前言
本文主要讲解Mybatis的以下知识点:
- Mybatis缓存
- 一级缓存
- 二级缓存
- 与Ehcache整合
- Mapper代理
- 使用Mapper代理就不用写实现类了
- 逆向工程
- 自动生成代码
Mybatis缓存
缓存的意义
- 将用户经常查询的数据放在缓存(内存)中,用户去查询数据就不用从磁盘上(关系型数据库数据文件)查询,从缓存中查询,从而提高查询效率,解决了高并发系统的性能问题。

mybatis提供一级缓存和二级缓存
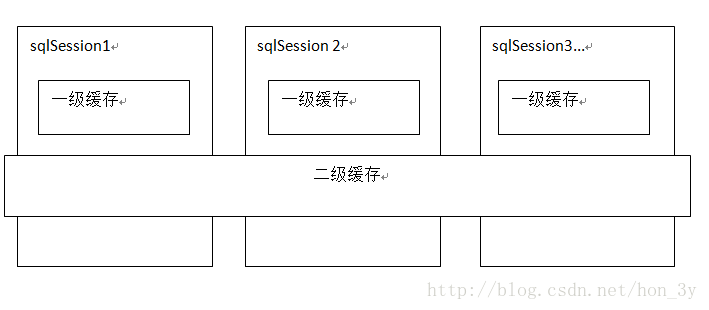
- mybatis一级缓存是一个SqlSession级别,sqlsession只能访问自己的一级缓存的数据
- 二级缓存是跨sqlSession,是mapper级别的缓存,对于mapper级别的缓存不同的sqlsession是可以共享的。
看完上面对Mybatis的缓存的解释,我们发现Mybatis的缓存和Hibernate的缓存是极为相似的..
Mybatis一级缓存
Mybatis的一级缓存原理:

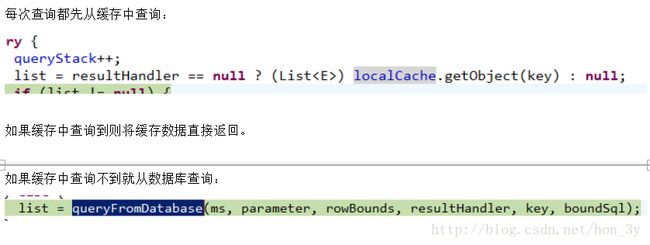
第一次发出一个查询sql,sql查询结果写入sqlsession的一级缓存中,缓存使用的数据结构是一个map
- key:hashcode+sql+sql输入参数+输出参数(sql的唯一标识)
- value:用户信息
同一个sqlsession再次发出相同的sql,就从缓存中取不走数据库。如果两次中间出现commit操作(修改、添加、删除),本sqlsession中的一级缓存区域全部清空,下次再去缓存中查询不到所以要从数据库查询,从数据库查询到再写入缓存。
Mybatis一级缓存值得注意的地方:
- Mybatis默认就是支持一级缓存的,并不需要我们配置.
- mybatis和spring整合后进行mapper代理开发,不支持一级缓存,mybatis和spring整合,spring按照mapper的模板去生成mapper代理对象,模板中在最后统一关闭sqlsession。
Mybatis二级缓存
二级缓存原理:
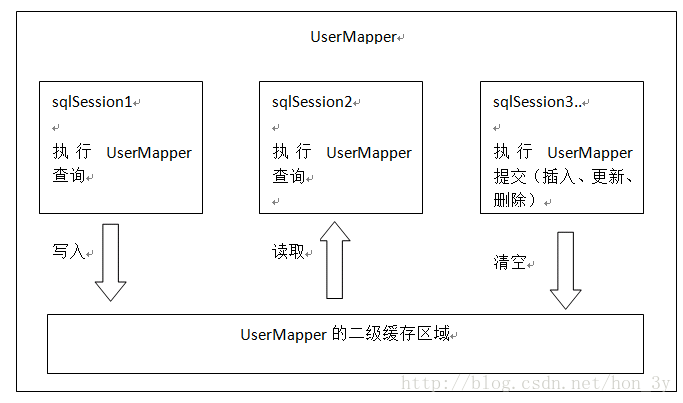
二级缓存的范围是mapper级别(mapper同一个命名空间),mapper以命名空间为单位创建缓存数据结构,结构是map

Mybatis二级缓存配置
需要我们在Mybatis的配置文件中配置二级缓存
上面已经说了,二级缓存的范围是mapper级别的,因此我们的Mapper如果要使用二级缓存,还需要在对应的映射文件中配置..
查询结果映射的pojo序列化
mybatis二级缓存需要将查询结果映射的pojo实现 java.io.serializable接口,如果不实现则抛出异常:
org.apache.ibatis.cache.CacheException: Error serializing object. Cause: java.io.NotSerializableException: cn.itcast.mybatis.po.User
二级缓存可以将内存的数据写到磁盘,存在对象的序列化和反序列化,所以要实现java.io.serializable接口。
如果结果映射的pojo中还包括了pojo,都要实现java.io.serializable接口。
禁用二级缓存
对于变化频率较高的sql,需要禁用二级缓存:
在statement中设置useCache=false可以禁用当前select语句的二级缓存,即每次查询都会发出sql去查询,默认情况是true,即该sql使用二级缓存。、、
刷新缓存
有的同学到这里可能会有一个疑问:为什么缓存我们都是在查询语句中配置??而使用增删改的时候,缓存默认就会被清空【刷新了】???
缓存其实就是为我们的查询服务的,对于增删改而言,如果我们的缓存保存了增删改后的数据,那么再次读取时就会读到脏数据了!
我们在特定的情况下,还可以单独配置刷新缓存【但不建议使用】flushCache,默认是的true
update user set username=#{username},birthday=#{birthday},sex=#{sex},address=#{address} where id=#{id}
了解Mybatis缓存的一些参数
mybatis的cache参数只适用于mybatis维护缓存。
flushInterval(刷新间隔)可以被设置为任意的正整数,而且它们代表一个合理的毫秒形式的时间段。默认情况是不设置,也就是没有刷新间隔,缓存仅仅调用语句时刷新。
size(引用数目)可以被设置为任意正整数,要记住你缓存的对象数目和你运行环境的可用内存资源数目。默认值是1024。
readOnly(只读)属性可以被设置为true或false。只读的缓存会给所有调用者返回缓存对象的相同实例。因此这些对象不能被修改。这提供了很重要的性能优势。可读写的缓存会返回缓存对象的拷贝(通过序列化)。这会慢一些,但是安全,因此默认是false。
如下例子:
mybatis和ehcache缓存框架整合
ehcache是专门用于管理缓存的,Mybatis的缓存交由ehcache管理会更加得当..
在mybatis中提供一个cache接口,只要实现cache接口就可以把缓存数据灵活的管理起来。

整合jar包
- mybatis-ehcache-1.0.2.jar
- ehcache-core-2.6.5.jar
ehcache对cache接口的实现类:

ehcache.xml配置信息
这个xml配置文件是配置全局的缓存管理方案
如果我们Mapper想单独拥有一些特性,需要在mapper.xml中单独配置
应用场景与局限性
应用场景
对查询频率高,变化频率低的数据建议使用二级缓存。
对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度
业务场景比如:
- 耗时较高的统计分析sql、
- 电话账单查询sql等。
实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。
局限性
mybatis局限性
mybatis二级缓存对细粒度的数据级别的缓存实现不好,比如如下需求:对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次都能查询最新的商品信息,此时如果使用mybatis的二级缓存就无法实现当一个商品变化时只刷新该商品的缓存信息而不刷新其它商品的信息,因为mybaits的二级缓存区域以mapper为单位划分,当一个商品信息变化会将所有商品信息的缓存数据全部清空。解决此类问题需要在业务层根据需求对数据有针对性缓存。
Mapper代理方式
Mapper代理方式的意思就是:程序员只需要写dao接口,dao接口实现对象由mybatis自动生成代理对象。
经过我们上面的几篇博文,我们可以发现我们的DaoImpl是十分重复的...
1 dao的实现类中存在重复代码,整个mybatis操作的过程代码模板重复(先创建sqlsession、调用sqlsession的方法、关闭sqlsession)
2、dao的实现 类中存在硬编码,调用sqlsession方法时将statement的id硬编码。
以前的重复代码和硬编码如下:
public class StudentDao {
public void add(Student student) throws Exception {
//得到连接对象
SqlSession sqlSession = MybatisUtil.getSqlSession();
try{
//映射文件的命名空间.SQL片段的ID,就可以调用对应的映射文件中的SQL
sqlSession.insert("StudentID.add", student);
sqlSession.commit();
}catch(Exception e){
e.printStackTrace();
sqlSession.rollback();
throw e;
}finally{
MybatisUtil.closeSqlSession();
}
}
public static void main(String[] args) throws Exception {
StudentDao studentDao = new StudentDao();
Student student = new Student(3, "zhong3", 10000D);
studentDao.add(student);
}
}
Mapper开发规范
想要Mybatis帮我们自动生成Mapper代理的话,我们需要遵循以下的规范:
1、mapper.xml中namespace指定为mapper接口的全限定名
- 此步骤目的:通过mapper.xml和mapper.java进行关联。
2、mapper.xml中statement的id就是mapper.java中方法名
3、mapper.xml中statement的parameterType和mapper.java中方法输入参数类型一致
4、mapper.xml中statement的resultType和mapper.java中方法返回值类型一致.
再次说明:statement就是我们在mapper.xml文件中命名空间+sql指定的id
Mapper代理返回值问题
mapper接口方法返回值:
- 如果是返回的单个对象,返回值类型是pojo类型,生成的代理对象内部通过selectOne获取记录
- 如果返回值类型是集合对象,生成的代理对象内部通过selectList获取记录。
Mybatis解决JDBC编程的问题
1、数据库链接创建、释放频繁造成系统资源浪费从而影响系统性能,如果使用数据库链接池可解决此问题。
- 解决:在SqlMapConfig.xml中配置数据链接池,使用连接池管理数据库链接。
2、Sql语句写在代码中造成代码不易维护,实际应用sql变化的可能较大,sql变动需要改变java代码。
- 解决:将Sql语句配置在XXXXmapper.xml文件中与java代码分离。
3、向sql语句传参数麻烦,因为sql语句的where条件不一定,可能多也可能少,占位符需要和参数一一对应。
- 解决:Mybatis自动将java对象映射至sql语句,通过statement中的parameterType定义输入参数的类型。
4、对结果集解析麻烦,sql变化导致解析代码变化,且解析前需要遍历,如果能将数据库记录封装成pojo对象解析比较方便。
- 解决:Mybatis自动将sql执行结果映射至java对象,通过statement中的resultType定义输出结果的类型。
Mybatis逆向工程
在Intellij idea下,没有学习Maven的情况下使用Mybatis的逆向工程好像有点复杂,资料太少了...找到的资料好像也行不通...
于是学完Maven之后,我就再来更新Idea下使用Mybatis的逆向工程配置...
借鉴博文:http://blog.csdn.net/for_my_life/article/details/51228098
修改pom.xml文件
向该工程添加逆向工程插件..
4.0.0
asdf
asdf
1.0-SNAPSHOT
zhongfucheng
org.mybatis.generator
mybatis-generator-maven-plugin
1.3.2
true
true
generatorConfig.xml配置文件
使用插件步骤

最后生成代码
如果对我们上面generatorConfig.xml配置的包信息不清楚的话,那么可以看一下我们的完整项目结构图...
因为我们在Idea下是不用写对应的工程名字的,而在eclipse是有工程名字的。

总结
Mybatis的一级缓存是sqlSession级别的。只能访问自己的sqlSession内的缓存。如果Mybatis与Spring整合了,Spring会自动关闭sqlSession的。所以一级缓存会失效的。
一级缓存的原理是map集合,Mybatis默认就支持一级缓存
二级缓存是Mapper级别的。只要在Mapper命名空间下都可以使用二级缓存。需要我们自己手动去配置二级缓存
Mybatis的缓存我们可以使用Ehcache框架来进行管理,Ehcache实现Cache接口就代表使用Ehcache来环境Mybatis缓存。
-
由于之前写的DaoImpl是有非常多的硬编码的。可以使用Mapper代理的方式来简化开发
- 命名空间要与JavaBean的全类名相同
- sql片段语句的id要与Dao接口的方法名相同
- 方法的参数和返回值要与SQL片段的接收参数类型和返回类型相同。
如果文章有错的地方欢迎指正,大家互相交流。习惯在微信看技术文章,想要获取更多的Java资源的同学,可以关注微信公众号:Java3y