在前面的章节2中,我们使用全连接网络对手写MNIST字符集进行分类。我们给图中的每个对象分配一个神经元,总共有784(28*28)个输入神经元。然而,这样的策略丢失了图像的空间结构关系。
以下代码把每个手写数字的图像转化成扁平向量,导致空间局部性消失:
# X_train是60000行28*28的数据,变现为60000*784
X_train = X_train.reshape(60000, 784)
X_test = X_test.reshape(10000, 784)
而卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),因为其保留了空间信息,也因此可以更好地适用于图像分类问题。
深度卷积神经网络——DCNN
深度卷积神经网络(Deep Convolutional Neural Networks, CNN)由很多的神经网络层组成。包含交替出现的卷积层和池化层。每个滤波器的深度在网络中增加。最后一部分通常由一个或多个全连接层组成。
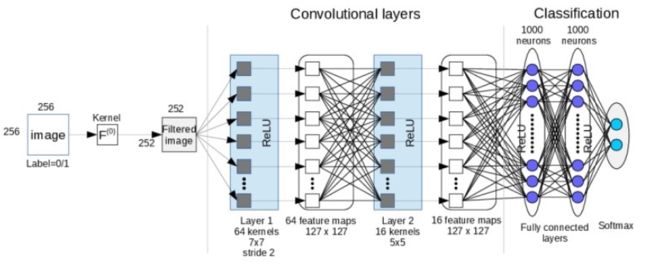
有三个卷积网络之外的关键概念:
- 局部感受野与卷积
- 共享权重和偏差
- 池化
局部感受野与卷积层
在全连接的网络中,输入被描绘成纵向排列的神经元,但是在卷积网络中我们把它看成28x28的方形:
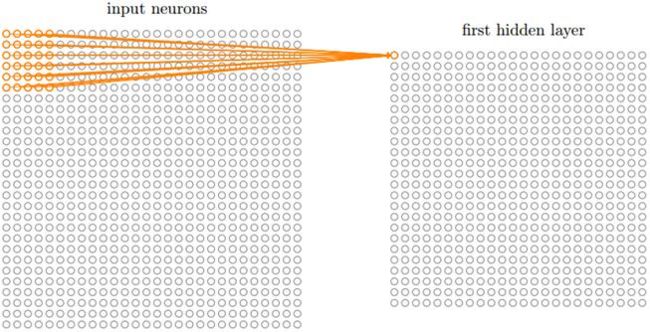
输入神经元的一小片区域会被连接到下一层隐层,这个区域被称为局部感受野,然后在输入图像中移动局部感受野,每移动一次,对应一个隐层的神经元,如此重复构成隐层所有神经元。如果局部感受野是5x5的,一次移动一格,输入图像是28x28的,那么隐层有24x24个神经元。
共享权重和偏置
每个隐层的神经元都有一个偏置和连接到它的局部感受野的5x5的权重,并且对这一层的所有神经元使用相同的权重和偏置。也就是说,对于隐藏层的第j行第k列的神经元,它的输出为:
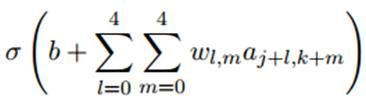
其中σ是激活函数,b是共享偏置,Wl,m是共享权重的5x5数组,用ax,y表示输入层的第x行第y列的神经元的输出值,即隐层的第j行第k列的神经元的若干个输入。
共享,意味着这一个隐层的所有神经元检测完全相同的特征,在输入图像的不同位置。这说明卷积网络可以很好地适应图片的平移不变性。共享权重和偏置被称为卷积核或者滤波器。我们再看一下卷积的过程:

共享权重和偏置的一个很大的优点是,大大减少了网络的参数数量。一次卷积我们需要5x5=25个共享权重,加上一个共享偏置共26个参数。如果我们卷积了20次,那么共有20x26=520个参数。以全连接对比,输入神经元有28x28=784个,隐层神经元设为30个,共有784x30个权重,加上30个偏置,共有23550个参数。卷积层的平移不变性会减少参数数量并加快训练,有助于建立深度网络。
池化层
池化层一般在卷积层之后使用,主要是简化从卷积层输出的信息。池化层的每个单元概括了前一层的一个小区域,常见的方法有最大池化,它取前一层那个小区域里的最大值作为对应池化层的值。
1、最大池化
最简单的池化方式,简单地输出最大激活值作为这个区域的观测结果。在Keras中,如果我们要定义一个2x2的最大池化层,我们可以写成:
model.add(MaxPooling2D(pool_size = (2, 2)))
2、平均池化
另一个选择是平均池化,就是简单地把这个区域观察到的激活值取平均值。
除了上面两种,还有更多的池化方式,完整列表请参见Keras官网。简单地说,所有的池化操作都是对一个给定区域的汇总操作。
用Keras构建LeNet代码
from keras import backend as K
from keras.models import Sequential
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.layers.core import Activation
from keras.layers.core import Flatten
from keras.layers.core import Dense
from keras.datasets import mnist
from keras.utils import np_utils
from keras.optimizers import SGD, RMSprop, Adam
import numpy as np
import matplotlib.pyplot as plt
# define ConvNet
class LeNet:
@staticmethod
def build(input_shape, classes):
model = Sequential()
# CONV => RELU => POOL
model.add(Conv2D(20, kernel_size=5, padding="same", input_shape=input_shape))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# CONV => RELU => POOL
model.add(Conv2D(50, kernel_size=5, padding="same"))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
# Flatten layer to RELU layer
model.add(Flatten())
model.add(Dense(500))
model.add(Activation("relu"))
# softmax classifier
model.add(Dense(classes))
model.add(Activation("softmax"))
return model
# 网络和训练
NB_EPOCH = 20
BATCH_SIZE = 128
VERBOSE = 1
OPTIMIZER = Adam()
VALIDATION_SPLIT = 0.2
IMG_ROWS, IMG_COLS = 28, 28
NB_CLASSES = 10
INPUT_SHAPE = (1, IMG_ROWS, IMG_COLS)
# 混合并划分训练集和测试集数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
# 设置图像的维度顺序(‘tf’或‘th’)# 当前的维度顺序如果为'th'
# 则输入图片数据时的顺序为:channels,rows,cols,否则:rows,cols,channels
K.set_image_dim_ordering("th")
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
# 使用形状60k*[1*28*28]作为卷积网络的输入
X_train = X_train[:, np.newaxis, :, :]
X_test = X_test[:, np.newaxis, :, :]
print(X_train.shape[0], 'train samples')
print(X_test.shape[0], 'test samples')
# 将类向量转换成二值类别矩阵
y_train = np_utils.to_categorical(y_train, NB_CLASSES)
y_test = np_utils.to_categorical(y_test, NB_CLASSES)
# 初始化优化器和模型
model = LeNet.build(input_shape=INPUT_SHAPE, classes=NB_CLASSES)
model.compile(loss="categorical_crossentropy", optimizer=OPTIMIZER, metrics=["accuracy"])
history = model.fit(X_train, y_train, batch_size=BATCH_SIZE, epochs=NB_EPOCH, verbose=VERBOSE, validation_split=VALIDATION_SPLIT)
score = model.evaluate(X_test, y_test, verbose=VERBOSE)
print("\nTest score:", score[0])
print('Test accuracy:', score[1])
# list all data in history
print(history.history.keys())
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()