第11课-RNNs和TensorFlow语言建模
CS20si课程资料和代码Github地址
- 第11课-RNNs和TensorFlow语言建模
- 从前馈网络到循环神经网络(RNNs)
- 时间上反向传播(BPTT)
- 门控循环单元(LSTM和GRU)
- 应用: 语言模型
从前馈网络到循环神经网络(RNNs)
在过去的课程中,我们已经看到了前馈网络和卷积神经网络是如何取得极好的结果的。它们的表在很多不同的任务上和人类相当,甚至超过人类。
尽管它们看起来很神奇,但是这些模型仍然有很大的局限性。人类远不止能做线性和逻辑回归,或者分辨不同的物体。我们可以理解、交流和创造。我们处理的输入不仅是单个数据点,还有富含信息的连续数据,它在时间依赖上很复杂。我们用的语言是连续的,我们看的电视节目也是连续的。现在的问题是:我们如何使我们的模型能够处理各种复杂的输入序列,就像人类一样。
RNNs是为了处理连续信息而创建的,简单的循环网络(SRN)最初是由Jeff Elman与1990年在一篇题为“Finding structure in time”的论文中提出的。
RNNs和前馈网络一样是建立在相同的计算单元即神经元上的。然而它们的不同之处是这些神经元的连接方式。前馈网络是分层组织的,信号在一个方向上传播,不允许环的存在。相反,RNNs允许神经元连接它们自己,这样就使时间标记能被考虑进来,因为上一步的神经元能影响当前步的神经元。
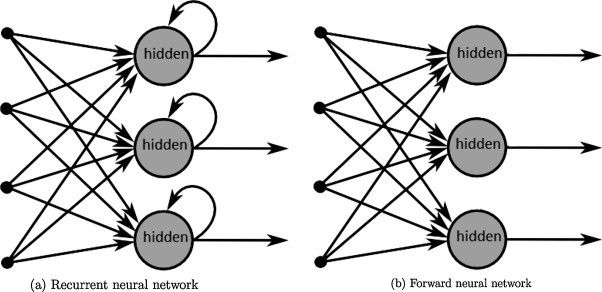
Elman的SRN就是这样做的,在他的早期模型中,当前步的隐层是一个包含当前步输入和上一步隐层的函数。在Elman研究的若干年前,Jordan开发了一种简单的网络,不使用将上一步隐层作为输入,而使用上一步隐层的输出。下面是一步步的比较这两种早期的简单循环网络(SRN, Simple recurrent networks)。

人们经常把RNNs描绘成与自己相连的神经元,但你可能会发现,当这些神经元展开时更容易理解它们,每个神经元代表一个时间步。例如,在自然语言处理(NLP)的上下文中,如果你的输入是由10个符号组成的句子,每个时间步对应一个符号。所有的时间步共享权值(因为它们本质上是同一个神经元),这样减少了总的参数个数。

大多数人认为RNNs是在NLP上下文中出现的,因为语言是高度连续的。第一个RNNs确实是为NLP任务构建的,现在很多NLP任务都是使用RNNs来解决的。但是,它也可以用于处理音频、图像和视频的任务。例如,您可以训练一个RNNs在数据集MNIST上执行对象识别任务,将每个图像视为一个像素序列。
时间上反向传播(BPTT)
在前馈或卷积神经网络中,误差从损失反向传播到所有层。这些误差用于根据我们指定的更新规则(梯度下降,Adam,…)更新参数(权重,偏差)以减少损失。
在一个循环神经网络中,误差被从损失中反向传播到所有的时间步。两个主要的区别是:
- 前馈网络中的每个层都有自己的参数,而RNNs中的所有时间步都共享相同的参数。我们用所有相关的时间步骤中的梯度和来更新每个训练样本/批次的参数。
- 前馈网络有固定数量的层,而RNN可以根据序列的长度拥有任意数量的时间步数。
对于第2条,这意味着如果你的序列很长(例如,一个文本文档中1000个字对应的1000个时间步),那么通过所有这些步骤进行反向传播的过程在计算上是非常昂贵的。另一个问题是,这可能导致梯度指数增加或减少,取决于它们的值是大还是小,从而导致梯度消失或爆炸。Denny Britz有一篇关于BPTT和梯度爆炸/消失的很棒的博客文章。
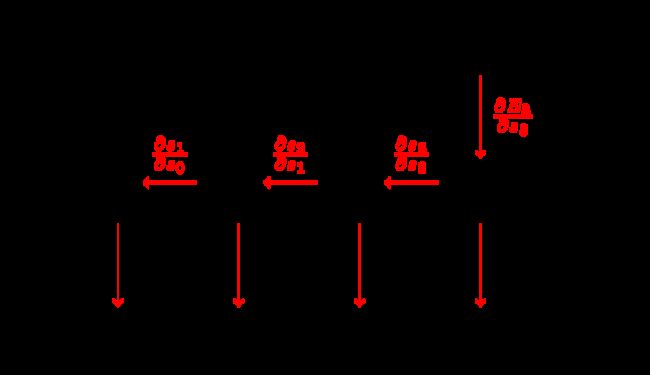
为了避免在所有的时间步骤中都要进行完整的参数更新,我们通常会限制时间步的数量,从而导致所谓截断的BPTT。这加快了每次更新的计算速度。缺点是,我们只能将误差反向传播回有限的时间步,而且网络无法从一开始就学习依赖关系。
在TensorFlow中,使用网络的展开版本创建RNNs,这意味着在执行计算之前指定固定数量的时间步数,它只能处理那些明确时间步数的输入。例如,一个段落可能有20个单词,而另一个段落可能有200个单词。通常的做法是把数据分成不同的buckets,将相同长度的样本放入同一个bucket中。一个bucket中的所有样本要么被填充为零标记,要么被截断,具有相同的长度。
门控循环单元(LSTM和GRU)
在实践中,RNNs被证明在捕获长时依赖方面非常糟糕。为了解决这个缺点,人们使用了长短期记忆(LSTM)。LSTM在过去3年的崛起让它看起来像是一个新的想法,但这其实是一个很古老的概念。这是两位德国研究者Sepp Hochreiter 和 Jürgen Schmidhuber在90年代中期提出的,为了解决梯度消失问题。和许多人工智能的想法一样,LSTM直到最近几年才变得流行起来,这要归功于不断增长的计算能力使它能够工作。

LSTM单元使用所谓的门机制。它们包括4个门,通常表示为i,o,f和\tilde{c},对应于输入,输出,忘记和候选/新的记忆。
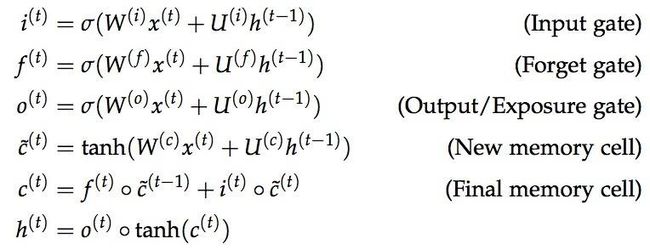
似乎学术界的每个人都有一个不同的图表来可视化LSTM的单元,所有这些都不可避免的令人困惑。我觉得比较容易混淆的一个图是Mohammadi等人为CS224D的课堂笔记创建的。
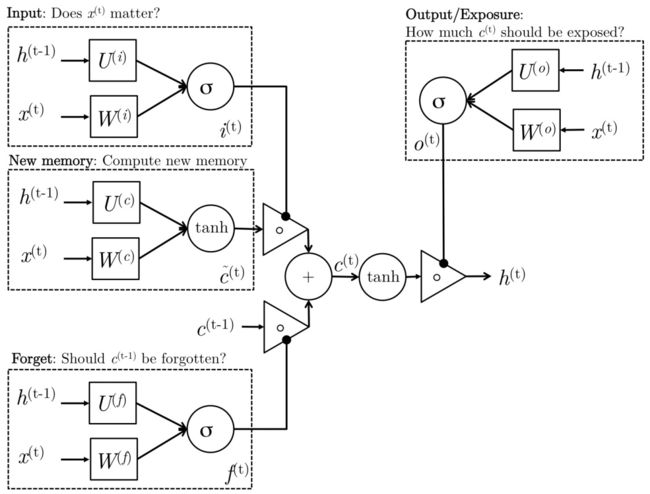
我们可以直观的将门看作是在每个时间步上控制什么信息可以从单元输入和输出。所有的门都有相同的维度。
- 输入门: 决定有多少当前输入能通过。
- 遗忘门: 定义要考虑的前一个状态的多少。
- 候选门: 与原始RNN类似,该门基于先前的隐藏状态和当前输入计算候选隐藏状态。
- 最终记忆单元: 单元的内部内存将候选隐藏状态与输入/忘记门信息组合在一起。
- 输出门: 定义向要下一个时间步输出最终记忆单元中的多少隐藏状态。
LSTM并不是唯一一种用于提高RNNs的长时依赖问题的门机制。门控循环单元(GRU)采用了类似的机制,并具有巨大的简化性。它将LSTM的遗忘门和输入门组合成一个“更新门”,还合并候选门和隐藏状态。GRU要比标准的LSTM简单得多,但是它的性能已被证明与LSTM在几个基准测试任务上的性能相当。GRU的简单性也意味着理论上需要较少的计算时间,然而与LSTM相比,GRU的运行时间并没有明显的改善。

在TensorFlow中,我更喜欢使用GRU,因为它不那么麻烦。TensorFlow中的GRU单元为每个层输出一个隐藏状态,而LSTM单元输出候选状态和隐藏状态。
应用: 语言模型
给定一个单词序列,我们要预测下一个单词的分布。这种预测下一个单词的能力给了我们一个生成模型,它允许我们通过从输出概率中抽取样本来生成新的文本。根据我们的训练数据,我们可以生成各种各样的东西。你可以阅读Andrej Karpathy的博客文章,它们是关于使用char-RNN获得的一些有趣的结果。
在构建语言模型时,我们的输入通常是一系列单词(或者字符,比如在char-RNN中),输出是下一个词的分布。
在这个练习中,我们将在两个数据集上构建一个char-RNN模型:唐纳德•特朗普(Donald Trump)的推特和arvix摘要。arvix摘要数据集包含20,466个单独的摘要,大部分在500-2000个字符范围内。唐纳德•特朗普的推特数据集包含了截至2018年2月15日的所有推特,大部分推特都被过滤掉了。总共有19,469条推文,每条都少于140个字符。我们做了一些数据预处理:用HTTP替换所有URL并添加结束标记E。
下面是机器处理特朗普推特的一些输出:
I will be interviewed on @foxandfriends tonight at 10:00 P.M. and the #1 to construct the @WhiteHouse tonight at 10:00 P.M. Enjoy HTTP
I will be interviewed on @foxandfriends at 7:00 A.M. and the only one that we will MAKE AMERICA GREAT AGAIN #Trump2016 HTTP HTTP
No matter the truth and the world that the Fake News Media will be a great new book #Trump2016 HTTP HTTP
Great poll thank you for your support of Monday at 7:30 A.M. on NBC at 7pm #Trump2016 #MakeAmericaGreatAgain #Trump2016 HTTP HTTP
The Senate report to our country is a total disaster. The American people who want to start like a total disaster. The American should be the security 5 star with a record contract to the American peop
.@BarackObama is a great president of the @ApprenticeNBC
No matter how the U.S. is a complete the ObamaCare website is a disaster.
下面是机器处理arvix摘要的一些输出:
“Deep learning neural network architectures can be used to best developing a new architectures contros of the training and max model parametrinal Networks (RNNs) outperform deep learning algorithm is easy to out unclears and can be used to train samples on the state-of-the-art RNN more effective Lorred can be used to best developing a new architectures contros of the training and max model and state-of-the-art deep learning algorithms to a similar pooling relevants. The space of a parameter to optimized hierarchy the state-of-the-art deep learning algorithms to a simple analytical pooling relevants. The space of algorithm is easy to outions of the network are allowed at training and many dectional representations are allow develop a groppose a network by a simple model interact that training algorithms to be the activities to maximul setting, …”
有关代码,请参阅课程的GitHub。你还可以参考课堂幻灯片了解更多有关代码的信息。