Python网络数据采集3-数据存到CSV以及MySql
先热热身,下载某个页面的所有图片。
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/52.0.2743.116 Safari/537.36 Edge/15.16193'}
start_url = 'https://www.pythonscraping.com'
r = requests.get(start_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
# 获取所有img标签
img_tags = soup.find_all('img')
for tag in img_tags:
print(tag['src'])
https://www.pythonscraping.com/sites/default/files/lrg_0.jpg
http://pythonscraping.com/img/lrg%20(1).jpg
将网页表格存储到CSV文件中
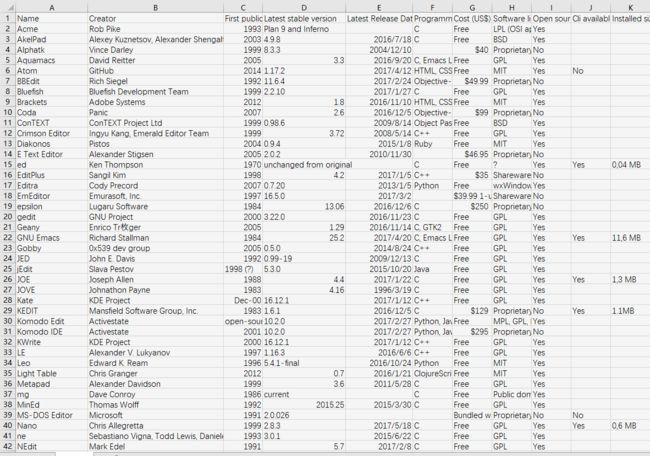
以这个网址为例,有好几个表格,我们对第一个表格进行爬取。Wiki-各种编辑器的比较
import csv
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/52.0.2743.116 Safari/537.36 Edge/15.16193'}
url = 'https://en.wikipedia.org/wiki/Comparison_of_text_editors'
r = requests.get(url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
# 只要第一个表格
rows = soup.find('table', class_='wikitable').find_all('tr')
# csv写入时候每写一行会有一空行被写入,所以设置newline为空
with open('editors.csv', 'w', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
for row in rows:
csv_row = []
for cell in row.find_all(['th', 'td']):
csv_row.append(cell.text)
writer.writerow(csv_row)
需要注意的有一点,打开文件的时候需要指定newline='',因为写入csv文件时,每写入一行就会有一空行被写入。
从网络读取CSV文件
上面介绍了将网页内容存到CSV文件中。如果是从网上获取到了CSV文件呢?我们不希望下载后再从本地读取。但是网络请求的话,返回的是字符串而非文件对象。csv.reader()需要传入一个文件对象。故需要将获取到的字符串转换成文件对象。Python的内置库,StringIO和BytesIO可以将字符串/字节当作文件一样来处理。对于csv模块,要求reader迭代器返回字符串类型,所以使用StringIO,如果处理二进制数据,则用BytesIO。转换为文件对象,就能用CSV模块处理了。
下面的代码最为关键的就是data_file = StringIO(csv_data.text)将字符串转换为类似文件的对象。
from io import StringIO
import csv
import requests
csv_data = requests.get('http://pythonscraping.com/files/MontyPythonAlbums.csv')
data_file = StringIO(csv_data.text)
reader = csv.reader(data_file)
for row in reader:
print(row)
['Name', 'Year']
["Monty Python's Flying Circus", '1970']
['Another Monty Python Record', '1971']
["Monty Python's Previous Record", '1972']
['The Monty Python Matching Tie and Handkerchief', '1973']
['Monty Python Live at Drury Lane', '1974']
['An Album of the Soundtrack of the Trailer of the Film of Monty Python and the Holy Grail', '1975']
['Monty Python Live at City Center', '1977']
['The Monty Python Instant Record Collection', '1977']
["Monty Python's Life of Brian", '1979']
["Monty Python's Cotractual Obligation Album", '1980']
["Monty Python's The Meaning of Life", '1983']
['The Final Rip Off', '1987']
['Monty Python Sings', '1989']
['The Ultimate Monty Python Rip Off', '1994']
['Monty Python Sings Again', '2014']
DictReader可以像操作字典那样获取数据,把表的第一行(一般是标头)作为key。可访问每一行中那个某个key对应的数据。
每一行数据都是OrderDict,使用Key可访问。看上面打印信息的第一行,说明由Name和Year两个Key。也可以使用reader.fieldnames查看。
from io import StringIO
import csv
import requests
csv_data = requests.get('http://pythonscraping.com/files/MontyPythonAlbums.csv')
data_file = StringIO(csv_data.text)
reader = csv.DictReader(data_file)
# 查看Key
print(reader.fieldnames)
for row in reader:
print(row['Year'], row['Name'], sep=': ')
['Name', 'Year']
1970: Monty Python's Flying Circus
1971: Another Monty Python Record
1972: Monty Python's Previous Record
1973: The Monty Python Matching Tie and Handkerchief
1974: Monty Python Live at Drury Lane
1975: An Album of the Soundtrack of the Trailer of the Film of Monty Python and the Holy Grail
1977: Monty Python Live at City Center
1977: The Monty Python Instant Record Collection
1979: Monty Python's Life of Brian
1980: Monty Python's Cotractual Obligation Album
1983: Monty Python's The Meaning of Life
1987: The Final Rip Off
1989: Monty Python Sings
1994: The Ultimate Monty Python Rip Off
2014: Monty Python Sings Again
写入数据库中
数据库使用MySql
如果服务没有后启动,首先启动服务。net start mysql57这里57是版本号,根据自己的版本填写。
然后mysql -u root -p输入密码后就可以使用了。
先来简单复习下SQL语法。
SQL基本语法
下面是关于数据库的操作
-
create database example;这样创建一个叫做example的数据库。 -
drop database example;则是删除这个数据库。 -
show databases;可以查看所有数据库。 -
use example;使用这个数据库。select database();显示当前正在使用的数据库。
下面是关于表的操作
-
show tables;查看当前数据库下的所有表。 -
desc some_table;查看某个表的具体结构。 -
drop table some_table;删除某个表。 -
alter table some_table add age int;加一列 -
alter table some_table drop age;删除一列
下面是表的CURD
-
insert into t_user(name, email) values('tom','[email protected]');添加一行数据,可以指定任意列的内容,剩下的要么自己生成(如id一般自增),要么就是默认值。 -
UPDATE t_user SET NAME='rose' WHERE id=7;更新数据,表示将id为7的数据name改为rose。 -
DELETE FROM t_user WHERE NAME='God';把name是God的记录删除。DELETE FROM t_user;删除整张表中所有记录. -
select * from stu;查询stu表里所有数据,*是通配符匹配所有。 -
select sname from stu;查询stu的sname那列。 -
select * from stu where gender='female' and age<50;条件查询。
使用pymysql连接到MySql
Python连接MySql,这里使用pymysql
import pymysql
conn = pymysql.connect(host='localhost', user='root', password='admin', db='example',charset='utf8')
cur = conn.cursor()
try:
# 上面填了参数这句就不是必须的
# cur.execute('USE example')
cur.execute('SELECT * FROM pages')
print(cur.fetchone())
finally:
cur.close()
conn.close()
(1, 'Test Title', '方法', datetime.datetime(2017, 7, 15, 15, 45, 46))
db参数表示选择的数据库名称。连接数据库时候,加上charset=utf8可以处理中文字符。注意不要写成utf-8。然后就是连接和光标都要记得close。
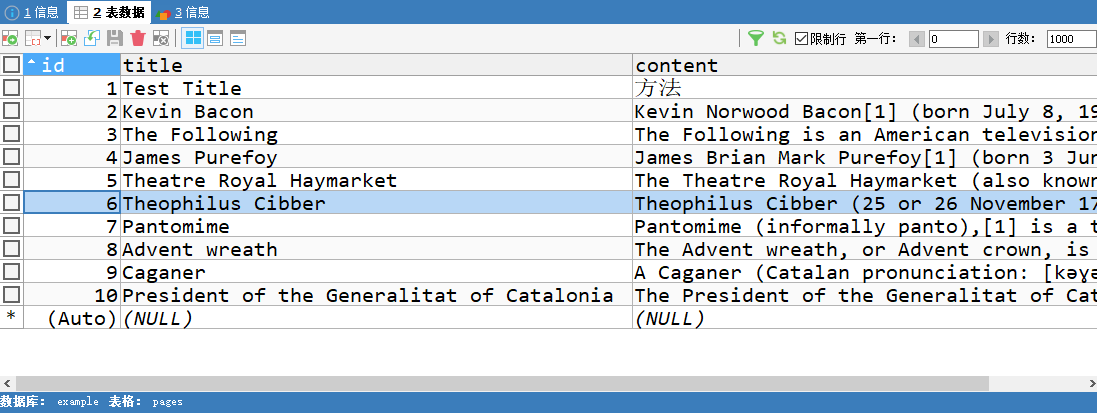
接下来从某个wiki页面开始,随机获取一个词条访问其页面,并储存词条的标题(title)和正文第一段(content)到MySql。
建表。
create TABLE pages(id int primary key auto_increment,title varchar(200),content varchar(10000),created timestamp default current_timestamp);
上代码
import re
import random
import pymysql
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/52.0.2743.116 Safari/537.36 Edge/15.16193'}
conn = pymysql.connect(host='localhost', user='root', password='admin', db='example', charset='utf8')
cur = conn.cursor()
# 存到数据库
def store(title, content):
try:
cur.execute(f"INSERT INTO pages(title, content) VALUES('{title}', '{content}');")
except Exception as e:
print(e)
else:
conn.commit()
# 获得页面内所有词条的链接
def get_links(article_url):
r = requests.get('https://en.wikipedia.org' + article_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
title = soup.h1.string
content = soup.find('div', id='mw-content-text').find('p').text
store(title, content)
links = soup.find('div', id='bodyContent').find_all('a', href=re.compile('^/wiki/[^:/]*$'))
return links
link_list = get_links('/wiki/Kevin_Bacon')
try:
while len(link_list) > 0:
new_article = random.choice(link_list).get('href')
print(new_article)
link_list = get_links(new_article)
finally:
cur.close()
conn.close()
conn.commit()注意这句,由于连接不是自动提交的,需要我们手动提交,确保数据确实改变。有些词条的可能会导致在执行查询语句的时候发生异常,处理一下,不让其终止爬取。看下结果。
保存链接之间的联系
比如链接A,能够在这个页面里找到链接B。则可以表示为A -> B。我们就是要保存这种联系到数据库。先建表:
pages表只保存链接url。
CREATE TABLE `pages` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`url` varchar(255) DEFAULT NULL,
`created` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`)
);
links表保存链接的fromId和toId,这两个id和pages里面的id是一致的。如1 -> 2就是pages里id为1的url页面里可以访问到id为2的url的意思。
CREATE TABLE `links` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`fromId` int(11) DEFAULT NULL,
`toId` int(11) DEFAULT NULL,
`created` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`);
上面的建表语句看起来有点臃肿,我是先用可视化工具建表后,再用show create table pages这样的语句查看的。
import re
import pymysql
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)'
' Chrome/52.0.2743.116 Safari/537.36 Edge/15.16193'}
conn = pymysql.connect(host='localhost', user='root', password='admin', db='wiki', charset='utf8')
cur = conn.cursor()
def insert_page_if_not_exists(url):
cur.execute(f"SELECT * FROM pages WHERE url='{url}';")
# 这条url没有插入的话
if cur.rowcount == 0:
# 那就插入
cur.execute(f"INSERT INTO pages(url) VALUES('{url}');")
conn.commit()
# 刚插入数据的id
return cur.lastrowid
# 否则已经存在这条数据,因为url一般是唯一的,所以获取一个就行,取脚标0是获得id
else:
return cur.fetchone()[0]
def insert_link(from_page, to_page):
print(from_page, ' -> ', to_page)
cur.execute(f"SELECT * FROM links WHERE fromId={from_page} AND toId={to_page};")
# 如果查询不到数据,则插入,插入需要两个pages的id,即两个url
if cur.rowcount == 0:
cur.execute(f"INSERT INTO links(fromId, toId) VALUES({from_page}, {to_page});")
conn.commit()
# 链接去重
pages = set()
# 得到所有链接
def get_links(page_url, recursion_level):
global pages
if recursion_level == 0:
return
# 这是刚插入的链接
page_id = insert_page_if_not_exists(page_url)
r = requests.get('https://en.wikipedia.org' + page_url, headers=headers)
soup = BeautifulSoup(r.text, 'lxml')
link_tags = soup.find_all('a', href=re.compile('^/wiki/[^:/]*$'))
for link_tag in link_tags:
# page_id是刚插入的url,参数里再次调用了insert_page...方法,获得了刚插入的url里能去往的url列表
# 由此形成联系,比如刚插入的id为1,id为1的url里能去往的id有2、3、4...,则形成1 -> 2, 1 -> 3这样的联系
insert_link(page_id, insert_page_if_not_exists(link_tag['href']))
if link_tag['href'] not in pages:
new_page = link_tag['href']
pages.add(new_page)
# 递归查找, 只能递归recursion_level次
get_links(new_page, recursion_level - 1)
if __name__ == '__main__':
try:
get_links('/wiki/Kevin_Bacon', 5)
except Exception as e:
print(e)
finally:
cur.close()
conn.close()
1 -> 2
2 -> 1
1 -> 2
1 -> 3
3 -> 4
4 -> 5
4 -> 6
4 -> 7
4 -> 8
4 -> 4
4 -> 4
4 -> 9
4 -> 9
3 -> 10
10 -> 11
10 -> 12
10 -> 13
10 -> 14
10 -> 15
10 -> 16
10 -> 17
10 -> 18
10 -> 19
10 -> 20
10 -> 21
...
看打印的信息,一目了然。看前两行打印,pages表里id为1的url可以访问id为2的url,同时pages表里id为2的url可以访问id为1的url...依次类推。
首先需要使用insert_page_if_not_exists(page_url)获得链接的id,然后使用insert_link(fromId, toId)形成联系。fromId是当前页面的url,toId则是从当前页面能够去往的url的id,这些能去往的url用bs4找到以列表形式返回。当前所处的url即page_id,所以需要在insert_link的第二个参数中,再次调用insert_page_if_not_exists(link)以获得列表中每个url的id。由此形成了联系。比如刚插入的id为1,id为1的url里能去往的id有2、3、4...,则形成1 -> 2, 1 -> 3这样的联系。
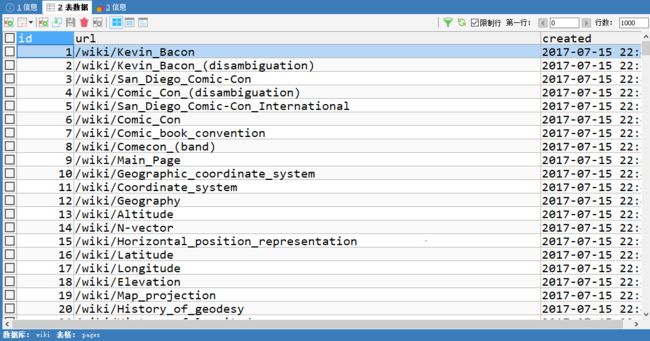
看下数据库。下面是pages表,每一个id都对应一个url。
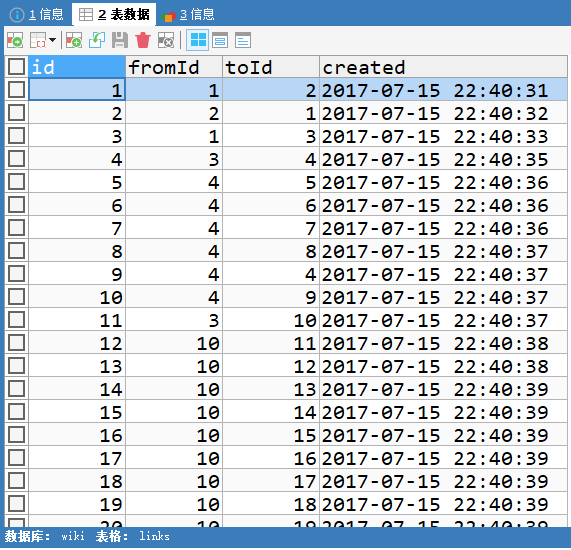
然后下面是links表,fromId和toId就是pages中的id。当然和打印的数据是一样的咯,不过打印了看看就过去了,存下来的话哪天需要分析这些数据就大有用处了。
by @sunhaiyu
2017.7.15