声明:原创文章,转载请注明出处。http://www.jianshu.com/u/e02df63eaa87
1、从生产者消费者说起
在传统的生产者消费者模型中,通常是采用BlockingQueue实现。其中生产者线程负责提交需求,消费者线程负责处理任务,二者之间通过共享内存缓冲区进行通信。由于内存缓冲区的存在,允许生产者和消费者之间速度的差异,确保系统正常运行。
下图展示一个简单的生产者消费者模型,生产者从文件中读取数据,将数据内容写入到阻塞队列中,消费者从队列的另一边获取数据,进行计算并将结果输出。其中Main负责创建两类线程并初始化队列。
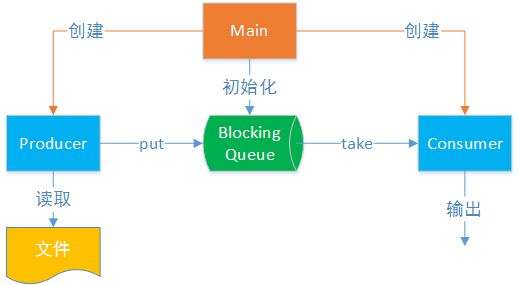
Main:
public class Main {
public static void main(String[] args) {
// 初始化阻塞队列
BlockingQueue blockingQueue = new ArrayBlockingQueue<>(1000);
// 创建生产者线程
Thread producer = new Thread(new Producer(blockingQueue, "temp.dat"));
producer.start();
// 创建消费者线程
Thread consumer = new Thread(new Consumer(blockingQueue));
consumer.start();
}
}
生产者:
public class Producer implements Runnable {
private BlockingQueue blockingQueue;
private String fileName;
private static final String FINIDHED = "EOF";
public Producer(BlockingQueue blockingQueue, String fileName) {
this.blockingQueue = blockingQueue;
this.fileName = fileName;
}
@Override
public void run() {
try {
BufferedReader reader = new BufferedReader(new FileReader(new File(fileName)));
String line;
while ((line = reader.readLine()) != null) {
blockingQueue.put(line);
}
// 结束标志
blockingQueue.put(FINIDHED);
} catch (Exception e) {
e.printStackTrace();
}
}
}
消费者:
public class Consumer implements Runnable {
private BlockingQueue blockingQueue;
private static final String FINIDHED = "EOF";
public Consumer(BlockingQueue blockingQueue) {
this.blockingQueue = blockingQueue;
}
@Override
public void run() {
String line;
String[] arrStr;
int ret;
try {
while (!(line = blockingQueue.take()).equals(FINIDHED)) {
// 消费
arrStr = line.split("\t");
if (arrStr.length != 2) {
continue;
}
ret = Integer.parseInt(arrStr[0]) + Integer.parseInt(arrStr[1]);
System.out.println(ret);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
生产者-消费者模型可以很容易地将生产和消费进行解耦,优化系统整体结构,并且由于存在缓冲区,可以缓解两端性能不匹配的问题。
2、BlockingQueue的不足
上述使用了ArrayBlockingQueue,通过查看其实现,完全是使用锁和阻塞等待实现线程同步。在高并发场景下,性能不是很优越。
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
insert(e);
} finally {
lock.unlock();
}
}
但是,ConcurrentLinkedQueue却是一个高性能队列,这是因为其实现使用了无锁的CAS操作。
3、Disruptor初体验
Disruptor是由LMAX公司开发的一款高效无锁内存队列。使用无锁方式实现了一个环形队列代替线性队列。相对于普通的线性队列,环形队列不需要维护头尾两个指针,只需维护一个当前位置就可以完成出入队操作。受限于环形结构,队列的大小只能初始化时指定,不能动态扩展。
如下图所示,Disruptor的实现为一个循环队列,ringbuffer拥有一个序号(Seq),这个序号指向数组中下一个可用的元素。

随着不停地填充这个buffer(可能也会有相应的读取),这个序号会一直增长,直到超过这个环。

Disruptor要求数组大小设置为2的N次方。这样可以通过Seq & (QueueSize - 1) 直接获取,其效率要比取模快得多。这是因为(Queue - 1)的二进制为全1等形式。例如,上图中QueueSize大小为8,Seq为10,则只需要计算二进制1010 & 0111 = 2,可直接得到index=2位置的元素。
在RingBuffer中,生产者向数组中写入数据,生产者写入数据时,使用CAS操作。消费者从中读取数据时,为防止多个消费者同时处理一个数据,也使用CAS操作进行数据保护。
这种固定大小的RingBuffer还有一个好处是,可以内存复用。不会有新空间需要分配或者旧的空间回收,当数组填充满后,再写入数据会将数据覆盖。
4、Disruptor小试牛刀
同样地,使用Disruptor处理第一节中的生产者消费者的案例。
4.1 添加Maven依赖
com.lmax
disruptor
3.3.2
4.2 定义事件对象
由于我们只需要将文件中的数据行读出,然后进行计算。因此,定义FileData.class来保存文件行。
public class FileData {
private String line;
public String getLine() {
return line;
}
public void setLine(String line) {
this.line = line;
}
}
4.3 定义工厂类
用于产生FileData的工厂类,会在Disruptor系统初始化时,构造所有的缓冲区中的对象实例。
public class DisruptorFactory implements EventFactory {
public FileData newInstance() {
return new FileData();
}
}
4.4 定义消费者
消费者的作用是读取数据并进行处理。数据的读取已经由Disruptor封装,onEvent()方法为Disruptor框架的回调方法。只需要进行简单的数据处理即可。
public class DisruptorConsumer implements WorkHandler {
private static final String FINIDHED = "EOF";
@Override
public void onEvent(FileData event) throws Exception {
String line = event.getLine();
if (line.equals(FINIDHED)) {
return;
}
// 消费
String[] arrStr = line.split("\t");
if (arrStr.length != 2) {
return;
}
int ret = Integer.parseInt(arrStr[0]) + Integer.parseInt(arrStr[1]);
System.out.println(ret);
}
}
4.5 定义生产者
生产者需要一个Ringbuffer的引用。其中pushData()方法是将生产的数据写入到RingBuffer中。具体的过程是,首先通过next()方法得到下一个可用的序列号;取得下一个可用的FileData,并设置该对象的值;最后,进行数据发布,这个FileData对象会传递给消费者。
public class DisruptorProducer {
private static final String FINIDHED = "EOF";
private final RingBuffer ringBuffer;
public DisruptorProducer(RingBuffer ringBuffer) {
this.ringBuffer = ringBuffer;
}
public void pushData(String line) {
long seq = ringBuffer.next();
try {
FileData event = ringBuffer.get(seq); // 获取可用位置
event.setLine(line); // 填充可用位置
} catch (Exception e) {
e.printStackTrace();
} finally {
ringBuffer.publish(seq); // 通知消费者
}
}
public void read(String fileName) {
try {
BufferedReader reader = new BufferedReader(new FileReader(new File(fileName)));
String line;
while ((line = reader.readLine()) != null) {
// 生产数据
pushData(line);
}
// 结束标志
pushData(FINIDHED);
} catch (Exception e) {
e.printStackTrace();
}
}
}
4.6 定义Main函数
最后需要一个DisruptorMain()将上述的数据、生产者和消费者进行整合。
public class DisruptorMain {
public static void main(String[] args) {
DisruptorFactory factory = new DisruptorFactory(); // 工厂
ExecutorService executor = Executors.newCachedThreadPool(); // 线程池
int BUFFER_SIZE = 16; // 必须为2的幂指数
// 初始化Disruptor
Disruptor disruptor = new Disruptor<>(factory,
BUFFER_SIZE,
executor,
ProducerType.MULTI, // Create a RingBuffer supporting multiple event publishers to the one RingBuffer
new BlockingWaitStrategy() // 默认阻塞策略
);
// 启动消费者
disruptor.handleEventsWithWorkerPool(new DisruptorConsumer(),
new DisruptorConsumer()
);
disruptor.start();
// 启动生产者
RingBuffer ringBuffer = disruptor.getRingBuffer();
DisruptorProducer producer = new DisruptorProducer(ringBuffer);
producer.read("temp.dat");
// 关闭
disruptor.shutdown();
executor.shutdown();
}
}
5、Disruptor策略
Disruptor生产者和消费者之间是通过什么策略进行同步呢?Disruptor提供了如下几种策略:
- BlockingWaitStrategy:默认等待策略。和BlockingQueue的实现很类似,通过使用锁和条件(Condition)进行线程同步和唤醒。此策略对于线程切换来说,最节约CPU资源,但在高并发场景下性能有限。
- SleepingWaitStrategy:CPU友好型策略。会在循环中不断等待数据。首先进行自旋等待,若不成功,则使用
Thread.yield()让出CPU,并使用LockSupport.parkNanos(1)进行线程睡眠。所以,此策略数据处理数据可能会有较高的延迟,适合用于对延迟不敏感的场景。优点是对生产者线程影响小,典型应用场景是异步日志。 - YieldingWaitStrategy:低延时策略。消费者线程会不断循环监控RingBuffer的变化,在循环内部使用
Thread.yield()让出CPU给其他线程。 - BusySpinWaitStrategy:死循环策略。消费者线程会尽最大可能监控缓冲区的变化,会占用所有CPU资源。
6、Disruptor解决CPU Cache伪共享问题
为了解决CPU和内存速度不匹配的问题,CPU中有多个高速缓存Cache。在Cache中,读写数据的基本单位是缓存行,缓存行是内存复制到缓存的最小单位。
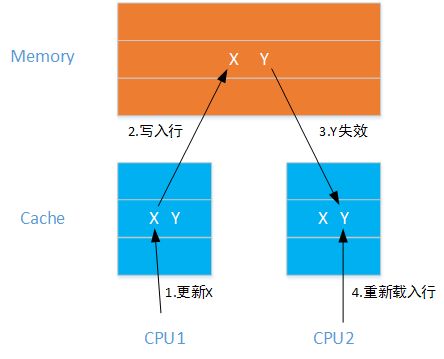
若两个变量放在同一个Cache Line中,在多线程情况下,可能会相互影响彼此的性能。如上图所示,CPU1上的线程更新了变量X,则CPU上的缓存行会失效,同一行的Y即使没有更新也会失效,导致Cache无法命中。
同样地,若CPU2上的线程更新了Y,则导致CPU1上的缓存行又失效。如果CPU经常不能命中缓存,则系统的吞吐量则会下降。这就是伪共享问题。
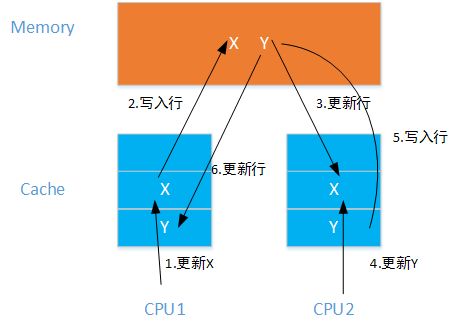
解决伪共享问题,可以在变量的前后都占据一定的填充位置,尽量让变量占用一个完整的缓存行。如上图中,CPU1上的线程更新了X,则CPU2上的Y则不会失效。同样地,CPU2上的线程更新了Y,则CPU1的不会失效。
class LhsPadding
{
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
protected volatile long value;
}
class RhsPadding extends Value
{
protected long p9, p10, p11, p12, p13, p14, p15;
}
/**
* Concurrent sequence class used for tracking the progress of
* the ring buffer and event processors. Support a number
* of concurrent operations including CAS and order writes.
*
*
Also attempts to be more efficient with regards to false
* sharing by adding padding around the volatile field.
*/
public class Sequence extends RhsPadding
{
static final long INITIAL_VALUE = -1L;
private static final Unsafe UNSAFE;
private static final long VALUE_OFFSET;
static
{
UNSAFE = Util.getUnsafe();
try
{
VALUE_OFFSET = UNSAFE.objectFieldOffset(Value.class.getDeclaredField("value"));
}
catch (final Exception e)
{
throw new RuntimeException(e);
}
}
... ...
}
在Sequence的实现中,主要使用的是Value,但通过LhsPadding和RhsPadding在Value的前后填充了一些空间,使Value无冲突的存在于缓存行中。
参考
http://ifeve.com/dissecting-disruptor-whats-so-special/