0x00 前言
- 你想知道背单词软件有大概多少人注册第一天都没有背完嘛?
- 你想知道背单词软件这么火,这么多人在使用,真的有多少人真的在背诵嘛?
别急,Python程序员用数据给你说话.
文章目录如下:
- 0x00 前言
- 0x01 问题的提出和任务的分解
- 0x02 任务一,信息爬取
- ox03 任务二,清理和存储
- 0x04 任务三,分析
- 0x05 任务四,结论
- 0x06 整个流程的不足和反思.
- 0x07 代码.
0x01 问题的提出和任务的分解
前两天,就在一个雷电交加的夜晚,我躺在床上,草草的看了一篇英文文章,突然想到一个非常有意思的问题:
是不是大部分的人做事真的不能坚持呢?比如,背单词.
好,那我就看看到底有多少人是坚持不下来的?
那么,我们的问题就变成了这样子:
- 有多少人是在坚持或者曾经坚持过背单词呢?(假设100天以上算的上是背单词的话)
- 有多少梦想,毁于不能坚持?
- 背单词的人们学习的量,是不是符合正太分布呢?
于是我选中了业内的标杆扇贝软件作为分析的对象.抽取其中的大约1/30的用户的公开数据,也就是游客用户都可以看得到的数据,进行抽样调查.
调查的具体内容如下:
- 打卡最高/成长值最高/学习单词数量最高
- 平均每个人打卡次数/成长值/学习单词数量
- 打卡/成长值/学习单词数量的分布(也就是已经坚持了多少天了)
那么,我的任务也就可以分解如下:
- 爬取数据
- 使用Python2的Scrapy进行爬站
- 清理数据
- sql语句和pandas运算
- 分析数据
- pandas + seaborn + ipython book
- 得出结论
0x02 任务一,信息爬取,清理和存储
每个用户的信息都在这里:
http://www.shanbay.com/bdc/review/progress/2
使用beautifulsoup4 进行解析即可.其他部分参考代码.
扇贝的工程师反爬虫做的还不错,主要有两点:
- 访问数量超标,封禁IP半个小时.对应的方法就是代理服务器.(代码中已经删除代理服务器,所以,如果你运行不了代码,那你应该知道怎么做了.)
- cookie如果不禁用很快就无法爬取.对应的方法就是禁用Cookie.
0x03 任务二,清理和存储
对于数据库,使用Postgresql存储就好了.也没有什么大问题.参考代码.有问题在评论下面问.
通常情况下在存入数据库的时候需要进行数据的净化,不处理也没有什么大问题.
0x04 任务三,分析
分析阶段,使用IPython notebook. 通常情况下,我们使用的是Anaconda里面的Python3版本 .可以到这里下载,注意,mac和ubuntu下载的是命令行版本.
https://www.continuum.io/downloads
安装完毕以后,重启终端.环境变量生效.
#直接安装seaborn
pip install seaborn
切换到指定目录然后敲入命令ipython notebook打开浏览器进行编辑.
至于怎么使用,请看代码.
0x05 任务三,结论
在这里省去部分的分析过程直接贴出结论.
总共抓取1111111张网页,成功获取610888个用户的信息.
于是得出结论如下:
扇贝之最:
- 最高打卡天数: chainyu 1830天
- 最高成长值: Lerystal 成长值 28767
- 最高单词数量: chenmaoboss 单词量 38313
平均到每一个人身上
- 平均每人打卡天数: 14.18,而超过成长平均值的人数为71342,占总抽样人数的,额,11.69%
- 平均成长值: 121.79,而超过平均成长的人数为13351,占总抽样人数的,额,11.42%
- 平均学习单词数量: 78.92,而背超过平均单词的人数为13351,占总抽样人数的,额,2.19%(注意,真的是2%左右)
那么,我们来看看打卡,成长值,单词数量的,分布吧.
第一个,所有人的打卡数量直方图.
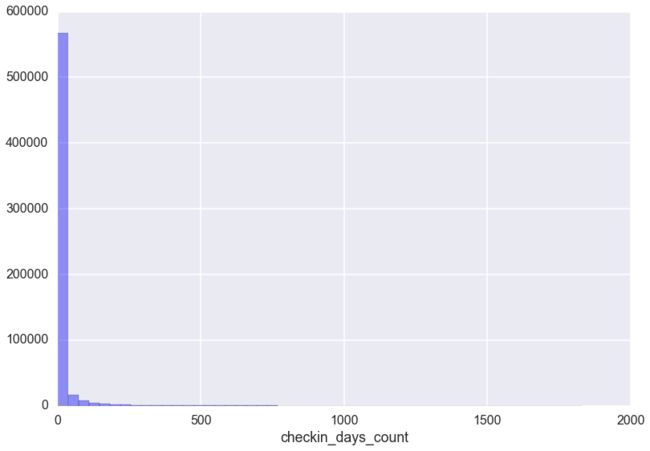
简直惨不忍睹.
第二个,非零用户的打卡数量直方图.
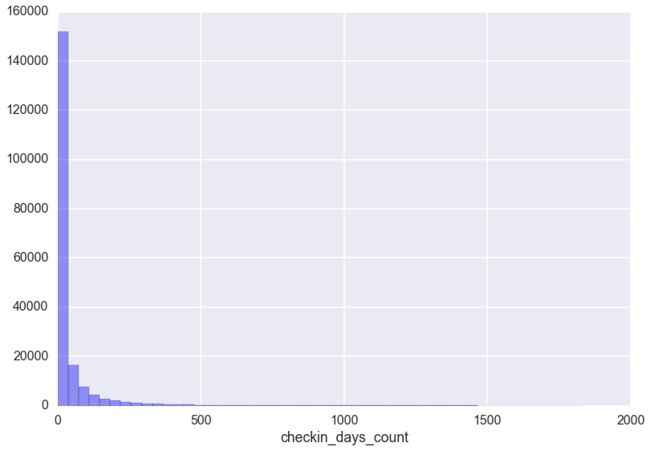
这真是一段悲伤的故事.由于坚持不了几天的用户实在是太多,简直就是反比例函数嘛,导致图像严重畸形.那么,我们只能分段了看用户打卡天数在020,20100,100500,5002000范围的分布图了.
分别如下:
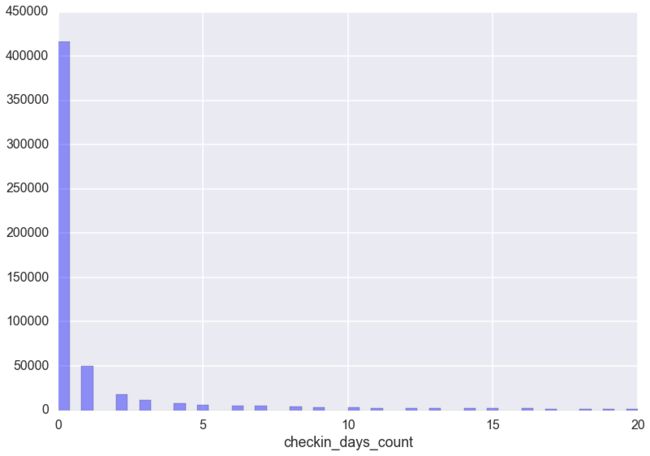
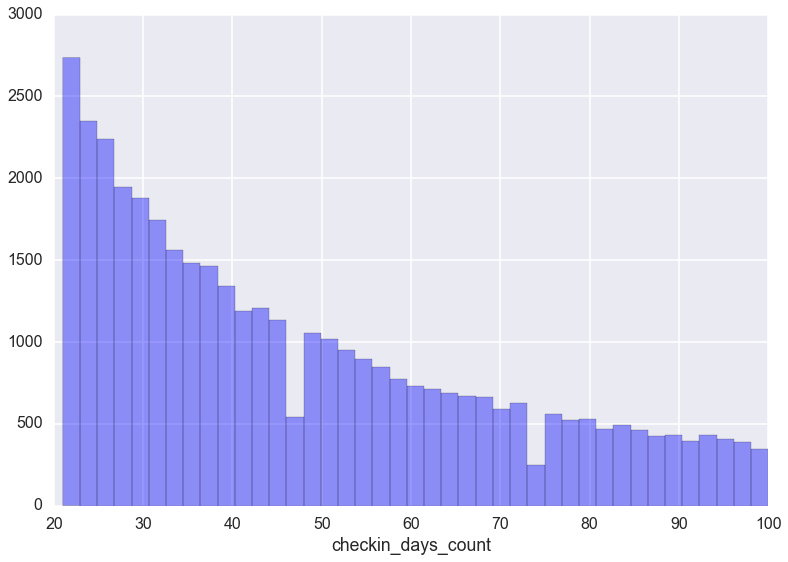
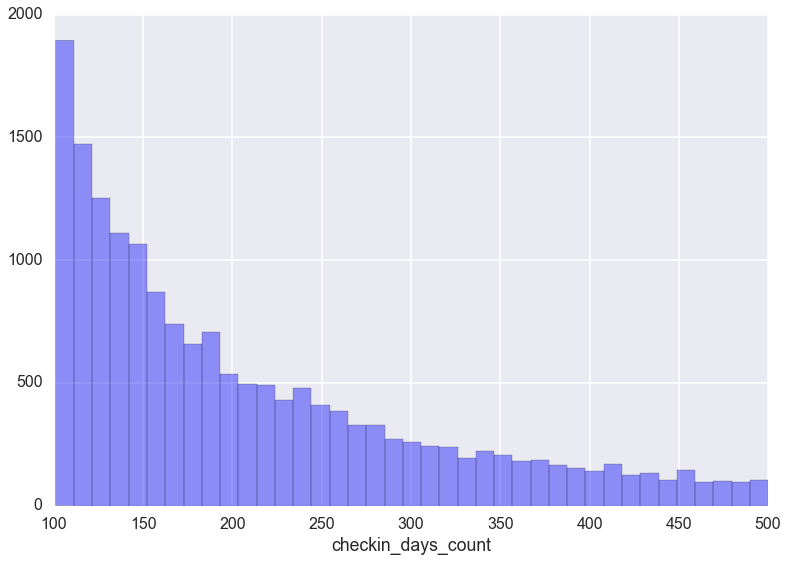
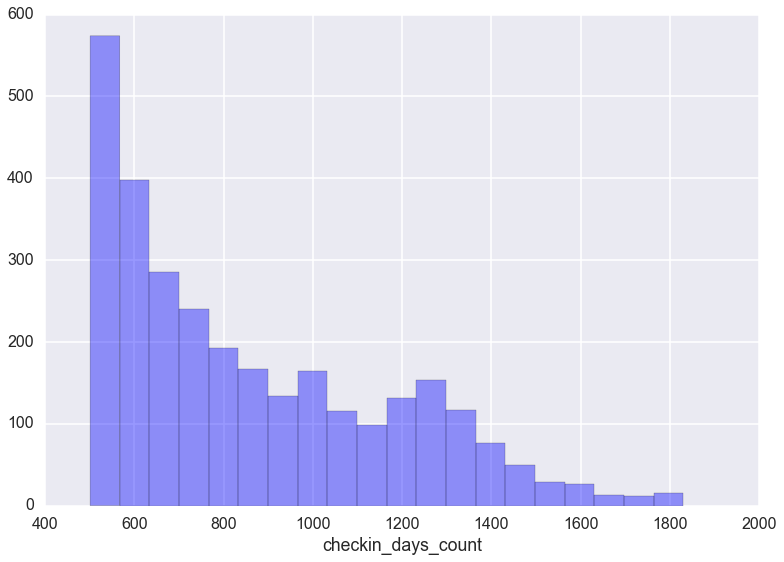
其他成长值的各种分布也是如此,在此就不贴出来了.
正如你所看到的,我再来总结一下,
在抽样中,
- 英语梦死在前0天的有416351人,占总比68.15%;
- 英语梦死在前1天的有466761人,占总比76.40%;
- 英语梦死在前2天的有484535人,占总比79.31%;
- 英语梦死在前5天的有510230人,占总比83.52%;
- 英语梦死在前10天的有531219人,占总比86.95%;
- 英语梦死在前20天的有551557人,占总比90.28%;
- 英语梦死在前50天的有575975人,占总比的94.28%;
- 英语梦死在前100天的有590700人,占总比96.69%;
- 英语梦死在前200天的有575975人,占总比98.36%;
- 英语梦死在前263天的有600875人,占总比98.81%;
你可以大致感受到残酷的现实,几乎没有多少人可以坚持到200天以后.
但是,你还需要注意到的事情是:
抽样的来源是ID为1~1111111之间的60W成员
众所周知的事情是:
- 早期的用户往往质量相对会高一些.而且,注册的ID越大,证明注册时间距离现在越近.获得200天的几率也就低了不少.
那么,这样的话,英语梦死在200天之前的人数比例还会大上不少.
回到文章开始:
问: 背单词软件有大概多少人注册第一天都没有背完嘛?
答:68.15%
问:有多少人是在坚持或者曾经坚持过背单词呢?(假设100天以上算的上是背单词的话)
答:保守估计,不足3.4%
问:有多少梦想,毁于不能坚持?
答:不妨干了这碗鸡汤,歌唱青春一去不复返.
问:背单词的人们学习的量,是不是符合正太分布呢?
答:不是,简直就是反比例函数.
抛出一个结论:
以绝大部分人努力之低,根本就用不着拼天赋.
赠给你我,共勉.
0x06 整个流程的不足和反思.
扇贝的工程师反爬虫做的还不错,主要有两点:
- 访问数量超标,封禁IP半个小时.对应的方法就是代理服务器.
- cookie如果不禁用很快就无法爬取.对应的方法就是禁用Cookie.
爬虫框架使用Scrapy,这样就免去了大量的繁琐的线程调度问题,直接写获取信息的逻辑代码,以及存储信息的逻辑代码就好了.
在编写爬虫的过程中,有一些经验:
- 在爬虫开启以后,由于我暴力的关闭,导致还是有不少的item没有完成请求处理和存储.
- 我在处理异常的时候忘了应当把失败的item存放放在文件中,方便我第二次补充,这样的话就不会丢失一部分的用户信息了.
- 代理服务器需要自己写脚本进行测试,否则你可能有很多很多的请求都会超时(毕竟很多代理服务器还是很不靠谱的).
我的分析数据能力并不是很强,仅仅是从CS109里面偷学了一点点,然后使用Seaborn画图,但是这整个过程中还是觉得自己分析不过来,不是写不出代码,而是不清楚使用什么样的数据模型进行分析更好.
0x07 代码
代码放在了Github上面,咳咳,注意,没有把代理服务器放进去.如果你跑一下会发现只能半小时抓取300+页面,这不是我的问题,是你没有把代理服务器填好.代码比较粗糙,还请轻拍.
代码的地址为:
https://github.com/twocucao/DataScience/
仓库里包含了抓取网站的代码和分析数据的IPython Notebook,自己阅读吧.
如果喜欢本文,就点个喜欢吧.