SQL基础应用
SQL语句自动补全
yum install python-pip -y
pip install mycli
SQL的介绍
SQL-92标准
SQL-99标准
 image
image
SQL常用分类
DDL 数据定义语言
DCL 数据控制语言
DML 数据操作语言
DQL 数据查询语言
表的核心属性介绍
列的属性
数据类型
数字类型
tinyint -128-127
int -2^41-2^31-1
字符类型
 image
image
char(10) 字符长度
varchar(10)
说明:以上数据类型,定义最长字符长度,用括号中的数字表示

 image
image
如何选择?
变长列, 推荐varchawr
定长列, 推荐char image
image
注意:
对于char(10)和varchar(10)的数据lix
括号中表示的是,最多的字符个数
具体占用字节长度如下:
基础字符:
a
1
?
中文:
王
王
王
enum('bj','sh','sz',...)
枚举类型
时间类型
datetime
timestamp

二进制类型(一般不使用)
neo4J 图片,视频等存储
约束
not null 非空
unique key 唯一
primary key 主键(非空且唯一)
说明:
1.一个表有且一个主键列,最好是一个无关列数字列,一般会在表中设置自增长的id列
2.尽量每个列非空,如果无法保证,可以追加默认值
3.手机号,身份证号,银行卡号...种类的列设定为UK
其他属性
unsigned 无符号,一般是在int或tinyint后天就的附加属性
default 设定默认值
auto_increment 数字列自增长
commnet 注释信息
表的属性
存储引擎
engine=innodb
字符集及校对规则
字符集:
utf8 中文字符占3个字符
utf8mb4 中文字符占4个字符
emoji 字符支持 拼音 ü
校对(排序)规则:
collation
DDL语句
库定义
建库
CREATE DATABASE school CHARSET utf8mb4;
 image
image
建库的规范:
1.库名是小写
2.库名不能是数字开头
3.库名要和业务有关
4.建库时要添加字符集
删库
# 危险操作!!仅用来学习
ALTER TABLE xs DROP shouji;
ALTER TABLE xs DROP 微信;
ALTER TABLE xs DROP QQ;
 image
image
改库
alter database oldboy charset utf8mb4;
查库(不属于DDL)
show databases;
show create database oldboy;
表定义
建表
建表规范:
- 表明小写,无数字开头,与业务有关
- 必须要有主键,一般是一个自增长的无关列
- 选择合适的数据类型,字符长度要适中
- 每个列都非空,并设定默认值
- 吗每个列必须要有注释
- 必须设置存储引擎和字符集
 image
image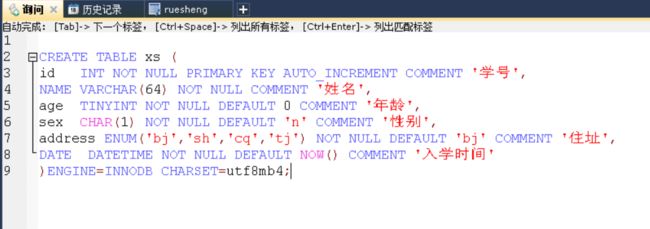 image
image
CREATE TABLE xs (
id INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
NAME VARCHAR(64) NOT NULL COMMENT '姓名',
age TINYINT NOT NULL DEFAULT 0 COMMENT '年龄',
sex CHAR(1) NOT NULL DEFAULT 'n' COMMENT '性别',
address ENUM('bj','sh','cq','tj') NOT NULL DEFAULT 'bj' COMMENT '住址',
DATE DATETIME NOT NULL DEFAULT NOW() COMMENT '入学时间'
)ENGINE=INNODB CHARSET=utf8mb4;
改表
添加 删除列
1. 在xs表中添加手机号列 shouji
 image
image
ALTER TABLE xs ADD shouji CHAR(11) NOT NULL UNIQUE KEY COMMENT '手机号'
2.在xs表中,sex列后添加“微信”列
 image
image
ALTER TABLE xs ADD 微信 VARCHAR(64)NOT NULL UNIQUE KEY COMMENT '微信号' AFTER sex;
3.在第一列位置添加QQ号列
ALTER TABLE xs ADD QQ VARCHAR(64) NOT NULL UNIQUE KEY COMMENT 'QQ号' FIRST;
 image
image
4.修改列属性
 image
image
#只改属性,不该列名
ALTER TABLE xs MODIFY ssname VARCHAR(64) NOT NULL COMMENT '姓名';
#列名和属性都修改
ALTER TABLE xs CHANGE sname ssname VARCHAR(32) NOT NULL COMMENT '姓名';
删表
比较危险!仅用来学习
drop table school; 表定义和数据全部删除
truncate table xs; 清空表的区,数据清空,表定义保留
查表
show tables;
show create table xs;
desc xs;
小结
create database oldboy charset utf8mb4; 建库
drop database oldboy; 删库
alter database oldboy charset utf8; 修改
show create database oldboy; 查看库
show databases; 查看库
#建表
create table 表名(
列1 数据类型 约束 其他属性,
列2 数据类型 约束 其他属性,
列3 数据类型 约束 其他属性,
列4 数据类型 约束 其他属性,
)engin=innodb charset=utf8 comment 'xxx';
#修改表
alter table stu add qq varchar(64) not null unique key comment 'xxx';
drop table stu; 删除表
truncate table stu; 删除表
desc stu; 查看表
show tables; 查看所有表
show create table stu; 查看表
DCL语句
grant 权限 on 范围 to 用户 identified by 密码;
revoke 权限 on 范围 from 用户;
DML语句
用做表的数据行的 增 删 改 查
insert 增
最规范的录入方法
INSERT INTO xs(id,NAME,age,sex,address,DATE)
VALUES
(1,'张三',18,'m','bj',NOW())
简化写法
INSERT INTO xs VALUES(2,'lis',19,'f','sh',NOW());
 image
image
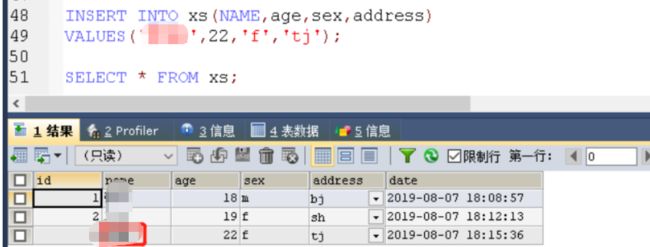
针对性的录入数据
INSERT INTO xs(NAME,age,sex,address)
VALUES('亚伟',22,'f','tj');
批量录入数据
INSERT INTO xs(NAME,age,sex,address)
VALUES
('a',21,'f','tj'),
('b',23,'f','tj'),
('c',25,'m','sh');
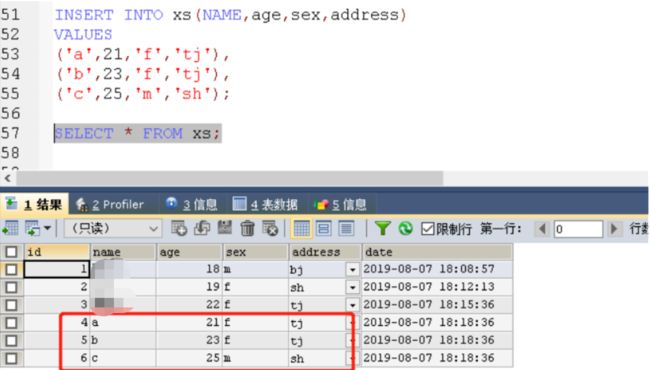 image.png
image.png
update 改
UPDATE xs SET age=20 ;
注意
update 语句必须要加where条件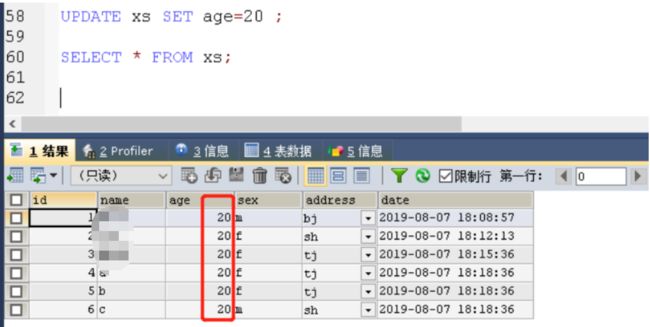 image.png
image.png
delete 删
#删除第四列
DELETE FROM xs WHERE id=4;
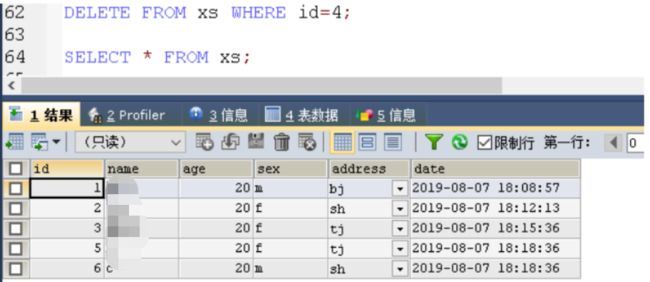 image.png
image.png
试题:以下语句的区别?
delete from t1;
truncate table t1;
答:
truncate:
(1) 是DDL语句,清空整表的所有数据,安装区来删除的,属于物理删除,性能高
(2) 表所占用的空间,会立即释放delete:
(1) 是DML语句,清空整表的所有数据,安装行来删除的,属于逻辑删除,性能低
(2) 表所占用的空间,不会立即释放
使用update替代delete实现伪删除
添加一个状态列state
ALTER TABLE xs ADD state TINYINT NOT NULL DEFAULT 1 ;
用update替代delete
原语句:
DELETE FROM xs WHERE id=6;
改写后:
UPDATE xs SET state=0 WHERE id=6;
业务语句进行调整
select * from xs;
改为:
select * from xs where state=1;
DQL基础应用
select 语句应用
select(单表)的执行逻辑
select 列1,列2
from 表
where 条件
group by 条件
having 条件
order by 条件
limit 条件
select单独使用的情况(MySQL独家)
(1) select @@参数名;
SELECT @@datadir;
SELECT @@port;
SELECT @@socket;
SELECT @@innodb_flush_log_at_trx_commit; #必会参数
SHOW VARIABLES LIKE '%trx%';
(2) select 函数();
SELECT NOW();
USE mysql;
SELECT DATABASE();
SELECT USER();
SELECT 16*16;
SELECT CONCAT("hello world");
SELECT CONCAT(USER,"@",HOST) FROM mysql.user;
SELECT GROUP_CONCAT(USER,"@",HOST) FROM mysql.user;
from 子句语句
USE world; #练习前进入world库
SHOW TABLES;
city 城市
country 国家
countrylanguage 国家使用的语言
=============================
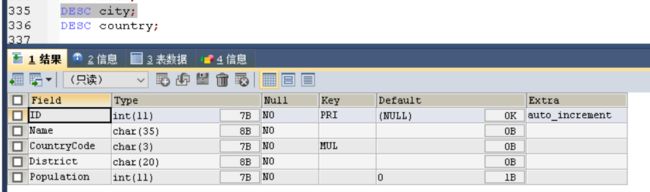
DESC city;
id 主键
NAME 城市名
countrycode 国家代码(USA,CHN,JPN)
district 省,州
population 城市人口数
=============================
SELECT * FROM city; #相当于cat /etc/passwd
SELECT NAME,countrycode FROM city; #相当于awk 3
where子句应用
相当于grep命令,过滤
等值查询 grep "root"
-- 查询中国城市的信息
SELECT * FROM city WHERE countrycode='CHN';
不等值查询
-- 查询人口数量少于100人的
SELECT * FROM city WHERE population<100;
-- 查询ID小于10的城市信息
SELECT * FROM city WHERE id<10;
-- 查询不是中国的城市信息(尽量不使用不等于,可能不走索引)
SELECT * FROM city WHERE countrycode!='CHN';
SELECT * FROM city WHERE countrycode<>'CHN';
模糊查询
-- 查询国家代号为CH开头的城市信息
SELECT * FROM city WHERE countrycode LIKE 'CH%';
-- 查询国家代号包含CH的城市信息(避免使用)
SELECT * FROM city WHERE countrycode LIKE '%CH%';
-- 注意:避免使用 like 中 前面带%的模糊查询
逻辑连接符(and,or)
-- 查询中国城市人口超过500万的城市信息
SELECT *
FROM city
WHERE countrycode='CHN' AND population>5000000
-- 将peking修改为beijing
UPDATE city SET NAME='beijing' WHERE id='1891';
-- 查看山东省或河北省的城市信息
SELECT *
FROM city
WHERE district='shangdong' OR district='hebei';
-- 查询人口数量在500w-600w的城市
SELECT *
FROM city
WHERE population>5000000 AND population<6000000;
where 配合 between and 的使用
-- 查询人口数在100w-200w区间的城市信息(包含头尾)
SELECT * FROM city
WHERE population BETWEEN 1000000 AND 2000000;
where 配置 in 使用
-- 查看山东省或河北省的城市信息
SELECT * FROM city
WHERE district IN('shandong','hebei');
group by 子句+聚合函数应用
什么是分组?
按照某个列进行分组
常用的聚合函数
COUNT() 计数
MAX() 最大值
MIN() 最小值
AVG() 平均值
SUM() 求和
GROUP_CONCAT() 列转行
例子
-- 统计每个国家的城市个数
SELECT countrycode,COUNT(id) FROM city
GROUP BY countrycode
-- 统计每个国家的总人口数量
SELECT countrycode,SUM(population) FROM city
GROUP BY countrycode
-- 统计中国每个省的城市个数及省总人口数
SELECT district,COUNT(id),SUM(population) FROM city
WHERE countrycode IN('CHN')
GROUP BY district;
-- 统计各个国家的城市名列表(列转行)
SELECT countrycode,GROUP_CONCAT(NAME) FROM city
GROUP BY countrycode;
having语句 后过滤
-- 统计中国,每个省的,城市个数,省总人口数
-- 只显示人口总数大于800w的省
SELECT district,COUNT(id),SUM(population)
FROM city
WHERE countrycode IN('CHN')
GROUP BY district
HAVING SUM(Population)>8000000;
order by 子句
实现先排序,by后添加条件列
-- 以上例子,将人口数进行排序输出
SELECT district,COUNT(id),SUM(population)
FROM city
WHERE countrycode IN('CHN')
GROUP BY district
HAVING SUM(Population)>8000000
ORDER BY SUM(Population) DESC;
-- 查询中国所有城市信息,并以人口数降序输出
SELECT * FROM city WHERE countrycode='CHN'
ORDER BY Population DESC;
limit 应用
-- 查询中国所有城市信息,并以人口数降序输出,只显示前五名
SELECT * FROM city WHERE countrycode='CHN'
ORDER BY Population DESC
LIMIT 5;
-- 跳过前N行,显示M行(N和M代表的是数字)
LIMIT M offet N
LIMIT N M
distinct 应用
-- 查询所有的国家代号信息
SELECT DISTINCT countrycode FROM city;
union 与 union all
-- 查看山东省或河北省的城市信息
SELECT *
FROM city
WHERE District='shandong' OR district='hebei';
-- 改写:
SELECT *
FROM city
WHERE district='shandong'
UNION ALL
SELECT *
FROM city
WHERE district='hebei';
面试题:
UNION 和 UNION ALL 的区别?
union带有去重复功能,UNION ALL 没有去重复
多表查询
准备环境
多表连接查询的环境准备:
use school
student :学生表
sno: 学号
sname:学生姓名
sage: 学生年龄
ssex: 学生性别
teacher :教师表
tno: 教师编号
tname: 教师名字
course :课程表
cno: 课程编号
cname:课程名字
tno: 教师编号
score :成绩表
sno: 学号
cno: 课程编号
score: 成绩
-- 项目构建
drop database school;
CREATE DATABASE school CHARSET utf8;
USE school
CREATE TABLE student(
sno INT NOT NULL PRIMARY KEY AUTO_INCREMENT COMMENT '学号',
sname VARCHAR(20) NOT NULL COMMENT '姓名',
sage TINYINT UNSIGNED NOT NULL COMMENT '年龄',
ssex ENUM('f','m') NOT NULL DEFAULT 'm' COMMENT '性别'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE course(
cno INT NOT NULL PRIMARY KEY COMMENT '课程编号',
cname VARCHAR(20) NOT NULL COMMENT '课程名字',
tno INT NOT NULL COMMENT '教师编号'
)ENGINE=INNODB CHARSET utf8;
CREATE TABLE sc (
sno INT NOT NULL COMMENT '学号',
cno INT NOT NULL COMMENT '课程编号',
score INT NOT NULL DEFAULT 0 COMMENT '成绩'
)ENGINE=INNODB CHARSET=utf8;
CREATE TABLE teacher(
tno INT NOT NULL PRIMARY KEY COMMENT '教师编号',
tname VARCHAR(20) NOT NULL COMMENT '教师名字'
)ENGINE=INNODB CHARSET utf8;
INSERT INTO student(sno,sname,sage,ssex)
VALUES (1,'zhang3',18,'m');
INSERT INTO student(sno,sname,sage,ssex)
VALUES
(2,'zhang4',18,'m'),
(3,'li4',18,'m'),
(4,'wang5',19,'f');
INSERT INTO student
VALUES
(5,'zh4',18,'m'),
(6,'zhao4',18,'m'),
(7,'ma6',19,'f');
INSERT INTO student(sname,sage,ssex)
VALUES
('oldboy',20,'m'),
('oldgirl',20,'f'),
('oldp',25,'m');
INSERT INTO teacher(tno,tname) VALUES
(101,'oldboy'),
(102,'hesw'),
(103,'oldguo');
DESC course;
INSERT INTO course(cno,cname,tno)
VALUES
(1001,'linux',101),
(1002,'python',102),
(1003,'mysql',103);
DESC sc;
INSERT INTO sc(sno,cno,score)
VALUES
(1,1001,80),
(1,1002,59),
(2,1002,90),
(2,1003,100),
(3,1001,99),
(3,1003,40),
(4,1001,79),
(4,1002,61),
(4,1003,99),
(5,1003,40),
(6,1001,89),
(6,1003,77),
(7,1001,67),
(7,1003,82),
(8,1001,70),
(9,1003,80),
(10,1003,96);
SELECT * FROM student;
SELECT * FROM teacher;
SELECT * FROM course;
SELECT * FROM sc;
 image
image
加入多表查询
作用
业务需要带的数据来自多张表时
多表连接类型
内连接☆☆☆☆☆
外连接☆☆☆
全连接
笛卡尔
内连接的类型
传统连接 where
自连接
join uing ☆☆
join on ☆☆☆☆☆
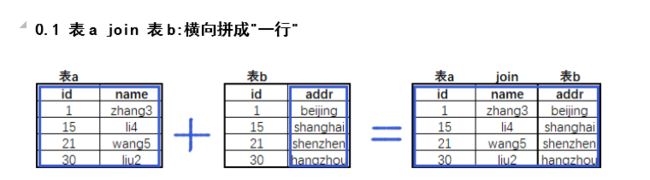
加入的语法
表A和表B横向拼成一行
 image
image
查询张三的家庭住址
SELECT A.name,B.address FROM
A JOIN B
ON A.id=B.id
WHERE A.name='zhangsan'
#语法
select xxx
from A
join B
on A.xxx= B.yyy
where
group by
having
order
limit
查询一下世界上人口数量小于100人的城市名和国家名
SELECT b.name ,a.name ,a.population
FROM city AS a
JOIN country AS b
ON b.code=a.countrycode
WHERE a.Population<100
多表连接的套路:
1。根据需求找到关联表
2.找到表与表的关联列
多表连接案例
#进入world库练习
use world;
 image
image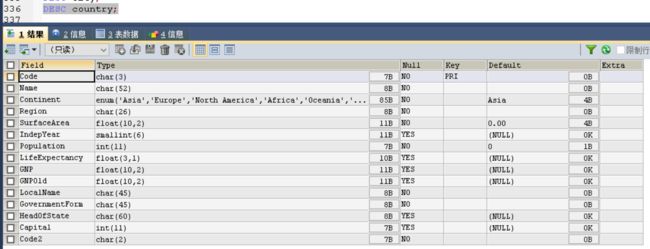 image
image
查询一下世界上人口数量小于100人的城市名,国家名,国土面积和人口数
SELECT country.name,country.SurfaceArea,city.name,city.Population
FROM city
JOIN country
ON city.CountryCode=country.code
WHERE city.Population<100;
打开学校表
 image
image
查询zhangs学习了几门课程
SELECT student.sname,COUNT(sc.cno)
FROM student
JOIN sc
ON student.sno=sc.sno
WHERE student.sname='zhang3';

统计zhang3学习课程名称
SELECT student.sname,GROUP_CONCAT(course.cname)
FROM student
JOIN sc
ON student.sno=sc.sno
JOIN course
ON sc.cno=course.cno
WHERE student.sname='zhang3'
GROUP BY student.sno;

老师教了学生的个数
SELECT teacher.tname,GROUP_CONCAT(student.sname),COUNT(student.sname)
FROM student
JOIN sc
ON student.sno=sc.sno
JOIN course
ON sc.cno=course.cno
JOIN teacher
ON course.tno=teacher.tno
WHERE teacher.tname='oldguo'
GROUP BY teacher.tno;
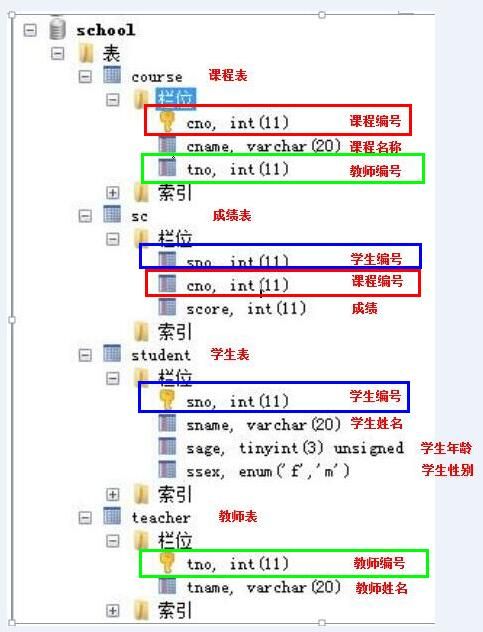
每位老师所教课程的平均分,并按平均分排序
SELECT teacher.tname,AVG(sc.score)
FROM teacher
JOIN course
ON teacher.tno=course.tno
JOIN sc
ON course.cno=sc.cno
GROUP BY teacher.tno
ORDER BY AVG(sc.score) DESC;
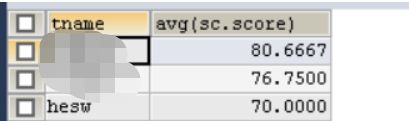
2.2.5查询某老师所教的不及格的学生姓名
SELECT teacher.tname,student.sname,sc.score
FROM teacher
JOIN course
ON teacher.tno=course.tno
JOIN sc
ON course.cno=sc.cno
JOIN student
ON sc.sno=student.sno
WHERE teacher.tname='某老师' AND sc.score<60;
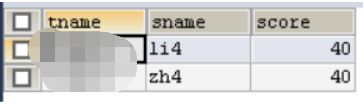
查询所有老师所教学生不及格的信息
SELECT teacher.tname,GROUP_CONCAT(student.sname)
FROM teacher
JOIN course
ON teacher.tno=course.tno
JOIN sc
ON course.cno=sc.cno
JOIN student
ON sc.sno=student.sno
WHERE sc.score<60
GROUP BY teacher.tname

别名的使用
SELECT别名。列
FROM表表别名
别名别。列
别名别。列有别
列别名
由列别名
表别名
SELECT a.tname,GROUP_CONCAT(d.sname)
FROM teacher AS a
JOIN course AS b
ON a.tno=b.tno
JOIN sc AS c
ON b.cno=c.cno
JOIN student AS d
ON c.sno=d.sno
WHERE c.score<60
GROUP BY a.tname
说明:表别名一般是在FROM的表的表名,或者加入后的表的别名
在WHERE,GROUP BY,选择后的列,拥有,ORDER BY
列别名
SELECT a.tname AS 老师 ,GROUP_CONCAT(d.sname) AS 学生
FROM teacher AS a
JOIN course AS b
ON a.tno=b.tno
JOIN sc AS c
ON b.cno=c.cno
JOIN student AS d
ON c.sno=d.sno
WHERE c.score<60
GROUP BY a.tname
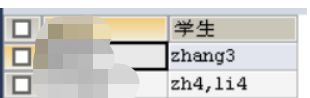
说明:列别名一般是在选后的列,定义的别名
- 作用:
- 1.结果集显示会以别名形式展示
- 2.在和和秩序由中可以调用列别名
-- 例子:每位老师所教课程的平均分,并按平均分排序
SELECT a.tname AS 老师,AVG(c.score) AS 平均分
FROM teacher AS a
JOIN course AS b
ON a.tno=b.tno
JOIN sc AS c
ON b.cno=c.cno
GROUP BY a.tno
ORDER BY 平均分;
外链接简介☆☆☆
left join左链接
右加入右链接
A left join B
on A.x=B.y
where
A left join B
on A.x=B.y
and
结论:
- 多表连接中,小标驱动大表
- 通过left join强制选定驱动表
=================================
工作中还需要学习的内容:
1。内置函数
2.存储过程
3 。函数
4.触发器
5.事件
6.视图
7.JSON语法
=================================
元数据获取
元数据介绍
“基表”:数据字典信息(列结构frm),系统状态,对象状态
相当于linux中的inode
DDL DCL语句修改元数据
show语句(MySQL独家)
help show;
show databases; #查看所有数据库
show tables; #查看当前库的所有表
SHOW TABLES FROM #查看某个指定库下的表
show create database world #查看建库语句
show create table world.city #查看建表语句
show grants for root@'localhost' #查看用户的权限信息
show charset; #查看字符集
show collation #查看校对规则
show processlist; #查看数据库连接情况
show index from #表的索引情况
show status #数据库状态查看
SHOW STATUS LIKE '%lock%'; #模糊查询数据库某些状态
SHOW VARIABLES #查看所有配置信息
SHOW variables LIKE '%lock%'; #查看部分配置信息
show engines #查看支持的所有的存储引擎
show engine innodb status\G #查看InnoDB引擎相关的状态信息
show binary logs #列举所有的二进制日志
show master status #查看数据库的日志位置信息
show binlog evnets in #查看二进制日志事件
show slave status \G #查看从库状态
SHOW RELAYLOG EVENTS #查看从库relaylog事件信息
desc (show colums from city) #查看表的列定义信息
information_schema.tables虚拟库
information_schema ---> VIEWS视图
use information_schema;
show tables;
CREATE VIEW test AS SELECT
country.name AS co_name,country.SurfaceArea,city.name AS ci_name,city.Population
FROM city JOIN country
ON city.CountryCode=country.code
WHERE city.Population<100;
SELECT * FROM test;
TABLES作用和结构
作用:存储整个数据库中,所有表的元数据的查询方式。
desc tables;
TABLE_SCHEMA 表所在的库
TABLE_NAME 表名
ENGINE 表的引擎
TABLE_ROWS 表的行数
AVG_ROW_LENGTH 平均行长度
INDEX_LENGTH 索引长度
例子
1.查询world 数据库下的所有表名
use world;
show tables; && show tables from world;
2.查询整个数据库下的所有表名
select table_name from information_schema.tables;
3.查询所有InnoDB引擎的表
SELECT table_schema,table_name,ENGINE FROM information_schema.tables
WHERE ENGINE='innodb';
4.统计每张表的实际的空间占用大小情况
(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)
SELECT table_name,AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH
FROM information_schema.tables;
5.统计每个库的空间使用大小情况
SELECT table_schema,SUM(AVG_ROW_LENGTH*TABLE_ROWS+INDEX_LENGTH)/1024/1024
FROM information_schema.tables
GROUP BY table_schema;
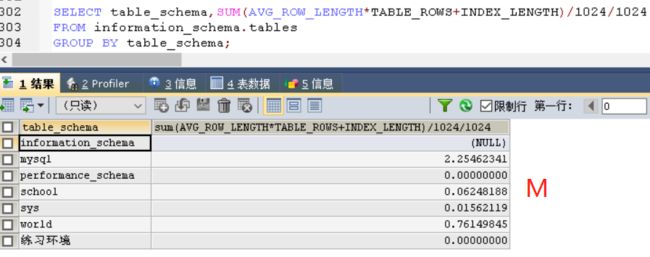 image
image
中小型公司:数据量大小一般在300G 500G
中大型公司:数据量大小一般在2T 10T
6.对MySQL的数据库进行分库分表备份
mysqldump -uroot -p123 world city >/backup/world_city.sql
SELECT CONCAT("mysqldump -uroot -p123 ",table_schema ," ",table_name ," >/backup/",table_schema,
"_",table_name,".sql")
FROM information_schema.tables INTO OUTFILE '/tmp/bak.sql';
添加配置
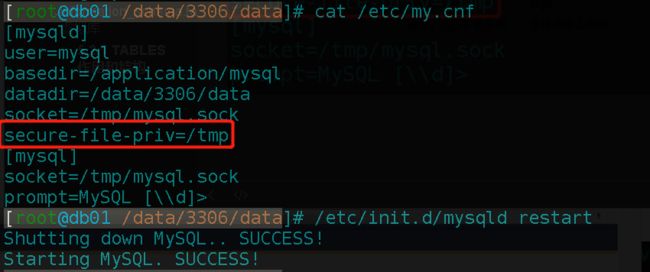 image
image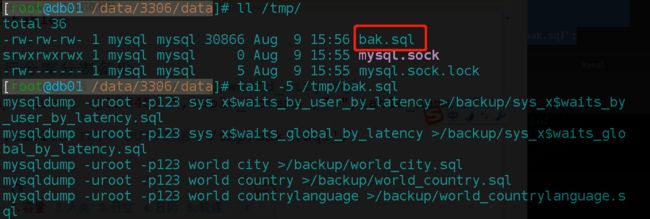 image
image
7.模仿模板语句,批量生成对world数据库下的表操作语句
alter table world.city discard tablespace;
SELECT CONCAT("alter table ",table_schema,".",table_name," discard tablespace;")
FROM information_schema.tables
WHERE table_schema='world'
INTO OUTFILE '/tmp/discard.sql';
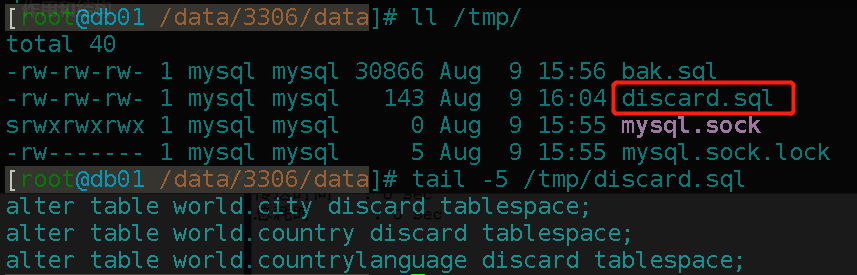 image
image
8\. 模仿模板语句,批量生成对world数据库下的表操作的语句
atler table world.city engine=innodb;