前言
上一篇文章分析了Bean工厂的创建,其真正的实现类和核心为DefaultListableBeanFactory,XML配置文件是封装成了Resource,由XmlBeanDefinitionReader进行了加载,最后在BeanDefinitionParserDelegate解析类中将XML根元素中的属性进行了处理。现在所有的准备工作完成,正式进入我们严格意义上的“有效”标签的解析
前面说到,默认情况下DefaultBeanDefinitionDocumentReader对于XML的前处理和后处理都为空实现,真正的处理逻辑在parseBeanDefinitions(Element, DefaultBeanDefinitionDocumentReader)中
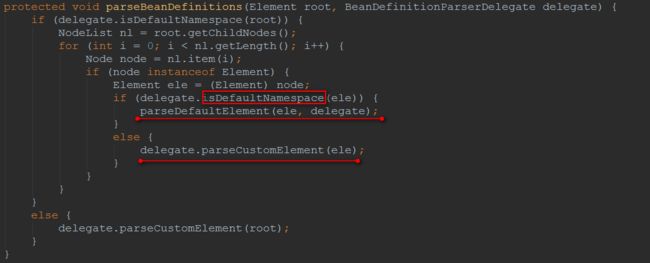
两次判断红框内代码判断根元素和其下所有子元素是否处在默认名称空间定义内,来看一下怎么判断的

根据获得的节点名称空间判断如果为空或者等于常量
BEANS_NAMESPACE_URI即为默认名称空间,该常量的值为
http://www.springframework.org/schema/beans,正是XML最基础的名称空间,回到图1,根据当前节点是否属于默认名称空间下分别调用红线处两个不同的方法,目前我们只分析默认名称空间下标签解析流程
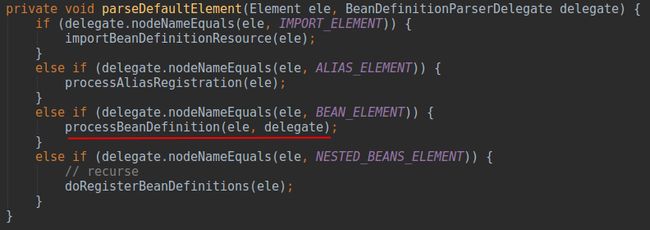
我们根据判断的四个常量可知,这里的默认标签元素分别为
处理
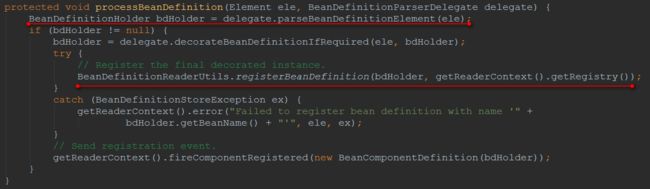
bean实例,与本文名称契合的这两部分并不是为了让大家更好的理解Spring运行流程特意杜撰的,而是Spring内部确实是这么划分的,上图中的两行代码就对应了这两个部分,我们先来第一部分
parseBeanDefinitionElement(Element, BeanDefinition)中

标注1解析
beanName,不存在用别名数组中第一个别名作为
beanName的值,标注3方法判断
beanName或者别名数组中的别名没有使用过,也就是说一个XML配置文件中同id或者同名不能重复注册
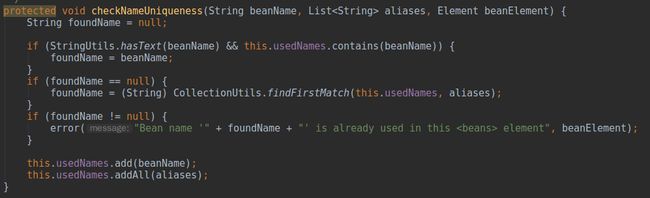
也许有人产生疑问了,在第一篇文章中命名说到可以存在同名的
usedNames中写的很清楚,在同一层次
ids/names,但是如果有多个XML配置文件,两个相同的
ids/names出现在不同的配置文件中,这种情况是可以被允许的。初始化加载时
usedNames内没有内容,每一次
id/name和所有的
alias。回到图5标注4创建出
bean的实例
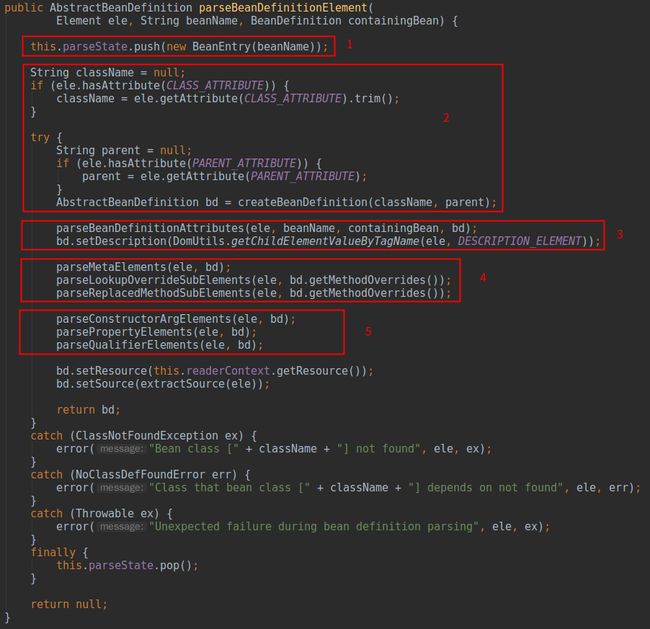
标注1将当前
parseState内部栈的栈顶,该对象用于记录解析到的一些重要标签或者属性对象,当解析发生错误时就可以知道到底解析到哪个对象出现了问题。标注2很明显是解析
class和
parent属性,其中的最后一句会生成
AbstractBeanDefinition的子类
GenericBeanDefinition,其中根据是否设置
bean的类加载器决定该类中的变量
beanClass保存的是
className还是类的实例。因为本文的例子中刚刚进入到解析XML和创建对应
BeanFactory的流程,此时类加载器为
null,为了证明这点我特意debug截图为证

从上图可以很清楚的看到此时
classLoader = null,那么创建的
GenericBeanDefinition中保存真实对象的变量
beanClass保存的实际上是类的名称而不是类的实例,记住这点非常关键否则下面没法分析
图7标注3
parseBeanDefinitionAttributes(Element, String, BeanDefinition, AbstractBeanDefintion)根据spring不同的版本解析诸如
scope、
abstract、
lazy-init等属性。标注4三个方法解析
BeanDefinition中设置任意
key-value对;
bean的类型;
MethodReplacer接口的类的
reimplement(Object, Method, Object[])代替。标注5中第一句就是大家熟悉的通过构造器实现注入的解析方式,对应的标签为
public void parseConstructorArgElement(Element ele, BeanDefinition bd) {
// (1)
String indexAttr = ele.getAttribute(INDEX_ATTRIBUTE);
String typeAttr = ele.getAttribute(TYPE_ATTRIBUTE);
String nameAttr = ele.getAttribute(NAME_ATTRIBUTE);
// (2)
if (StringUtils.hasLength(indexAttr)) {
try {
int index = Integer.parseInt(indexAttr);
if (index < 0) {
error("'index' cannot be lower than 0", ele);
}
else {
try {
// (3)
this.parseState.push(new ConstructorArgumentEntry(index));
// (4)
Object value = parsePropertyValue(ele, bd, null);
ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);
if (StringUtils.hasLength(typeAttr)) {
valueHolder.setType(typeAttr);
}
if (StringUtils.hasLength(nameAttr)) {
valueHolder.setName(nameAttr);
}
valueHolder.setSource(extractSource(ele));
// (5)
if (bd.getConstructorArgumentValues().hasIndexedArgumentValue(index)) {
error("Ambiguous constructor-arg entries for index " + index, ele);
}
else {
bd.getConstructorArgumentValues().addIndexedArgumentValue(index, valueHolder);
}
}
finally {
this.parseState.pop();
}
}
}
catch (NumberFormatException ex) {
error("Attribute 'index' of tag 'constructor-arg' must be an integer", ele);
}
}
else {
try {
// (6)
this.parseState.push(new ConstructorArgumentEntry());
Object value = parsePropertyValue(ele, bd, null);
ConstructorArgumentValues.ValueHolder valueHolder = new ConstructorArgumentValues.ValueHolder(value);
if (StringUtils.hasLength(typeAttr)) {
valueHolder.setType(typeAttr);
}
if (StringUtils.hasLength(nameAttr)) {
valueHolder.setName(nameAttr);
}
valueHolder.setSource(extractSource(ele));
bd.getConstructorArgumentValues().addGenericArgumentValue(valueHolder);
}
finally {
this.parseState.pop();
}
}
}
我们可以根据参数的三种属性之一进行注入,第一种为下标,初始从0开始;第二种为根据参数类型,比如是java.lang.String还是java.lang.Integer,注意,对于基本数据类型是无法通过构造器注入的,需要转成基本数据类型的包装数据类型;第三种是通过参数的名称注入,这种没什么好说的。只有采用第一种基于下标的注入方式才会进入到if中,标注3首先构建出一个Entry的实现类ConstructorArgumentEntry,并压入栈顶,这里的Entry是变量parseState的一个内部标记接口,只有实现该接口的对象才能被放入parseState内部的栈内
标注4主要做了两件事:1. 处理ref和value等属性;2. 解析
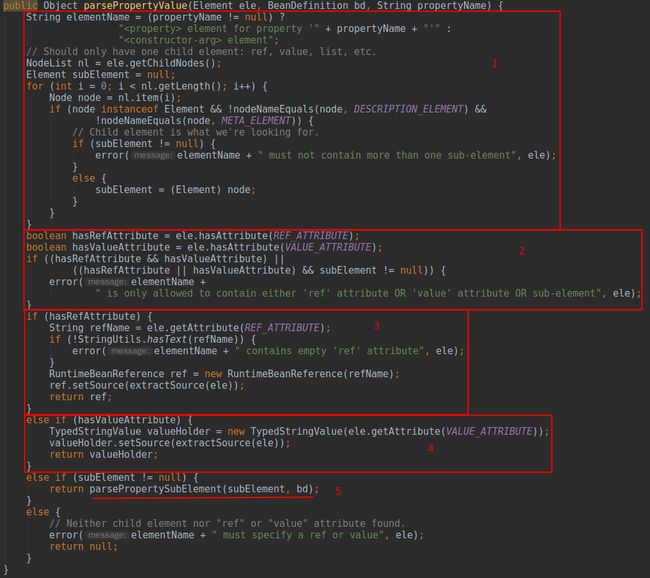
标注1解析出类型为
Element,标签名不为
description也不为
meta的子标签,引用指向
subElement。标注2解析
ref和
value属性,确保两个属性不能同时出现。标注3得到
ref的值封装成
RuntimeBeanReference对象返回。标注4得到
value的值封装成
TypeStringValue返回。如果上面解析到
回到代码清单1看标注5处,上面说的在这个
if中都是存在
index属性的,这里就是判断解析到的
index值是否已经存在,在
ConstructorArgumentValues对象中持有一个
Map集合,其中
key即为下标,
value为下标对应标签值封装的对象,如果通过验证就往
map中塞入对应的键值对。标注6处对应着
else的部分表示在没有
index属性时解析
parsePropertyValue(Element, BeanDefinition, String)方法,封装
ValueHolder实例,根据属性类型的不同进行不同的设置,之前存在
index属性的标签对象存放在
map中,而不存在
index属性的标签对象放在链表中
绕了一个大圈子终于分析完
parsePropertyElements(Element, BeanDefinition),该方法和解析其他标签一开始的思路一致,都是遍历所有子标签,判断标签名称是否为
property,是则进入
parsePropertyElement(Element, BeanDefinition)
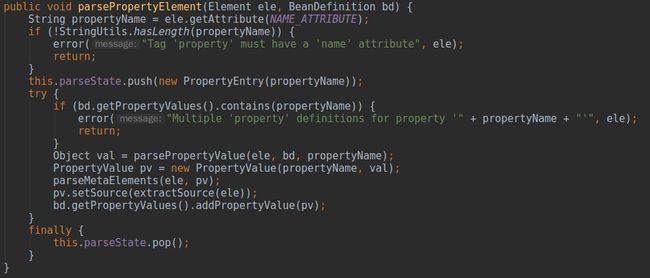
首先获得
name的值,如若没有记录错误日志并抛出异常,对于一个
BeanDefinition来说,对象内存在一个
MutablePropertyValues对象,该对象中维护了一个
List集合,该集合就保存了所有的
name-value/ref对,既然如此,在解析的过程中必然要判断集合中是否已经存在同名称的
PropertyValue,如果存在自然也会报错,不存在就需要真正解析
propertyName为
null,而
name的值了,解析并创建
PropertyValue对象后,同样要使用
parseMetaElement(Element, BeanMetadataAttributeAccessor)解析内嵌的
List中
图7标注5中最后一句用来解析
id,也没有填写
name,Spring会为我们生成一个
name,由于
containingBean在这里为
null,因此最终的流程会走到
else内,最终使用
BeanDefinitionReaderUtils来生成
beanName
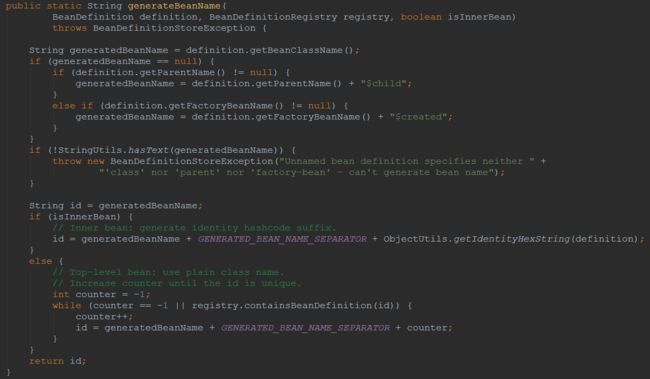
首先获得
BeanDefinition中的
class name,因为上面的步骤已经解析过
isInnerBean = false(至于为什么请读者顺着流程走一次便知),因此最后形成返回值的公式即为
while中的
generatedBeanName + GENERATED_BEAN_NAME_SEPARATOR + counter;,其中的常量值为
#,举个例子,如果
,那么最终生成的
beanName即为
com.xiaomi.Student#0。将解析的所有这一些按图5标注5代码封装成
BeanDefinitionHolder后标志着
下面我们开始
Bean实例的注册流程进入图3第二个下划线代码内,在正式分析之前我们需要先看几个重要的成员变量,第一篇文章中曾经说过
BeanFactory的核心实现类为
DefaultListableBeanFactory,在该类中有几个非常重要的成员变量
 图12. DefaultListableBeanFactory中成员变量
图12. DefaultListableBeanFactory中成员变量
先来说两个现在要用到的,
beanDefinitionMap和
beanDefinitionNames,前者保存有
id/beanName-bean实例键值对,后者保存所有的
beanName
 图13. DefaultListableBeanFactory的registerBeanDefinition(String, BeanDefinition)
图13. DefaultListableBeanFactory的registerBeanDefinition(String, BeanDefinition)
注册
bean的逻辑远远没有解析
beanDefinitionMap根据
beanName查找是否存在对应的实例,如果存在判断是否开启了实例覆盖标识,没有开启抛出异常,再将
beanName和对应实例放入
beanDefinitionMap中,最后一句的作用是清除所有
beanName所属实例及其衍生类的本地缓存信息
后记
即便有意隐去的非重点流程,