- 从鸡肉高汤到记忆的魔法再到有效提示的艺术
步子哥
人工智能
还记得小时候那些天马行空的白日梦吗?也许只要按下键盘上的某个神奇组合,电脑就会发出滴滴的声响,一个隐藏的世界突然在你眼前展开,让你获得超凡的能力,摆脱平凡的生活。这听起来像是玩过太多电子游戏的幻想,但实际上,间隔重复系统给人的感觉惊人地相似。在最佳状态下,这些系统就像魔法一样神奇。本文将以一个看似平凡的鸡肉高汤食谱为例,深入浅出地探讨如何编写有效的间隔重复提示,让你像掌握烹饪技巧一样轻松地掌握记忆
- 【加密社】Solidity 中的事件机制及其应用
加密社
闲侃区块链智能合约区块链
加密社引言在Solidity合约开发过程中,事件(Events)是一种非常重要的机制。它们不仅能够让开发者记录智能合约的重要状态变更,还能够让外部系统(如前端应用)监听这些状态的变化。本文将详细介绍Solidity中的事件机制以及如何利用不同的手段来触发、监听和获取这些事件。事件存储的地方当我们在Solidity合约中使用emit关键字触发事件时,该事件会被记录在区块链的交易收据中。具体而言,事件
- 读书||陶新华《教育中的积极心理学》1—28
流水淙淙2022
读一本好书,尤如和一位高尚者对话,亦能对人的精神进行洗礼。但是若不能和实践结合起来,也只能落到空读书的状态。读书摘要与感想1、塞利格曼在《持续的幸福》一书中提出了幸福2.0理论,提出幸福由5个元素决定——积极情绪、投入的工作和生活、目标和意义、和谐的人际关系、成就感。2、人的大脑皮层在进行智力活动时,都伴有皮下中枢活动,对这些活动进行体验请假,并由此产生了情感解读。人的情绪情感体验总是优先于大脑的
- 自我意识
徐立华
----读帕克.帕尔默《教学勇气》(P18----19)5.铸造我们的学科帕克.帕尔默说学科知识对我们的自身认同和外部世界有启发意义。学科会铸造我们。“在我们与学科的命题概念和学科的生活框架相遇之前,自我意识知识处于潜伏状态,通过回想学科是怎样唤醒自我意识,我们就可以找回教学心灵。”《教学勇气》(P18)我们的自我意识像冰山表面下无限延伸的冰层,常常处于潜伏状态。但是在我们对所教授的学科进行深入思
- 第六集如何安装CentOS7.0,3分钟学会centos7安装教程
date分享
从光盘引导系统按回车键继续进入引导程序安装界面,选择语言这里选择简体中文版点击继续选择桌面安装下面给系统分区选择磁盘,点击完成选择基本分区,点击加号swap分区,大小填内存的两倍在选择根分区,使用所有可用的磁盘空间选择文件系统ext4点击完成,点击开始安装设置root密码,点击完成设置普通用户和密码,点击完成整个过程持续八分钟左右根据个人配置不同,时间长短不同好,现在点击重启系统进入重启状态点击本
- 基于CODESYS的多轴运动控制程序框架:逻辑与运动控制分离,快速开发灵活操作
GPJnCrbBdl
python开发语言
基于codesys开发的多轴运动控制程序框架,将逻辑与运动控制分离,将单轴控制封装成功能块,对该功能块的操作包含了所有的单轴控制(归零、点动、相对定位、绝对定位、设置当前位置、伺服模式切换等等)。程序框架由主程序按照状态调用分归零模式、手动模式、自动模式、故障模式,程序状态的跳转都已完成,只需要根据不同的工艺要求完成所需的动作即可。变量的声明、地址的规划都严格按照C++的标准定义,能帮助开发者快速
- 2019-3-23晨间日记
红红火火小耳朵
今天是什么日子起床:7点40就寝:23点半天气:有太阳,不过一会儿出来一会儿进去特别清爽的凉意,还蛮舒服的心情:小激动要给女朋友过生日啦纪念日:田田女士过生日任务清单昨日完成的任务,最重要的三件事:1.英语一对一2.运动计划3.认真护肤习惯养成:调整状态周目标·完成进度英语七天打卡(5/7)轻课阅读(87/180)音标课(25/30)读书(福尔摩斯一章)学习·信息·阅读#英语课#Cookingte
- mac电脑命令行获取电量
小米人er
我的博客macos命令行
在macOS上,有几个命令行工具可以用来获取电量信息,最常用的是pmset命令。你可以通过以下方式来查看电池状态和电量信息:查看电池状态:pmset-gbatt这个命令会返回类似下面的输出:Nowdrawingfrom'BatteryPower'-InternalBattery-0(id=1234567)95%;discharging;4:02remainingpresent:true输出中包括电
- 【Git】常见命令(仅笔记)
好想有猫猫
GitLinux学习笔记git笔记elasticsearchlinuxc++
文章目录创建/初始化本地仓库添加本地仓库配置项提交文件查看仓库状态回退仓库查看日志分支删除文件暂存工作区代码远程仓库使用`.gitigore`文件让git不追踪一些文件标签创建/初始化本地仓库gitinit添加本地仓库配置项gitconfig-l#以列表形式显示配置项gitconfiguser.name"ljh"#配置user.namegitconfiguser.email"
[email protected]
- nosql数据库技术与应用知识点
皆过客,揽星河
NoSQLnosql数据库大数据数据分析数据结构非关系型数据库
Nosql知识回顾大数据处理流程数据采集(flume、爬虫、传感器)数据存储(本门课程NoSQL所处的阶段)Hdfs、MongoDB、HBase等数据清洗(入仓)Hive等数据处理、分析(Spark、Flink等)数据可视化数据挖掘、机器学习应用(Python、SparkMLlib等)大数据时代存储的挑战(三高)高并发(同一时间很多人访问)高扩展(要求随时根据需求扩展存储)高效率(要求读写速度快)
- openssl+keepalived安装部署
_小亦_
项目部署keepalivedopenssl
文章目录OpenSSL安装下载地址编译安装修改系统配置版本Keepalived安装下载地址安装遇到问题安装完成配置文件keepalived运行检查运行状态查看系统日志修改服务service重新加载systemd检查配置文件语法错误OpenSSL安装下载地址考虑到后面设备可能没法连接到外网,所以采用安装包的方式进行部署,下载地址:https://www.openssl.org/source/old/
- 2021-07-31
比峰
七月的最后一天,过了今天,就是八月,心脏在颤抖……昨天两点半才睡,一直在以两倍的语速的听之前的课程,虽然隔得时间不长,但是很多知识点已经忘了差不多了,为了让自己能够掌握的稍微全面一点,还是磨刀不误砍柴工的比较好。正因为晚上睡得晚,今天一上午的状态都不好,也可能因为上午都是待在家里,所以多数时间自己是在补觉。既然太累,那就睡觉吧,总比浪费时间的好。下午到咖啡馆做题,一道差错更正一下子让自己的实力暴露
- 趁吾身未老
逍遥书生111
趁吾身未老池非2020年,一场突如其来的新冠脑炎疫情,打破了原有的状态。工作与生活的轨迹发生了不确定的变化。01因为隔离防疫,正常的教学不能进行,线上网课成为教学的新形式,年过五十的我面对新的教学形式有些应不暇。只得退而求次,不再负责高考班级的课程。这样,就不用上网课做直播了。感觉很轻松很闲的同时,也感觉到了英雄迟暮。不得不承认,老了。该交班了。因为不能出门,整天呆在家里,一开始还很兴奋,终于可以
- 【ARM Cortex-M 系列 2.3 -- Cortex-M7 Debug event 详细介绍】
主公讲 ARM
#ARM系列arm开发debugevent
请阅读【嵌入式开发学习必备专栏】文章目录Cortex-M7DebugeventDebugeventsCortex-M7Debugevent在ARMCortex-M7架构中,调试事件(DebugEvent)是由于调试原因而触发的事件。一个调试事件会导致以下几种情况之一发生:进入调试状态:如果启用了停滞调试(HaltingDebug),一个调试事件会使处理器在调试状态下停滞。通过将DHCSR.C_DE
- uniapp map组件自定义markers标记点
以对_
uni-app学习记录uni-appjavascript前端
需求是根据后端返回数据在地图上显示标记点,并且根据数据状态控制标记点颜色,标记点背景通过两张图片实现控制{{item.options.labelName}}exportdefault{data(){return{storeIndex:0,locaInfo:{longitude:120.445172,latitude:36.111387},markers:[//标点列表{id:1,//标记点idin
- 2021-11-18
安安303
刘红雅中原焦点团队分享第135天筑基第4课社会心理学接上一课,心理现象。需要和动机所有的动机行为受需要的影响,现在的孩子很多方面不需要,是因为得到的太多需要使机体内部不平衡的状态,现在很多需要满足的过多,是“厌”,孩子要越用越有用,没有用到自己,自己没有价值感成就感,他就不需要开发自己的潜力。对自己和孩子的生活留白不断的学习成长,实现自己。所有有情绪的地方是触动了需求,需求没有被满足,当一个人知道
- 阅读《别说你懂思维导图》21~23章day27
Ling宝尔
合理期待——思维导图的应用效果很多人问我,思维导图真的有用么?我常常回答,如果你觉得是它“没用”,一定是因为你没“用”,有“用”才“有用”。实际上,学习思维导图和学习木工、驾驶等技能型学习一样,都要经历从了解到应用、从应用到受益的过程。在使用前,我们很多人的思维处于“无意识的低效”状态,经过一段时间的学习,虽然掌握了思维导图的基本使用方法,但可能并没有太好的效果,这个阶段可称为“有意识的低效”状态
- 2021-07-09
2018心如止水
张雲芳焦点解决网络课程学习坚持分享第816天20210709本周第2次(约练总291)渴了喝水;饿了吃饭;累了休息。看似简单的选择与行为,做起来却没那么容易。尤其是作为成年人,每天有工作需要完成,有孩子、家人需要陪伴,有时候各种事情赶在一起,忙的晕头转向、焦头烂额,即使自己特别累,也没有间隙去休息一下下,想象一下身体疲惫,精力耗竭是什么样的状态?对于孩子的哭闹你还会有更多的耐心吗?我想多数情况下都
- 最简单将静态网页挂载到服务器上(不用nginx)
全能全知者
服务器nginx运维前端html笔记
最简单将静态网页挂载到服务器上(不用nginx)如果随便弄个静态网页挂在服务器都要用nignx就太麻烦了,所以直接使用Apache来搭建一些简单前端静态网页会相对方便很多检查Web服务器服务状态:sudosystemctlstatushttpd#ApacheWeb服务器如果发现没有安装web服务器:安装Apache:sudoyuminstallhttpd启动Apache:sudosystemctl
- 切换淘宝最新npm镜像源是
hai40587
npm前端node.js
切换淘宝最新npm镜像源是一个相对简单的过程,但首先需要明确当前淘宝npm镜像源的状态和最新的镜像地址。由于网络环境和服务更新,镜像源的具体地址可能会发生变化,因此,我将基于当前可获取的信息,提供一个通用的切换步骤,并附上最新的镜像地址(截至回答时)。一、了解npm镜像源npm(NodePackageManager)是JavaScript的包管理器,用于安装、更新和管理项目依赖。由于npm官方仓库
- 润忻21天跨年魔力打卡D12早.正月初九《感恩日记》
尧安妈咪呀
1.感恩阳光透过窗帘照进我家。2.感恩暖气让我们家如此温暖。3.感恩水让我们可以洗漱。4.感恩老公对我的包容。5.感恩及时进入工作状态。6.感恩孩子们一如既往的可爱。7.感恩孩子们对我的爱。8.感恩一切顺利。8.感恩工作高效。9.感恩钱宝宝。10.感恩一切的发生。
- 《蛤蟆先生去看心理医生》读后感
我是八零后
《蛤蟆先生去看心理医生》,听书名像是童书,其实是一本专业心理学书籍,一本可以给成年人带来的心灵疗愈的书。走进书本,我们一起跟着蛤蟆先生跟随心理医生的咨询,探寻情绪的根源,进行自我突破,完成个人状态的转变,实现自我的疗愈。一、刷重点1个前提。改变的唯一前提是认识你自己,在这个世界上能帮你的人,只有你自己。2个思维。人人在理性与感性之间徘徊。真正厉害的人,是理性与感性并存。3个状态。每个人都有儿童、父
- 2021-11-26
雅雅_201d
感恩活着的美好幸福喜悦。谢谢谢谢谢谢感恩打卡261.感恩亲爱的自己每天坚定的动态静心,让我充满力量充满奇迹。谢谢谢谢谢谢2.感恩遇见的每一个在走心的人儿,高频的能量在深深的吸引着我引领着我。谢谢谢谢谢谢3.感恩范先生有着良好的生命状态,和高能量的智慧传递,让我愉悦安心。谢谢谢谢谢谢4.感恩宝贝女儿,积极正向充满力量,每一声回应都让我更加的安心更加的有力量。谢谢谢谢谢谢5.感谢亲爱的爸爸妈妈非常喜悦
- C++常见知识掌握
nfgo
c++开发语言
1.Linux软件开发、调试与维护内核与系统结构Linux内核是操作系统的核心,负责管理硬件资源,提供系统服务,它是系统软件与硬件之间的桥梁。主要组成部分包括:进程管理:内核通过调度器分配CPU时间给各个进程,实现进程的创建、调度、终止等操作。使用进程描述符(task_struct)来存储进程信息,包括状态(就绪、运行、阻塞等)、优先级、内存映射等。内存管理:包括物理内存和虚拟内存管理。通过页表映
- 新的一年,春节假期期间,你有没有去深度思考过自己的未来?
十八点心理
新的一年,是不是应该思考些什么?是继续和亲朋好友聊聊天,还是想一条属于自己的路?我们很多人会在过年的氛围中去享受当下的一切,打打麻将、打打牌、聊聊天、侃侃大山,整个人的精神状态特别好。觉得完全有一种自我满足的状态体验。但是从另外一个层面看,看到那些厉害的人,那些对于自己人生取得巨大成就的人来说,根本没有春节休息一说,在春节时分,还在见缝插针去写点文章、录个视频、思考新一年的规划。当看到那种忙碌的身
- 2022-03-28
f413057875cf
今日目标:定金2资源10完成:定金1,资源8原因:今天有点感冒,上午状态不好,下午几次有几次听,可能没挖需,都没留明日休息。充足电下周继续干!!
- uniapp实现动态标记效果详细步骤【前端开发】
2401_85123349
uni-app
第二个点在于实现将已经被用户标记的内容在下一次获取后刷新它的状态为已标记。这是什么意思呢?比如说上面gif图中的这些人物对象,有一些已被该用户添加为关心,那么当用户下一次进入该页面时,这些已经被添加关心的对象需要以“红心”状态显现出来。这个点的难度还不算大,只需要在每一次获取后端的内容后对标记对象进行状态更新即可。II.动态标记效果实现思路和步骤首先,整体的思路是利用动态类名对不同的元素进行选择。
- 菜鸟教你修U盘
zoyation
文章工具百度google杀毒软件
优盘是好多人都在使用的便携设备在给我们带来方便的同时,也带来困惑由于这样或那样的原因,优盘总是会出这样或那样的毛病小的毛病是中了一般的病毒,用杀毒软件就能清除,一般不会有什么损失稍微大的毛病是由于使用不当(拔插优盘时没有安全弹出等原因)导致再次使用时优盘不能打开、不能拷贝文件、不能格式化、提示写保护或者使用时要等很久才显示出来盘符并且出现一种卡机的状态再大点的毛病就是根本在电脑上就显示不出来盘符(
- 【星盘解析】水星和火星之间的四种相位,你的性格被哪种影响占据了?
匡苪祯库
水星和火星之间的四种相位,分别是合、拱、刑和冲。这些相位代表了不同的状态和影响,让我们一一来看看。首先合相,这代表着水星和火星之间的能量是相互协作的。这种相位通常会给人带来一些积极的影响,如思维敏捷、行动力强和创造力强。盘主可能会感到自己有很强的逻辑思维和决策能力,能够在事业和生活中取得成功。同时,这种相位也可能会让盘主变得过于急躁和焦虑,需要注意放松心态和调整自己的情绪。其次是拱相,这代表着水星
- 在陌生场合如何用闲谈打破冷场
小小雁儿
你有没有发生过这种情况?当谈话的对象是陌生人,或是不怎么熟悉的人,或是沉默寡言的人时,不知道如何开口聊天,谈话很容易陷入冷场,气氛也可能变僵……如果你在一个商务场合,肯定也不希望自己一个人傻站着,只能和手机发生点互动。每个人都渴望在人群中被他人关注,都渴望被搭讪。面对这些局面,怎样让自己快速进入状态,开始一次有趣的闲谈呢?在这里我介绍两种心理暗示法:心理暗示法一:“我是主人”。如果参加一场宴会,你
- Java常用排序算法/程序员必须掌握的8大排序算法
cugfy
java
分类:
1)插入排序(直接插入排序、希尔排序)
2)交换排序(冒泡排序、快速排序)
3)选择排序(直接选择排序、堆排序)
4)归并排序
5)分配排序(基数排序)
所需辅助空间最多:归并排序
所需辅助空间最少:堆排序
平均速度最快:快速排序
不稳定:快速排序,希尔排序,堆排序。
先来看看8种排序之间的关系:
1.直接插入排序
(1
- 【Spark102】Spark存储模块BlockManager剖析
bit1129
manager
Spark围绕着BlockManager构建了存储模块,包括RDD,Shuffle,Broadcast的存储都使用了BlockManager。而BlockManager在实现上是一个针对每个应用的Master/Executor结构,即Driver上BlockManager充当了Master角色,而各个Slave上(具体到应用范围,就是Executor)的BlockManager充当了Slave角色
- linux 查看端口被占用情况详解
daizj
linux端口占用netstatlsof
经常在启动一个程序会碰到端口被占用,这里讲一下怎么查看端口是否被占用,及哪个程序占用,怎么Kill掉已占用端口的程序
1、lsof -i:port
port为端口号
[root@slave /data/spark-1.4.0-bin-cdh4]# lsof -i:8080
COMMAND PID USER FD TY
- Hosts文件使用
周凡杨
hostslocahost
一切都要从localhost说起,经常在tomcat容器起动后,访问页面时输入http://localhost:8088/index.jsp,大家都知道localhost代表本机地址,如果本机IP是10.10.134.21,那就相当于http://10.10.134.21:8088/index.jsp,有时候也会看到http: 127.0.0.1:
- java excel工具
g21121
Java excel
直接上代码,一看就懂,利用的是jxl:
import java.io.File;
import java.io.IOException;
import jxl.Cell;
import jxl.Sheet;
import jxl.Workbook;
import jxl.read.biff.BiffException;
import jxl.write.Label;
import
- web报表工具finereport常用函数的用法总结(数组函数)
老A不折腾
finereportweb报表函数总结
ADD2ARRAY
ADDARRAY(array,insertArray, start):在数组第start个位置插入insertArray中的所有元素,再返回该数组。
示例:
ADDARRAY([3,4, 1, 5, 7], [23, 43, 22], 3)返回[3, 4, 23, 43, 22, 1, 5, 7].
ADDARRAY([3,4, 1, 5, 7], "测试&q
- 游戏服务器网络带宽负载计算
墙头上一根草
服务器
家庭所安装的4M,8M宽带。其中M是指,Mbits/S
其中要提前说明的是:
8bits = 1Byte
即8位等于1字节。我们硬盘大小50G。意思是50*1024M字节,约为 50000多字节。但是网宽是以“位”为单位的,所以,8Mbits就是1M字节。是容积体积的单位。
8Mbits/s后面的S是秒。8Mbits/s意思是 每秒8M位,即每秒1M字节。
我是在计算我们网络流量时想到的
- 我的spring学习笔记2-IoC(反向控制 依赖注入)
aijuans
Spring 3 系列
IoC(反向控制 依赖注入)这是Spring提出来了,这也是Spring一大特色。这里我不用多说,我们看Spring教程就可以了解。当然我们不用Spring也可以用IoC,下面我将介绍不用Spring的IoC。
IoC不是框架,她是java的技术,如今大多数轻量级的容器都会用到IoC技术。这里我就用一个例子来说明:
如:程序中有 Mysql.calss 、Oracle.class 、SqlSe
- 高性能mysql 之 选择存储引擎(一)
annan211
mysqlInnoDBMySQL引擎存储引擎
1 没有特殊情况,应尽可能使用InnoDB存储引擎。 原因:InnoDB 和 MYIsAM 是mysql 最常用、使用最普遍的存储引擎。其中InnoDB是最重要、最广泛的存储引擎。她 被设计用来处理大量的短期事务。短期事务大部分情况下是正常提交的,很少有回滚的情况。InnoDB的性能和自动崩溃 恢复特性使得她在非事务型存储的需求中也非常流行,除非有非常
- UDP网络编程
百合不是茶
UDP编程局域网组播
UDP是基于无连接的,不可靠的传输 与TCP/IP相反
UDP实现私聊,发送方式客户端,接受方式服务器
package netUDP_sc;
import java.net.DatagramPacket;
import java.net.DatagramSocket;
import java.net.Ine
- JQuery对象的val()方法执行结果分析
bijian1013
JavaScriptjsjquery
JavaScript中,如果id对应的标签不存在(同理JAVA中,如果对象不存在),则调用它的方法会报错或抛异常。在实际开发中,发现JQuery在id对应的标签不存在时,调其val()方法不会报错,结果是undefined。
- http请求测试实例(采用json-lib解析)
bijian1013
jsonhttp
由于fastjson只支持JDK1.5版本,因些对于JDK1.4的项目,可以采用json-lib来解析JSON数据。如下是http请求的另外一种写法,仅供参考。
package com;
import java.util.HashMap;
import java.util.Map;
import
- 【RPC框架Hessian四】Hessian与Spring集成
bit1129
hessian
在【RPC框架Hessian二】Hessian 对象序列化和反序列化一文中介绍了基于Hessian的RPC服务的实现步骤,在那里使用Hessian提供的API完成基于Hessian的RPC服务开发和客户端调用,本文使用Spring对Hessian的集成来实现Hessian的RPC调用。
定义模型、接口和服务器端代码
|---Model
&nb
- 【Mahout三】基于Mahout CBayes算法的20newsgroup流程分析
bit1129
Mahout
1.Mahout环境搭建
1.下载Mahout
http://mirror.bit.edu.cn/apache/mahout/0.10.0/mahout-distribution-0.10.0.tar.gz
2.解压Mahout
3. 配置环境变量
vim /etc/profile
export HADOOP_HOME=/home
- nginx负载tomcat遇非80时的转发问题
ronin47
nginx负载后端容器是tomcat(其它容器如WAS,JBOSS暂没发现这个问题)非80端口,遇到跳转异常问题。解决的思路是:$host:port
详细如下:
该问题是最先发现的,由于之前对nginx不是特别的熟悉所以该问题是个入门级别的:
? 1 2 3 4 5
- java-17-在一个字符串中找到第一个只出现一次的字符
bylijinnan
java
public class FirstShowOnlyOnceElement {
/**Q17.在一个字符串中找到第一个只出现一次的字符。如输入abaccdeff,则输出b
* 1.int[] count:count[i]表示i对应字符出现的次数
* 2.将26个英文字母映射:a-z <--> 0-25
* 3.假设全部字母都是小写
*/
pu
- mongoDB 复制集
开窍的石头
mongodb
mongo的复制集就像mysql的主从数据库,当你往其中的主复制集(primary)写数据的时候,副复制集(secondary)会自动同步主复制集(Primary)的数据,当主复制集挂掉以后其中的一个副复制集会自动成为主复制集。提供服务器的可用性。和防止当机问题
mo
- [宇宙与天文]宇宙时代的经济学
comsci
经济
宇宙尺度的交通工具一般都体型巨大,造价高昂。。。。。
在宇宙中进行航行,近程采用反作用力类型的发动机,需要消耗少量矿石燃料,中远程航行要采用量子或者聚变反应堆发动机,进行超空间跳跃,要消耗大量高纯度水晶体能源
以目前地球上国家的经济发展水平来讲,
- Git忽略文件
Cwind
git
有很多文件不必使用git管理。例如Eclipse或其他IDE生成的项目文件,编译生成的各种目标或临时文件等。使用git status时,会在Untracked files里面看到这些文件列表,在一次需要添加的文件比较多时(使用git add . / git add -u),会把这些所有的未跟踪文件添加进索引。
==== ==== ==== 一些牢骚
- MySQL连接数据库的必须配置
dashuaifu
mysql连接数据库配置
MySQL连接数据库的必须配置
1.driverClass:com.mysql.jdbc.Driver
2.jdbcUrl:jdbc:mysql://localhost:3306/dbname
3.user:username
4.password:password
其中1是驱动名;2是url,这里的‘dbna
- 一生要养成的60个习惯
dcj3sjt126com
习惯
一生要养成的60个习惯
第1篇 让你更受大家欢迎的习惯
1 守时,不准时赴约,让别人等,会失去很多机会。
如何做到:
①该起床时就起床,
②养成任何事情都提前15分钟的习惯。
③带本可以随时阅读的书,如果早了就拿出来读读。
④有条理,生活没条理最容易耽误时间。
⑤提前计划:将重要和不重要的事情岔开。
⑥今天就准备好明天要穿的衣服。
⑦按时睡觉,这会让按时起床更容易。
2 注重
- [介绍]Yii 是什么
dcj3sjt126com
PHPyii2
Yii 是一个高性能,基于组件的 PHP 框架,用于快速开发现代 Web 应用程序。名字 Yii (读作 易)在中文里有“极致简单与不断演变”两重含义,也可看作 Yes It Is! 的缩写。
Yii 最适合做什么?
Yii 是一个通用的 Web 编程框架,即可以用于开发各种用 PHP 构建的 Web 应用。因为基于组件的框架结构和设计精巧的缓存支持,它特别适合开发大型应
- Linux SSH常用总结
eksliang
linux sshSSHD
转载请出自出处:http://eksliang.iteye.com/blog/2186931 一、连接到远程主机
格式:
ssh name@remoteserver
例如:
ssh
[email protected]
二、连接到远程主机指定的端口
格式:
ssh name@remoteserver -p 22
例如:
ssh i
- 快速上传头像到服务端工具类FaceUtil
gundumw100
android
快速迭代用
import java.io.DataOutputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOExceptio
- jQuery入门之怎么使用
ini
JavaScripthtmljqueryWebcss
jQuery的强大我何问起(个人主页:hovertree.com)就不用多说了,那么怎么使用jQuery呢?
首先,下载jquery。下载地址:http://hovertree.com/hvtart/bjae/b8627323101a4994.htm,一个是压缩版本,一个是未压缩版本,如果在开发测试阶段,可以使用未压缩版本,实际应用一般使用压缩版本(min)。然后就在页面上引用。
- 带filter的hbase查询优化
kane_xie
查询优化hbaseRandomRowFilter
问题描述
hbase scan数据缓慢,server端出现LeaseException。hbase写入缓慢。
问题原因
直接原因是: hbase client端每次和regionserver交互的时候,都会在服务器端生成一个Lease,Lease的有效期由参数hbase.regionserver.lease.period确定。如果hbase scan需
- java设计模式-单例模式
men4661273
java单例枚举反射IOC
单例模式1,饿汉模式
//饿汉式单例类.在类初始化时,已经自行实例化
public class Singleton1 {
//私有的默认构造函数
private Singleton1() {}
//已经自行实例化
private static final Singleton1 singl
- mongodb 查询某一天所有信息的3种方法,根据日期查询
qiaolevip
每天进步一点点学习永无止境mongodb纵观千象
// mongodb的查询真让人难以琢磨,就查询单天信息,都需要花费一番功夫才行。
// 第一种方式:
coll.aggregate([
{$project:{sendDate: {$substr: ['$sendTime', 0, 10]}, sendTime: 1, content:1}},
{$match:{sendDate: '2015-
- 二维数组转换成JSON
tangqi609567707
java二维数组json
原文出处:http://blog.csdn.net/springsen/article/details/7833596
public class Demo {
public static void main(String[] args) { String[][] blogL
- erlang supervisor
wudixiaotie
erlang
定义supervisor时,如果是监控celuesimple_one_for_one则删除children的时候就用supervisor:terminate_child (SupModuleName, ChildPid),如果shutdown策略选择的是brutal_kill,那么supervisor会调用exit(ChildPid, kill),这样的话如果Child的behavior是gen_

 chcekPoint
chcekPoint Restore
Restore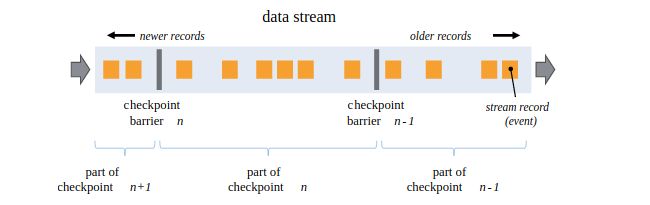 单并行度Barriers
单并行度Barriers 多并行度Barriers
多并行度Barriers