引言
最近有个大佬考察了我关于autoreleasepool的了解, 之前一直认为自己了解, 但是稍微一问深, 自己却哑口无言. 仔细思考了下, 决定要将这个问题结合之前的知识从新梳理一下, 当然, 实践是必不可少的.
- main函数中的autoreleasepool的作用?
- 系统的autoreleasepool我们自己创建的autoreleasepool释放时机差别在哪?
- 在ARC的环境中, 什么情况下需要使用autoreleasepool? 不使用autoreleasepool变量什么时候会被释放?
带着这三个问题, 一起进行一下下面的思考.
正文
对于autoreleasepool释放时机, 我们很容易在网上搜到这样的说法:
分两种情况:手动干预释放时机、系统自动去释放。
手动干预释放时机--指定autoreleasepool 就是所谓的:当前作用域大括号结束时释放。
系统自动去释放--不手动指定autoreleasepool
先不谈上面是否完全正确, 基于以上认知, 当时我灵光一闪推测main函数中autoreleasepool的作用可能为下面两种之一:
1.系统主线程中的默认的autoreleasepool.
2.整个App相对于iOS系统的一个autoreleasepool.
其他的解释其实在网上可以搜到很多, 所以这里我们可以做一个小实验.
第一点其实很好验证, 将main函数中的autoreleasepool注释掉, 运行
for (int i = 0; i < 10e5 * 2; i++) {
NSString *str = [NSString stringWithFormat:@"hi + %d", i];
}
NSLog(@"finished!");
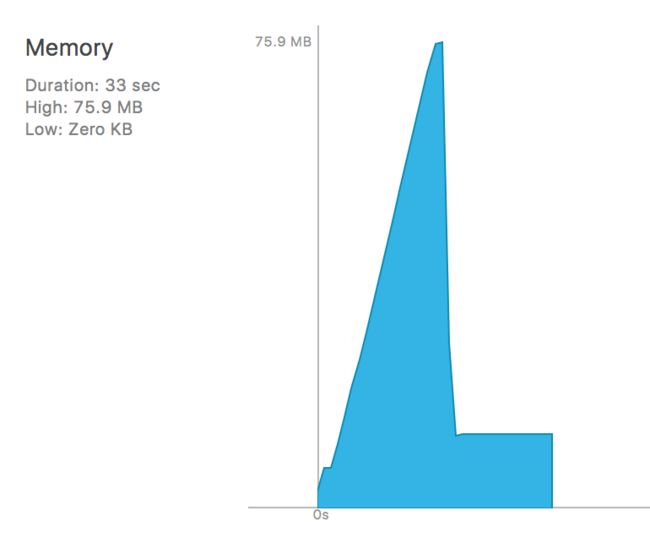
实际结果表明, 内存波动并没有什么区别:
-
未注释Main函数中的autoreleasepool
-
注释Main函数中的autoreleasepool
所以我们可以认为第二种是对的吗, 后来自己一想也觉得不对, 对于系统内存管理相关代码怎么会在程序里面呢, 不符合苹果的风格. 结果很明显我自己推测的都不对, 所以到底起什么作用呢? 待会再细说, 先验证一下释放时机的问题.
同样是上面一段函数, 在for循环中加入autoreleasepool:
for (int i = 0; i < 10e5 * 2; i++) {
@autoreleasepool {
NSString *str = [NSString stringWithFormat:@"hi + %d", i];
}
}
NSLog(@"finished!");
我相信稍微了解一点的同学已经知道了运行结果:
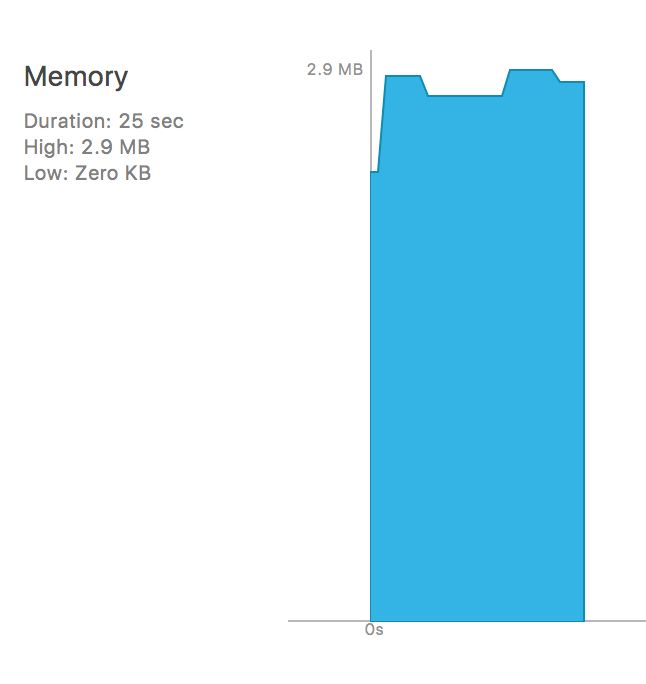
为临时变量分配的内存已经得到平稳的释放, 所以结论就是最上面我们看到的认知? 其实本身每个Runloop已经默认会创建一个autoreleasepool了, 所以我们这里添加相当于嵌套(便于理解)了一个, 并没有弄清楚autoreleasepool自身的释放时机. 下面做另外一个小测试:
这一次在代码中新增对Runloop的Observer, 及时获取Runloop的状态变化确认释放时机, 代码如下:
// 添加一个监听者
- (void)addRunLoopObserver {
// 1. 创建监听者
CFRunLoopObserverRef observer = CFRunLoopObserverCreateWithHandler(kCFAllocatorDefault, kCFRunLoopAllActivities, YES, 0, ^(CFRunLoopObserverRef observer, CFRunLoopActivity activity) {
switch (activity) {
case kCFRunLoopEntry:
NSLog(@"进入RunLoop");
break;
case kCFRunLoopBeforeTimers:
NSLog(@"即将处理Timer事件");
break;
case kCFRunLoopBeforeSources:
NSLog(@"即将处理Source事件");
break;
case kCFRunLoopBeforeWaiting:
NSLog(@"即将休眠");
break;
case kCFRunLoopAfterWaiting:
NSLog(@"被唤醒");
break;
case kCFRunLoopExit:
NSLog(@"退出RunLoop");
break;
default:
break;
}
});
// 2. 添加监听者
CFRunLoopAddObserver(CFRunLoopGetMain(), observer, kCFRunLoopCommonModes);
}
另外上面的方法运行连续运行两次, 不手动添加autoreleasepool, 大概是这样:
- (void)test1 {
NSLog(@"test1 begin!");
for (int i = 0; i < 10e5 * 2; i++) {
//@autoreleasepool {
NSString *str = [NSString stringWithFormat:@"hi + %d", i];
//}
}
NSLog(@"test1 finished!");
}
- (void)test2 {
NSLog(@"test2 begin!");
for (int i = 0; i < 10e5 * 2; i++) {
//@autoreleasepool {
NSString *str = [NSString stringWithFormat:@"hi + %d", i];
//}
}
NSLog(@"test2 finished!");
}
运行之后的效果是这样的:
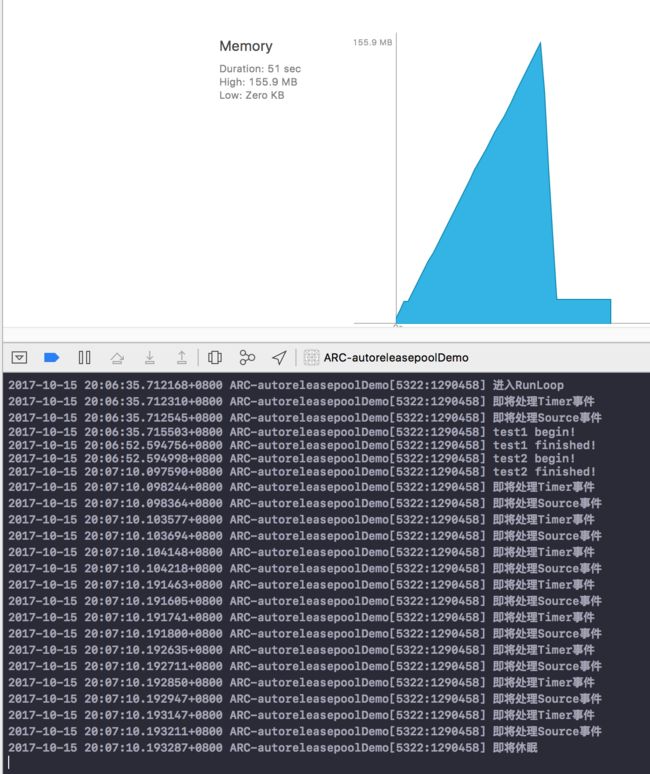
很清楚的看到Runloop没有完成一次循环之前所有内存都未释放, 即使局部变量出了作用域也必须等待Runloop循环完成.
下面同样, 手动添加autoreleasepool观察释放时机.
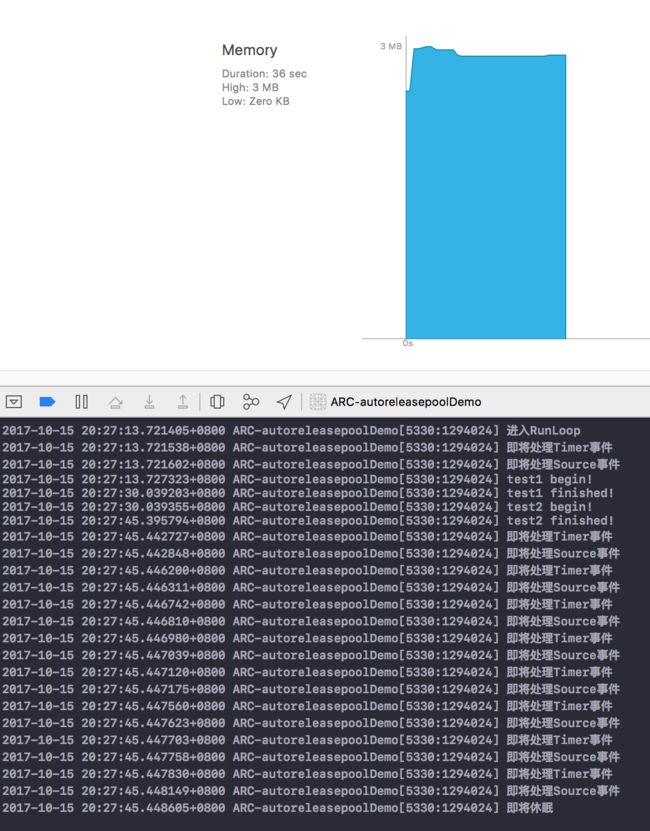
结果是意外也合理的. 即使Runloop未完成循环, 内存也即使释放了.
总结
@autoreleasepool{}
等价于
void *context = objc_autoreleasePoolPush();
// {}中的代码
objc_autoreleasePoolPop(context);
每次出了{}时objc_autoreleasePoolPop()就被调用, 所以直接释放掉了. 当然, 系统自动创建的autoreleasepool也是一样, 只是调用的时机不同: 线程与Runloop是一一对应, Runloop与系统创建的autoreleasepool也是一一对应, 所以不论是Runloop完成了一次循环还是线程被关闭时, autoreleasepool都会释放, 当然手动添加的也会被管理, 上面为了方便理解, 说的是嵌套, 本质上是没有嵌套这个说法的, 对@autoreleasepool{}本质的一些个人总结:
主要就是一个类:AutoreleasePoolPage
两个函数: objc_autoreleasePoolPush()、objc_autoreleasePoolPop()
运作方式: autoreleasepool由若干个autoreleasePoolPage类以双向链表的形式组合而成, 当程序运行到@autoreleasepool{时, objc_autoreleasePoolPush()将被调用, runtime会向当前的AutoreleasePoolPage中添加一个nil对象作为哨兵,
在{}中创建的对象会被依次记录到AutoreleasePoolPage的栈顶指针,
当运行完@autoreleasepool{}时, objc_autoreleasePoolPop(哨兵)将被调用, runtime就会向AutoreleasePoolPage中记录的对象发送release消息直到哨兵的位置, 即完成了一次完整的运作.
另外根据官方文档:
Threads
If you are making Cocoa calls outside of the Application Kit’s main thread—for example if you create a Foundation-only application or if you detach a thread—you need to create your own autorelease pool......
主线程中的自动释放池是自动创建的, 文档中说子线程中的自动释放池是需要手动创建的, 但实测, 其实我们常用的多线程管理方式(GCD, NSOprationQueue, NSThread)都已经帮我们处理好了, 其中NSThread在iOS7之后才自动创建线程中的AutoreleasePool, 这个在官方文档中找不到记录, 参考StackOverflow: https://stackoverflow.com/questions/24952549/does-nsthread-create-autoreleasepool-automatically-now
另外网上有说法AutoreleasePool会影响性能, 其实看上面的函数运行的时间就可以发现, 并没有影响, 甚至加入了AutoreleasePool运行快了2秒(不严谨).
回到最初的问题, main函数中的autoreleasepool的作用, 我翻阅了大量资料, 在StackOverflow上赞的比较高的回答是没卵用... 暂且只能先这样认为了.. 希望有了解的同学可以讲解一下~
在实际中的使用场景其实很明确了, 在程序中中有大量临时变量的时候最好手动创建.
最常出现大量变量的时候显然是循环/遍历, 我们常用的for循环, 以及enumerate其实跟autoreleasepool也有关, for循环是不自动创建autoreleasepool的, 而enumerate中已经自动创建了autoreleasepool, 值得注意的是高并发enumerate常常会出一些意外的问题, 例如对象被提前释放, 所以建议高并发情况下使用for循环(性能高于enumerate), 再手动添加autoreleasepool.
本人前几篇文章中提到的一个App: 直播伴侣中就是手机端对弹幕进行高并发计算, 分词, 对比.. 使用了autoreleasepool之后明显在斗鱼弹幕服务器"炸鱼"时有所改善..欢迎Star: https://github.com/syik/BulletAnalyzer