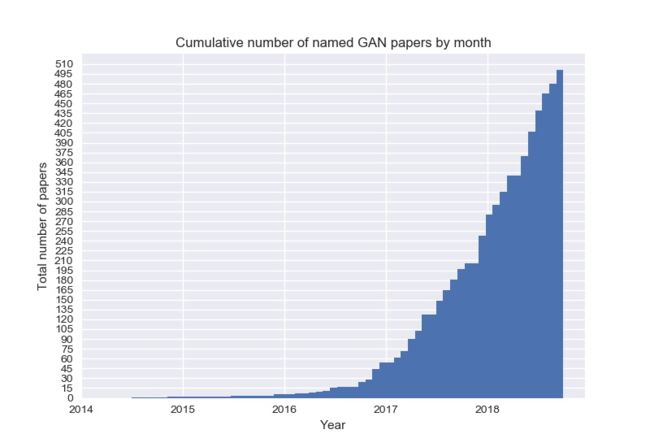
生成对抗网络(Generative Adversarial Net,GAN)是近年来深度学习中一个十分热门的方向,卷积网络之父、深度学习元老级人物LeCun Yan就曾说过“GAN is the most interesting idea in the last 10 years in machine learning”。尤其是近两年,GAN的论文呈现井喷的趋势,GitHub上有人收集了各种各样的GAN变种、应用、研究论文等,其中有名称的多达数百篇[the-gan-zoo]。作者还统计了GAN论文发表数目随时间变化的趋势,如下图所示,足见GAN的火爆程度。本节将简要介绍GAN的基本原理,并带领读者实现一个简单的生成对抗网络,用以生成动漫人物的头像。
7.1 GAN的原理简介
GAN的开山之作是被称为“GAN之父”的Ian Goodfellow发表于2014年的经典论文《Generative Adversarial Networks》,在这篇论文中他提出了生成对抗网络,并设计了第一个GAN实验——手写数字生成。
GAN的产生来自于一个灵机一动的想法:
“What I cannot create, I do not understand.”(那些我所不能创造的,我也没有真正理解它。)—— Richard Feynman
类似地。如果深度学习不能创造图片,那么它也没有真正地理解图片。当时深度学习已经开始在各类计算机视觉领域中攻城略地,在几乎所有任务中都取得了突破。但是人们一直对神经网络的黑盒模型表示质疑,于是越来越多的人从可视化的角度探索卷积网络所学习的特征和特征间的组合,而GAN则从生成学习角度展示了神经网络的强大能力。GAN解决了非监督学习中的著名问题:给定一批样本,训练一个系统能够生成类似的样本。
生成对抗网络的网络结构如下图所示,主要包含以下两个子网络:
- 生成器(generator):输入一个随机噪声,生成一张图片。
- 判别器(discriminator):判断输入的图片是真图片还是假图片。
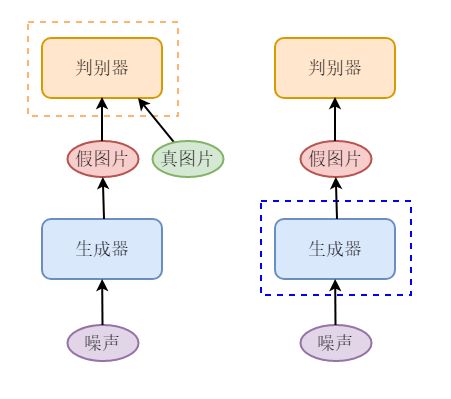
训练判别器时,需要利用生成器生成的假图片和来自真实世界的真图片;训练生成器时,只用噪声生成假图片。判别器用来评估生成的假图片的质量,促使生成器相应地调整参数。
生成器的目标是尽可能地生成以假乱真的图片,让判别器以为这是真的图片;判别器的目标是将生成器生成的图片和真实世界的图片区分开。可以看出这二者的目标相反,在训练过程中相互对抗,这也是它被称为生成对抗网络的原因。
上面的描述可能有点抽象,让我们用收藏齐白石作品(齐白石作品如下图所示)的书画收藏家和假画贩子的例子来说明。假画贩子相当于是生成器,他们希望能够模仿大师真迹伪造出以假乱真的假画,骗过收藏家,从而卖出高价;书画收藏家则希望将赝品和真迹区分开,让真迹流传于世。齐白石画虾可以说是画坛一绝,历来为世人所追捧。
在这个例子中,一开始假画贩子和书画收藏家都是新手,他们对真迹和赝品的概念都很模糊。假画贩子仿造出来的假画几乎都是随机涂鸦,而书画收藏家的鉴定能力很差,有不少赝品被他当成真迹,也有许多真迹被当成赝品。
首先,书画收藏家收集了一大堆市面上的赝品和齐白石大师的真迹,仔细研究对比,初步学习了画中虾的结构,明白画中的生物形状弯曲,并且有一对类似钳子的“螯足”,对于不符合这个条件的假画全部过滤掉。当收藏家用这个标准到市场上进行鉴定,假画基本无法骗过收藏家,假画贩子损失惨重。但是假画贩子自己仿造的赝品中,还是有一些蒙骗过关,这些蒙骗过关的赝品中都有弯曲的形状,并且有一对类似钳子的“螯足”。于是假画贩子开始修改仿造的手法,在仿造的作品中加入弯曲的形状和一对类似钳子的“螯足”。除了这些特点,其他地方例如颜色、线条都是随机画的。假画贩子制造出的第一版赝品如下所示。

当假画贩子把这些画拿到市面上去卖时,很容易就骗过了收藏家,因为画中有一只弯曲的生物,生物前面有一对类似钳子的东西,符合收藏家认定的真迹的标准,所以收藏家就把它当成真迹买回来。随机时间的推移,收藏家买回来越来越多的假画,损失惨重,于是他又闭门研究赝品和真迹之间的区别,经过反复比较对比,他发现齐白石画虾的真迹中除了有弯曲的形状、虾的触须蔓长,通身作半透明状,并且画的虾的细节十分丰富,虾的每一节之间均呈白色状。
收藏家学成之后,重新出山,而假画贩子的仿造技法没有提升,所制造出来的赝品被收藏家轻松识破。于是假画贩子也开始尝试不同的画虾手法,大多都是徒劳无功,不过在众多尝试之中,还是有一些赝品骗过了收藏家的眼睛。假画贩子发现这些仿制的赝品触须蔓长,通身作半透明状,并且画的虾的细节十分丰富,如下所示。于是假画贩子开始大量仿造这种画,并拿到市面上销售,许多都成功地骗过了收藏家。

收藏家再度损失惨重,被迫关门研究齐白石的真迹和赝品之间的区别,学习齐白石真迹的特点,提升自己的鉴定能力。就这样,通过收藏家和假画贩子之间的博弈,收藏家从零开始慢慢提升了自己对真迹和赝品的鉴别能力,而假画贩子也不断地提高自己仿造齐白石真迹的水平。收藏家利用假画贩子提供的赝品,作为和真迹的对比,对齐白石画虾真迹有了更好的鉴赏能力;而假画贩子也不断尝试,提升仿造水平,提升仿造假画的质量,即使最后制造出来的仍属于赝品,但是和真迹相比也很接近了。收藏家和假画贩子二者之间互相博弈对抗,同时又不断促使着对方学习进步,达到共同提升的目的。
在这个例子中,假画贩子相当于一个生成器,收藏家相当于一个判别器。一开始生成器和判别器的水平都很差,因为二者都是随机初始化的。训练过程分为两步交替进行,第一步是训练判别器(只修改判别器的参数,固定生成器),目标是把真迹和赝品区分开;第二步是训练生成器(只修改生成器的参数,固定判别器),为的是生成的假画能够被判别器判别为真迹(被收藏家认为是真迹)。这两步交替进行,进而生成器和判别器都达到了一个很高的水平。训练到最后,生成的虾的图片如下所示,和齐白石的真迹几乎没有差别。

下面我们来思考网络结构的设计。判别器的目标是判断输入的图片是真迹还是赝品,所以可以看成是一个二分类网络,参考第6章中Dogs vs. Cats的实验,我们可以设计一个简单的卷积网络。生成器的目标是从噪声中生成一张彩色图片,这里我们采用广泛使用的DCGAN(Deep Convolutional Generative Adversarial Networks)结构,即采用全卷积网络,其结构如下所示。网络的输入是一个100维的噪声,输出的是一个3 * 64 * 64的图片。这里的输入可以看成是一个100 * 1 * 1的图片,通过上卷积慢慢增大为4 * 4、8 * 8、16 * 16、32 * 32和64 * 64。上卷积,或称为转置卷积,是一种特殊的卷积操作,类似于卷积操作的逆运算。当卷积的stride为2时,输出相比输入会下采样到一半的尺寸;而当上卷积的stride为2时,输出会上采样到输入的两倍尺寸。这种上采样的做法可以理解为图片的信息保存于100个向量之中,神经网络根据这100个向量描述的信息,前几步的上采样先勾勒出轮廓、色调等基础信息,后几步上采样慢慢完善细节。网络越深,细节越详细。
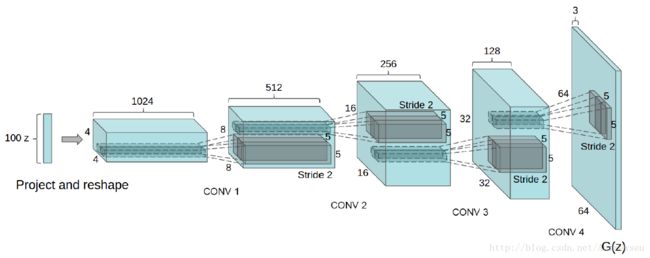
在DCGAN中,判别器的结构和生成器对称:生成器中采用上采样的卷积,判别器就采用下采样的卷积,生成器时根据噪声输出一张64 * 64 * 3的图片,而判别器则是根据输入的64 * 64 * 3的图片输出图片属于正负样本的分数(概率)。
7.2 用GAN生成动漫头像
本章所有代码及图片数据百度网盘下载,提取码:b5da。
本节将用GAN实现一个生成动漫人物头像的例子。在日本的技术博客网站上有个博主(估计是一位二次元的爱好者)
@mattya,利用DCGAN从20万张动漫头像中学习,最终能够利用程序自动生成动漫头像,生成的图片效果如下图所示。源程序是利用Chainer框架实现的,本节我们尝试利用PyTorch实现。

原始的图片是从网站中爬取的,并利用OpenCV从中截取头像,处理起来比较麻烦。这里我们使用知乎用户何之源爬取并经过处理的5万张图片。可从本书配套程序的README.MD的百度网盘链接下载所有的图片压缩包,并解压到指定的文件夹中。需要注意的是,这里的图片的分辨率是3 * 96 * 96,而不是论文中的3 * 64 * 64,因此需要相应地调整网络结构,使生成图像的尺寸为96。
我们先来看本实验的代码结构。
checkpoints/ # 无代码,用来保存模型
imgs/ # 无代码,用来保存生成的图片
data/ # 无代码,用来保存训练所需的图片
main.py # 训练和生成
model.py # 模型定义
visualize.py # 可视化工具visdom的封装
requirements.txt # 程序中用到的第三方库
README.MD # 说明
接着来看model.py中是如何定义生成器的。
# coding:utf8
from torch import nn
class NetG(nn.Module):
"""
生成器定义
"""
def __init__(self, opt):
super(NetG, self).__init__()
ngf = opt.ngf # 生成器feature map数
self.main = nn.Sequential(
# 输入是一个nz维度的噪声,我们可以认为它是一个1*1*nz的feature map
nn.ConvTranspose2d(opt.nz, ngf * 8, 4, 1, 0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# 上一步的输出形状:(ngf*8) x 4 x 4
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# 上一步的输出形状: (ngf*4) x 8 x 8
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# 上一步的输出形状: (ngf*2) x 16 x 16
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# 上一步的输出形状:(ngf) x 32 x 32
nn.ConvTranspose2d(ngf, 3, 5, 3, 1, bias=False),
nn.Tanh() # 输出范围 -1~1 故而采用Tanh
# 输出形状:3 x 96 x 96
)
def forward(self, input):
return self.main(input)
可以看出生成器的搭建相对比较简单,直接使用nn.Sequential将上卷积、激活、池化等操作拼接起来即可,这里需要注意上卷积ConvTranspose2d的使用。当kernel_size为4,stride为2,padding为1时,根据公式,输出尺寸刚好变成输入的两倍。最后一层采用kernel_size为5,stride为3,padding为1,是为了将32 * 32上采样到96 * 96,这是本例中图片的尺寸,与论文中的64 * 64的尺寸不一样。最后一层采用Tanh将输出图片的像素归一化至-1~1,如果希望归一化至0~1则需要使用Sigmoid。
接着我们来看判别器的网络结构。
class NetD(nn.Module):
"""
判别器定义
"""
def __init__(self, opt):
super(NetD, self).__init__()
ndf = opt.ndf
self.main = nn.Sequential(
# 输入 3 x 96 x 96
nn.Conv2d(3, ndf, 5, 3, 1, bias=False),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf) x 32 x 32
nn.Conv2d(ndf, ndf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*2) x 16 x 16
nn.Conv2d(ndf * 2, ndf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*4) x 8 x 8
nn.Conv2d(ndf * 4, ndf * 8, 4, 2, 1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(0.2, inplace=True),
# 输出 (ndf*8) x 4 x 4
nn.Conv2d(ndf * 8, 1, 4, 1, 0, bias=False),
nn.Sigmoid() # 输出一个数(概率)
)
def forward(self, input):
return self.main(input).view(-1)
可以看出判别器和生成器的网络结构几乎是对称的,从卷积核大小到padding、stride等设置,几乎一模一样。例如生成器的最后一个卷积层的尺度是(5,3,1),判别器的第一个卷积层的尺度也是(5,3,1)。另外,这里需要注意的是生成器的激活函数用的是ReLU,而判别器使用的是LeakyReLU,二者并无本质区别,这里的选择更多是经验总结。每一个样本经过判别器后,输出一个0~1的数,表示这个样本是真图片的概率。
在开始写训练函数前,先来看看模型的配置参数。
class Config(object):
data_path = 'data/' # 数据集存放路径
num_workers = 4 # 多进程加载数据所用的进程数
image_size = 96 # 图片尺寸
batch_size = 256
max_epoch = 200
lr1 = 2e-4 # 生成器的学习率
lr2 = 2e-4 # 判别器的学习率
beta1 = 0.5 # Adam优化器的beta1参数
gpu = True # 是否使用GPU
nz = 100 # 噪声维度
ngf = 64 # 生成器feature map数
ndf = 64 # 判别器feature map数
save_path = 'imgs/' # 生成图片保存路径
vis = True # 是否使用visdom可视化
env = 'GAN' # visdom的env
plot_every = 20 # 每间隔20 batch,visdom画图一次
debug_file = '/tmp/debuggan' # 存在该文件则进入debug模式
d_every = 1 # 每1个batch训练一次判别器
g_every = 5 # 每5个batch训练一次生成器
save_every = 10 # 没10个epoch保存一次模型
netd_path = None # 'checkpoints/netd_.pth' #预训练模型
netg_path = None # 'checkpoints/netg_211.pth'
# 只测试不训练
gen_img = 'result.png'
# 从512张生成的图片中保存最好的64张
gen_num = 64
gen_search_num = 512
gen_mean = 0 # 噪声的均值
gen_std = 1 # 噪声的方差
opt = Config()
这些只是模型的默认参数,还可以利用fire等工具通过命令行传入,覆盖默认值。另外,我们也可以直接使用opt.attr,还可以利用IDE/IPython提供的自动补全功能,十分方便。这里的超参数设置大多是照搬DCGAN论文的默认值,作者经过大量的实验,发现这些参数能够更快地训练出一个不错的模型。
当我们下载完数据之后,需要将所有图片放在一个文件夹,然后将该文件夹移动至data目录下(其确保data下没有其他的文件夹)。这种处理方式是为了能够直接使用torchvision自带的ImageFolder读取图片,而不必自己写Dataset。数据读取与加载的代码如下:
# 数据
transforms = tv.transforms.Compose([
tv.transforms.Resize(opt.image_size),
tv.transforms.CenterCrop(opt.image_size),
tv.transforms.ToTensor(),
tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
dataset = tv.datasets.ImageFolder(opt.data_path, transform=transforms)
dataloader = t.utils.data.DataLoader(dataset,
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.num_workers,
drop_last=True
)
可见,利用ImageFolder配合DataLoader加载图片十分方便。
在进行训练之前,我们还需要定义几个变量:模型、优化器、噪声等。
# 网络
netg, netd = NetG(opt), NetD(opt)
map_location = lambda storage, loc: storage
if opt.netd_path:
netd.load_state_dict(t.load(opt.netd_path, map_location=map_location))
if opt.netg_path:
netg.load_state_dict(t.load(opt.netg_path, map_location=map_location))
netd.to(device)
netg.to(device)
# 定义优化器和损失
optimizer_g = t.optim.Adam(netg.parameters(), opt.lr1, betas=(opt.beta1, 0.999))
optimizer_d = t.optim.Adam(netd.parameters(), opt.lr2, betas=(opt.beta1, 0.999))
criterion = t.nn.BCELoss().to(device)
# 真图片label为1,假图片label为0
# noises为生成网络的输入
true_labels = t.ones(opt.batch_size).to(device)
fake_labels = t.zeros(opt.batch_size).to(device)
fix_noises = t.randn(opt.batch_size, opt.nz, 1, 1).to(device)
noises = t.randn(opt.batch_size, opt.nz, 1, 1).to(device)
errord_meter = AverageValueMeter()
errorg_meter = AverageValueMeter()
在加载预训练模型时,最好指定map_location。因为如果程序之前在GPU上运行,那么模型就会被存成torch.cuda.Tensor,这样加载时会默认将数据加载至显存。如果运行该程序的计算机中没有GPU,加载就会报错,故通过指定map_location将Tensor默认加载入内存中,待有需要时再移至显存中。
下面开始训练网络,训练步骤如下。
(1)训练判别器
- 固定生成器
- 对于真图片,判别器的输出概率值尽可能接近1
- 对于生成器生成的假图片,判别器尽可能输出0
(2)训练生成器
- 固定判别器
- 生成器生成图片,尽可能让判别器输出1
(3)返回第一步,循环交替训练
epochs = range(opt.max_epoch)
for epoch in iter(epochs):
for ii, (img, _) in tqdm.tqdm(enumerate(dataloader)):
real_img = img.to(device)
if ii % opt.d_every == 0:
# 训练判别器
optimizer_d.zero_grad()
## 尽可能的把真图片判别为正确
output = netd(real_img)
error_d_real = criterion(output, true_labels)
error_d_real.backward()
## 尽可能把假图片判别为错误
noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1))
fake_img = netg(noises).detach() # 根据噪声生成假图
output = netd(fake_img)
error_d_fake = criterion(output, fake_labels)
error_d_fake.backward()
optimizer_d.step()
error_d = error_d_fake + error_d_real
errord_meter.add(error_d.item())
if ii % opt.g_every == 0:
# 训练生成器
optimizer_g.zero_grad()
noises.data.copy_(t.randn(opt.batch_size, opt.nz, 1, 1))
fake_img = netg(noises)
output = netd(fake_img)
error_g = criterion(output, true_labels)
error_g.backward()
optimizer_g.step()
errorg_meter.add(error_g.item())
if opt.vis and ii % opt.plot_every == opt.plot_every - 1:
## 可视化
if os.path.exists(opt.debug_file):
ipdb.set_trace()
fix_fake_imgs = netg(fix_noises)
vis.images(fix_fake_imgs.detach().cpu().numpy()[:64] * 0.5 + 0.5, win='fixfake')
vis.images(real_img.data.cpu().numpy()[:64] * 0.5 + 0.5, win='real')
vis.plot('errord', errord_meter.value()[0])
vis.plot('errorg', errorg_meter.value()[0])
if (epoch+1) % opt.save_every == 0:
# 保存模型、图片
tv.utils.save_image(fix_fake_imgs.data[:64], '%s/%s.png' % (opt.save_path, epoch), normalize=True,
range=(-1, 1))
t.save(netd.state_dict(), 'checkpoints/netd_%s.pth' % epoch)
t.save(netg.state_dict(), 'checkpoints/netg_%s.pth' % epoch)
errord_meter.reset()
errorg_meter.reset()
这里需要注意以下几点。
- 训练生成器时,无须调整判别器的参数;训练判别器时,无须调整生成器的参数。
- 在训练判别器时,需要对生成器生成的图片用detach操作进行计算图截断,避免反向传播将梯度传到生成器中。因为在训练判别器时我们不需要训练生成器,也就不需要生成器的梯度。
- 在训练判别器时,需要反向传播两次,一次是希望把真图片判为1,一次是希望把假图片判为0。也可以将这两者的数据放到一个batch中,进行一次前向传播和一次反向传播即可。但是人们发现,在一个batch中只包含真图片或只包含假图片的做法最好。
- 对于假图片,在训练判别器时,我们希望它输出0;而在训练生成器时,我们希望它输出1.因此可以看到一对看似矛盾的代码 error_d_fake = criterion(output, fake_labels)和error_g = criterion(output, true_labels)。其实这也很好理解,判别器希望能够把假图片判别为fake_label,而生成器则希望能把他判别为true_label,判别器和生成器互相对抗提升。
接下来就是一些可视化的代码。每次可视化使用的噪声都是固定的fix_noises,因为这样便于我们比较对于相同的输入,生成器生成的图片是如何一步步提升的。另外,由于我们对输入的图片进行了归一化处理(-1~1),在可视化时则需要将它还原成原来的scale(0~1)。
fix_fake_imgs = netg(fix_noises)
vis.images(fix_fake_imgs.detach().cpu().numpy()[:64] * 0.5 + 0.5, win='fixfake')
除此之外,还提供了一个函数,能够加载预训练好的模型,并利用噪声随机生成图片。
@t.no_grad()
def generate(**kwargs):
"""
随机生成动漫头像,并根据netd的分数选择较好的
"""
for k_, v_ in kwargs.items():
setattr(opt, k_, v_)
device=t.device('cuda') if opt.gpu else t.device('cpu')
netg, netd = NetG(opt).eval(), NetD(opt).eval()
noises = t.randn(opt.gen_search_num, opt.nz, 1, 1).normal_(opt.gen_mean, opt.gen_std)
noises = noises.to(device)
map_location = lambda storage, loc: storage
netd.load_state_dict(t.load(opt.netd_path, map_location=map_location))
netg.load_state_dict(t.load(opt.netg_path, map_location=map_location))
netd.to(device)
netg.to(device)
# 生成图片,并计算图片在判别器的分数
fake_img = netg(noises)
scores = netd(fake_img).detach()
# 挑选最好的某几张
indexs = scores.topk(opt.gen_num)[1]
result = []
for ii in indexs:
result.append(fake_img.data[ii])
# 保存图片
tv.utils.save_image(t.stack(result), opt.gen_img, normalize=True, range=(-1, 1))
完整的代码请参考本书的附带样例代码chapter/AnimeGAN。参照README.MD中的指南配置环境,并准备好数据,而后用如下命令即可开始训练:
python main.py train --gpu=True # 使用GPU
--vis=True # 使用visdom
--batch-size=256 # batch size
--max-epoch=200 # 训练200个epoch
如果使用visdom的话,此时打开http://localhost:8097就能看到生成的图像。
训练完成后,我们可以利用生成网络随机生成动漫图像,输入命令如下:
python main.py generate --gen-img='result1.5w.png'
--gen-search-num=15000
7.3 实验结果分析
实验结果如下图所示,分别是训练1个、10个、20个、30个、40个、200个epoch之后神经网络生成的动漫头像(生成的图像都在imgs文件夹下)。需要注意的是,每次生成器输入的噪声都是一样的,所以我们可以对比在相同的输入下,生成图片的质量是如何慢慢改善的。
刚开始训练的图像比较模糊(1个epoch),但是可以看出图像已经有面部轮廓。
继续训练10个epoch之后,生成的图多了很多细节信息,包括头发、颜色等,但是总体还是模糊。
训练20个epoch之后,细节继续完善,包括头发的纹理、眼睛的细节等,但还是有不少涂抹的痕迹。
训练40个epoch时,已经能看出明显的面部轮廓和细节,但还是有涂抹现象,并且有些细节不够合理,例如眼睛一大一小,面部轮廓扭曲严重。
当训练到200个epoch会后,图片的细节已经十分完善,线条更加流畅,轮廓更清晰,虽然还有一些不合理之处,但是已经有不少图片能够以假乱真了。
类似的生成动漫头像的项目还有《用DRGAN生成高清的动漫头像》,效果如下图所示。但遗憾的是,由于论文中使用的数据涉及版权问题,未能公开。这篇论文主要改进包括使用了更高质量的图片和更深、更复杂的模型。

本章讲解的样例程序还可以应用到不同的生成图片场景中,只要将训练图片改成其他类型的图片即可,例如LSUN房客图片集、MNIST手写数据集或CIFAR10数据集等。事实上,上述模型还有很大的改进空间。在这里,我们使用的全卷积网络只有四层,模型比较浅,而在ResNet的论文发表之后,也有不少研究者尝试在GAN的网络结构中引入Residual Block结构,并取得了不错的视觉效果。感兴趣的读者可以尝试将示例代码中的单层卷积改为Residual Block,相信可以取得不错的效果。
今年来,GAN的一个重大突破在于理论研究。论文《Towards Principled Methods for Training Generative Adversarial Networks》从理论的角度分析了GAN为何难以训练,作者随后在另一篇论文《Wasserstein GAN》中针对性地提出了一个更好的解决方案。但是这篇论文在部分技术细节上的实现过于随意,所以随后又有人有针对性地提出了《Improved Training of Wasserstein GANs》,更好地训练WGAN。后面两篇论文分别用PyTorch和TensorFlow实现,代码可以在GitHub上搜索到。笔者当初也尝试用100行左右的代码实现了Wasserstein GAN,该兴趣的读者可以去了解。
随着GAN研究的逐渐成熟,人们也尝试把GAN用于工业实际问题之中,而在众多相关论文中,最令人深刻的就是《Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks》,论文中提出了一种新的GAN结构称为CycleGAN。CycleGAN利用GAN实现风格迁移、黑白图像彩色化,以及马和斑马互相转化等,效果十分出众。论文的作者用PyTorch实现了所有的代码,并开源在GitHub上,感兴趣的读者可以自行查阅。
本章主要介绍GAN的基本原理,并带领读者利用GAN生成动漫头像。GAN有许多变种,GitHub上有许多利用PyTorch实现的各种GAN,感兴趣的读者可以自行查阅。