前言
最近公司让我们移动端转型大数据, 所以在自己的电脑上安装配置Hadoop环境是第一部分,因为笔者是iOS开发, 用的是Mac工具, 所以本文章是关于Mac版本的Hadoop安装配置.
一. 配置之前
因为Hadoop是用Java写的, 所以我们自己开发程序或者运行程序都需要Java的环境, 所以我们需要先安装Java的环境, JDK的下载地址请点击 这里, 可以看到 如图1
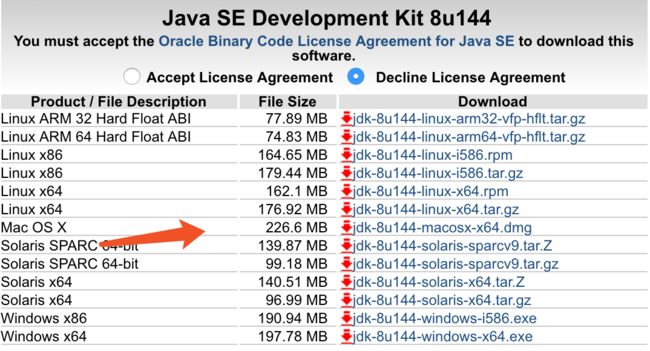
下载成功,按照步骤安装成功后我们要继续配置JDK的环境变量
1.1 查看JDK的安装路径
终端执行 /usr/libexec/java_home -V 得到 如图2

复制图中的路径
/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home
1.2 配置Java的环境变量
终端执行 vim ~/.bash_profile 然后点击i进入编辑模式, 键入以下代码,注意用自己的路径
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home
export PATH=$JAVA_HOME/bin:$PATH
按esc后 shift + ; (冒号) 输入wq 回车 如图3
终端键入
source /etc/profile 使环境变量立即生效
终端键入
java -version得
如图4 即为SDK1.8安装成功

1.3 配置ssh
安装ssh是为了无密钥登录主机,Hadoop集群中主机数目很大时配置ssh能够很方便的启动Hadoop集群.
首先终端键入 cd ~/.ssh 如果可以进入这个文件夹说明你的本地已经配置过了ssh环境
然后执行 cat id_rsa.pub >> authorized_keys 使ssh免密登录
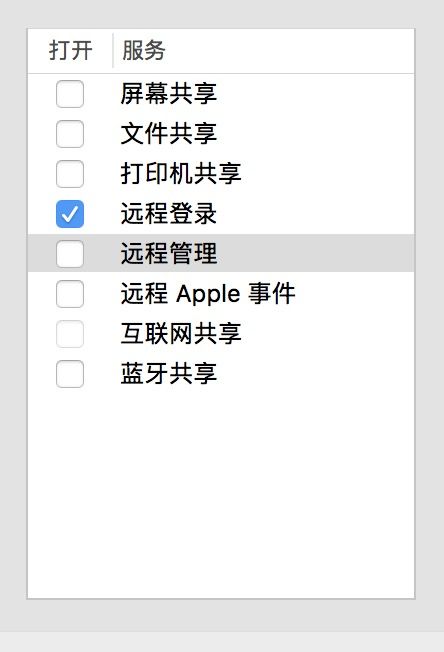
然后打开电脑的设置, 在共享中打开 远程登录 如图5
回到终端键入
ssh localhost 出现
如图6 即为成功

没有配置好ssh环境的, 请点击 这里
二. Hadoop环境配置
2.1 Hadoop下载
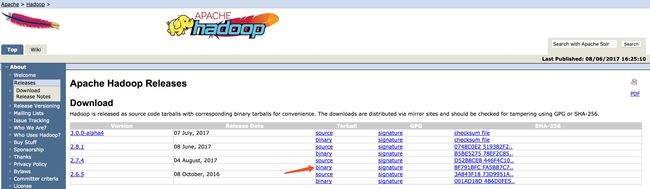
在Apache上Hadoop官网下载, 下载请点击 这里, 笔者用的是2.7.4版本, 红色剪头指向是我们需要下载的 hadoop-2.7.4.tar.gz 如图7
我的Hadoop包放在了
/Users/wjl/tools/hadoop-2.7.4这个路径里, 具体放在哪里你们根据自己的情况
2.2 配置Hadoop环境变量
配置方法和配置JDK的方法差不多, 只不过新版本的需要配置两个路径的环境变量, 在配置环境变量的文件里(根目录下的.bash_profile)里加入以下代码, 具体怎么找到打开这个文件配置同上
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_121.jdk/Contents/Home
export HADOOP_HOME=/Users/wjl/tools/hadoop-2.7.4
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
配置好后, source /etc/profile 使环境变量立即生效, 注意只要我们改变了环境变量都需要使用这个命令, 或者重启终端
执行 hadoop version 可以看到版本号, 说明Hadoop的环境变量已经配置好了
2.3 配置Hadoop的4个配置文件,
这四个文件是在 hadoop包的/etc/hadoop下面
在我的Mac上是 /Users/wjl/tools/hadoop-2.7.4/etc/hadoop
分别是
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
我使用的hadoop-2.7.4版本没有 mapred-site.xml 这个文件, 我们需要自己复制一个xml文件改一下名字为mapred-site.xml
2.3.1 配置core-site.xml
fs.defaultFS
hdfs://0.0.0.0:9000
hadoop.tmp.dir
/Users/wjl/tools/hadoop-2.7.4/temp
2.3.2 配置hdfs-site.xml
dfs.replication
1
dfs.namenode.name.dir
file:/Users/wjl/tools/hadoop-2.7.4/tmp/hdfs/name
dfs.datanode.data.dir
file:/Users/wjl/tools/hadoop-2.7.4/tmp/hdfs/data
dfs.namenode.secondary.http-address
localhost:9001
dfs.webhdfs.enabled
true
2.3.3 配置mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.admin.user.env
HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME
yarn.app.mapreduce.am.env
HADOOP_MAPRED_HOME=$HADOOP_COMMON_HOME
mapreduce.job.tracker
hdfs://192.168.1.51:8001
true
2.3.4 配置yarn-site.xml
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.resource.memory-mb
8192
yarn.nodemanager.resource.cpu-vcores
1
- 以上所以的配置都配置好了 在终端执行先执行
hadoop namenode -format让hadoop格式化, 这个命令只执行一遍, 执行成功好, 重复执行导致namespaceID不一致,出现问题, 这个时候我们需要 删掉 hadoop文件下的temp和tmp文件夹, 重新执行命令格式化 - 格式化之后,我们执行
start-all.sh或者 分别执行start-dfs.sh和start-yarn.sh,两种方法都是一样的效果 - 以上的命令都执行成功后 jps 如果出现 如图8 即为成功, 这写图8出现的服务缺少了就可能会在文章后面测试执行demo中出现bug, 如果出现问题仔细看文章上面的步骤, 或者@笔者, 笔者看到了会一一回复
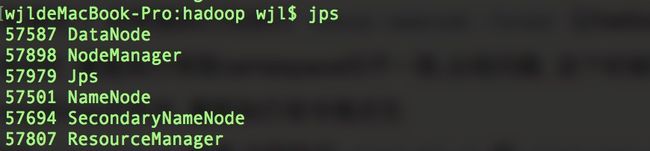 图8
图8
关于Hadoop在Mac系统上的环境配置到这里结束了, 有问题的小伙伴请联系QQ: 502391211 我们一起探讨.
下一篇文章 Hadoop的常用命令和要注意的地方