里的solrconfig.xml中
将solr6部署到tomcat并启动后使用post工具将一些文档添加到solr服务器出现以下提示:
Caused by: java.lang.ClassNotFoundException: solr.extraction.ExtractingRequestHandler
提示没有找到ExtractingRequestHandler,到底是什么原因导致这个问题呢,下面讲解以下如何解类似的问题,这个可以通过查看solr服务器的logging模块给出的提示解决:
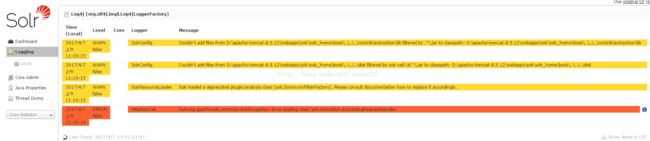
需要注意的是下面这句:
SolrConfig
Couldn't add files from D:\apache-tomcat-8.5.12\webapps\solr\solr_home\book\..\..\..\contrib\extraction\lib filtered by .*\.jar to classpath: D:\apache-tomcat-8.5.12\webapps\solr\solr_home\book\..\..\..\contrib\extraction\lib
这说明solrconfig.xml中配置的solr 插件位置不对,具体配置为:
具体目录为contrib/extraction/lib之类插件目录相对于solr core实例目录的相对位置!
解析的文本无论如何查询不到:
log里有
name=/update/extract, class=solr.extraction.ExtractingRequestHandler},args = {defaults={lowernames=true,uprefix=ignored_,captureAttr=true,fmap.a=links,fmap.div=ignored_,df=text}}}
问题出在:uprefix=ignored_,意思是通过Tika解析的不能决定的字段忽略掉。
最后使用解决为:
删除掉uprefix,而改成:defaultField的配置将无法确定的字段放到特定字段中。
https://wiki.apache.org/solr/ExtractingRequestHandler
fmap.= - Maps (moves) one field name to another. Example:fmap.content=textwill cause the content field normally generated by Tika to be moved to the "text" field.
boost.= - Boost the specified field.
literal.= - Create a field with the specified value. May be multivalued if the Field is multivalued.
uprefix= - Prefix all fields that are not defined in the schema with the given prefix. This is very useful when combined with dynamic field definitions. Example:uprefix=ignored_would effectively ignore all unknown fields generated by Tika given the example schema contains
defaultField= - If uprefix is not specified and a Field cannot be determined, the default field will be used.
extractOnly=true|false - Default is false. If true, return the extracted content from Tika without indexing the document. This literally includes the extracted XHTML as a string in the response. When viewing manually, it may be useful to use a response format other than XML to aid in viewing the embedded XHTML tags. SeeTikaExtractOnlyExampleOutput.
resource.name= - The optional name of the file. Tika can use it as a hint for detecting mime type.
capture= - Capture XHTML elements with the name separately for adding to the Solr document. This can be useful for grabbing chunks of the XHTML into a separate field. For instance, it could be used to grab paragraphs (
) and index them into a separate field. Note that content is also still captured into the overall "content" field.
captureAttr=true|false - Index attributes of the Tika XHTML elements into separate fields, named after the element. For example, when extracting from HTML, Tika can return the href attributes in tags as fields named "a". See the examples below.
xpath= - When extracting, only return Tika XHTML content that satisfies the XPath expression. Seehttp://tika.apache.org/1.2/parser.htmlfor details on the format of Tika XHTML. See alsoTikaExtractOnlyExampleOutput.
lowernames=true|false - Map all field names to lowercase with underscores. For example, Content-Type would be mapped to content_type.
literalsOverride=true|false -
Solr4.0When true, literal field values will override other values with same field name, such as metadata and content. If false, then literal field values will be appended to any extracted data from Tika, and the resulting field needs to be multi valued. Default: true
resource.password= -
Solr4.0The optional password for a password protected PDF or OOXML file. File format support depends on Tika.
passwordsFile= -
Solr4.0The optional name of a file containing file name pattern to password mappings. See chapter "Encrypted Files" below