iOS中的文字渲染
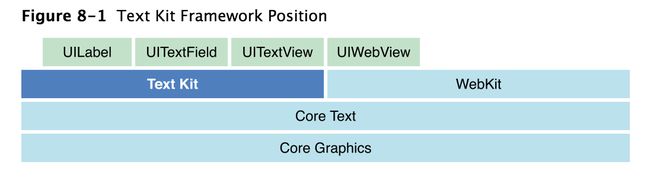
在iOS出现早期,显示特性文本唯一可行的办法就是使用UIWebView和利用HTML来处理定制特性。不过这种方法实现起来很困难,且性能很糟糕。iOS3.2中加入了CoreText,它将Mac平台的NSAttributedString的全部功能带到了移动平台。不过CoreText有些复杂不太实用。
在TextKit推出之前,iOS的文本渲染是个有一定难度且复杂的话题。TextKit的第一次发布是作为iOS7的一部分,TextKit不是一个传统意义上的框架。相反,TextKit是对于更好地处理文本展示对象及其特性的一组增强功能在术语上的表示。
TextKit
是苹果官方给出的结构图:Text Kit is built on top of Core Text, so it provides the same speed and power.

那么TextKit包含什么内容呢?先想一下实现一段富文本需要做的事:第一步,生成NSAttributedString属性字符串对象(通过AttributeName设置不同的样式);第二步,直接交给UILabel、UITextView、UITextField渲染出来,非常方便。TextKit在这中间帮我们做了绝大部分工作,并且支持子类化、提供代理和一套全面的通知以实现深度定制。下面是官方文档里关于TextKit主要类之间的关系图:
主要涉及三个类:NSTextStorage、NSLayoutManager和NSTextContainer:
NSTextStorage用来保存和管理textView要展示的文本,它是NSMutableAttributedString的子类;
NSLayoutManager管理文本的排版布局;
NSTextContainer定义文本的展示区域;
从官方文档和注释可以大概了解这三个类的作用和提供出来的一些接口,但个人感觉直接理解起来还是有点抽象。
我们不妨先思考下一个文本(带属性的字符串),怎么渲染到屏幕上?抛开最底层的渲染原理,其实还是通过图形接口一个一个字符绘制出来的,这种“笨方法”我们可以通过CoreText实现,而TextKit也是在这个基础上设计的易用的面相对象一套东西。了解这些底层方法之后再回过头来看TextKit的设计,就不那么抽象了。
CoreText
既然是一个字符一个字符绘制出来的,那么就需要知道每个字符的字体、所在位置、坐标等等信息,在CoreText中用CTFrameRef来表示,有了frame之后使用
CTFrameDraw方法在上下文中绘制。(实际上CTFrame是一个比较“大”的概念,包含整个文本的信息,后面再详细讨论frame里面有什么东东)
void CTFrameDraw(
CTFrameRef frame,
CGContextRef context )
还是先从一个简单的demo说起吧,我们创建一个CTSimpleView继承自UIView,在它的drawRect方法里面用CoreText绘制一段文本:
- (void)drawRect:(CGRect)rect
{
[super drawRect:rect];
CGContextRef context = UIGraphicsGetCurrentContext();
/* 文本的内容CFAttributedStringRef */
CFAttributedStringRef astr = CFAttributedStringCreate(kCFAllocatorSystemDefault,
CFSTR("HelloWord!"), NULL);
/* 根据文本内容创建一个framesetter对象(创建frame时使用) */
CTFramesetterRef framesetter = CTFramesetterCreateWithAttributedString(astr);
/* 渲染文本用到的路径:可绘制区域(创建frame时使用) */
CGMutablePathRef path = CGPathCreateMutable();
CGPathAddRect(path, NULL, self.bounds);
/* 根据framesetter和path得到frame:包含字体信息和坐标信息 */
CTFrameRef frame = CTFramesetterCreateFrame(framesetter, CFRangeMake(0, CFAttributedStringGetLength(astr)), path, NULL);
// 在context中绘制
CTFrameDraw(frame, context);
// 释放cf对象
CFRelease(frame);
CFRelease(path);
CFRelease(framesetter);
}
很好理解,有了文本内容和路径,创建frame对象在调用draw方法就可以绘制出来。运行后会发现文本是倒着的,是因为iOS的坐标系统是y轴向下的,与Mac平台相反,所以要做下坐标变换:
/* CTM:Current transformation matrix 上下文当前变换矩阵 */
/* 这里是因为CT的坐标系(y轴向上)和UIKit的坐标系(y轴向下)的区别,
* 需要做变换:(x,y)->(x,-y+height) */
CGContextTranslateCTM(context, 0, self.bounds.size.height);
CGContextScaleCTM(context, 1.0, -1.0);
一般的文章包括一些源码里都会像这么写,这里简单讨论下变换矩阵和仿射变换:
/* 如果把上面两句话调换下顺序会怎样?*/
CGContextScaleCTM(context, 1.0, -1.0);
CGContextTranslateCTM(context, 0, self.bounds.size.height);
/* 会发现文本没了,为什么?(x,y)->(x,-y+height)明明是y先乘-1在加height的呀
* 我们看下CGContextScaleCTM这类函数的注释,会发现它们都是对CTM(current
* graphics state's transformation matrix)做的变换,对当前绘图状态的变换矩
* 阵做变换,都是左乘的(另一篇文章http://www.jianshu.com/p/09c1d32e43fc专门
* 讨论了对变换做变换的概念,可以理解为左乘的矩阵会影响到后面的矩阵) 所以这里从上
* 往下的函数顺序,在坐标变换时是反着来的:先加了height,在乘-1 变成了:(x,y)->
* (x,-(y+height))了,自然不在我们的绘制范围内了。 */
/* 在说下什么是仿射变换:有的地方说就是线性变换+平移,经过变换后,直线还是直线,平行线还是平行线。
* 通俗点说,对二维坐标(x,y)变换后的坐标(f(x,y),g(x,y)) 中f和g都是关于x,y的二元一次函数:
* f(x,y) = ax+by+e; g(x,y) = cx+dy+f 用tx、ty表示平移的量e和f,就是
* CGAffineTransform的定义: */
struct CGAffineTransform {
CGFloat a, b, c, d;
CGFloat tx, ty;
};
/* 对应变换矩阵
* a c 0
* b d 0
* fx fy 1
* 只是右边一列固定是(0 0 1) */
/* 所以上边两行也可以写成:*/
CGContextConcatCTM(context, CGAffineTransformMake(1, 0, 0, -1, 0, self.bounds.size.height));
简单一句“HelloWord!”的frame竟包含了这么多东西,别慌,一点一点看:
首先是visible string range,很好理解就是文本“HelloWord!”的range,
path是我们定义的CGPath 可绘制区域,
attributes是null(我们刚才的代码并没有设置attributes),
(重点来了)lines:发现从第二行开始到最后其实是一个CTLine对象,所以frame包含一些通用的属性(range、path、attributes)和一组CTLine(lines),详细信息还在CTLine中:
再看CTLine里包含了什么:
run count:(这个先不管,往后看就知道了)
string range:这个和frame里的一样都是(0,10),因为我们的frame只有这一个line
width:宽度,不用解释了吧

glyph count:这个也好理解,line包含的字符个数
再往下又是一组CTRun对象,run里面文本内容、字体等相信信息都有了,到这其实frame的结构已经很清晰了:
一段文本的frame包含多个行(line),每行里面分成属性相同的子串(run),再就是每个字符(glyph)了:

CTLine、CTRun都有相应的draw方法,run作为一个相对基本的单位(其实还有基于字符的CTFontDrawGlyphs,这次先不讨论)提供CTRunDelegate几个回调方法可以使用,见CTRunDelegate.h:
typedef struct
{
CFIndex version;
CTRunDelegateDeallocateCallback dealloc;
CTRunDelegateGetAscentCallback getAscent;
CTRunDelegateGetDescentCallback getDescent;
CTRunDelegateGetWidthCallback getWidth;
} CTRunDelegateCallbacks;
我们可以自己定义ascent、descent和width。
关于CoreText的简单用法就是这些,利用这些api可以实现图文混排和链接等稍微复杂些的文本。比如图文混排,我们可以用一个空白占位符代替,根据图像的大小用CTRunDelegate指定空白符为相应大小,在对应位置上绘制上图片即可,剩下的就是坐标转换、对应等一些“杂事”了。
可以参考唐巧的《iOS开发进阶》中关于CoreText的章节,照着示例敲一遍基本就理解大概了。更深入的研究可以看一些源码(比如YYText),后续再更新这方面的一些心得。