这篇文章大概就是类似于 THUNLP-MT/Document-Transformer 的用户手册吧。
跑一个英->中的模型。
目录:
- 语料库下载:http://data.statmt.org/wmt18/translation-task/training-parallel-nc-v13.tgz
- BPE编码
- 利用句子级平行语料及文档级平行语料训练得到了基本的transformer模型;这里我使用的是之前训练好的t2t里面的transformer。
- 使用文档级平行语料训练一个虚拟的context_transformer模型;
- 将第一步得到的基本transformer模型merge到第二步的虚拟模型中,以初始化context模型;
- 训练context模型。
2,BPE编码
下载BPE工具包:https://github.com/rsennrich/subword-nmt.git ,进入subword_nmt目录,创建data文件夹,把语料库放入data文件夹,执行以下命令
python learn_joint_bpe_and_vocab.py --input data/train.en data/train.zh -s 32000 -o bpe32k --write-vocabulary data/vocab.en data/vocab.zh
python subword-nmt/apply_bpe.py --vocabulary data/vocab.en --vocabulary-threshold 50 -c bpe32k < data/train.en > data/corpus.32k.en
python subword-nmt/apply_bpe.py --vocabulary data/vocab.zh --vocabulary-threshold 50 -c bpe32k < data/train.zh > corpus.32k.zh
最后data文件的目录如图所示

对验证集同样进行bpe编码。
然后,将bpe产生的词表、经过bpe编码的训练集和验证集分别放到以下目录,将重命名
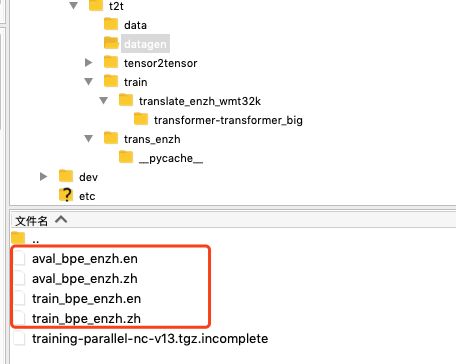
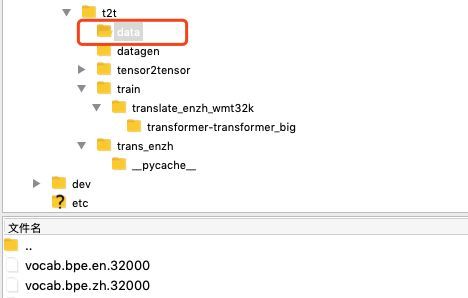
3,训练t2t中的transformer模型
首先去官网下载源码:tensorflow/tensor2tensor
PROBLEM=translate_enzh_wmt32k
MODEL=transformer
HPARAMS=transformer_big #单块GPU可以用transformer_base_single_gpu
DATA_DIR=./data
TMP_DIR=./datagen
TRAIN_DIR=./train/$PROBLEM/$MODEL-$HPARAMS
用户自定义数据可以参考:https://blog.csdn.net/hpulfc/article/details/82625217

接下来开始产生用于t2t中相应格式的数据:
t2t-datagen \
--data_dir=./data
--tmp_dir=./datagen \
--problem=translate_enzh_bpe32000 \
--t2t_usr_dir=./trans_enzh
接着就是训练:
t2t-trainer \
--data_dir=./data \
--problem=translate_enzh_bpe32000 \
--t2t_usr_dir=./trans_enzh \
--model=transformer \
--hparams_set=transformer_big \
--output_dir=./train \
--train_steps=100000 \
--hparams='batch_size=5120'
4,使用文档级平行语料训练一个虚拟的context_transformer模型。
这里需要用到一个上下文文档,具体参见 THUNLP-MT/Document-Transformer 。我简单写了个脚本。假定每两句话分别为上下文(这么做当然不好了)。
然后再手动添加一行空行,删除第一行最前面的空格,以及最后一行。
f = open('train.en')
f1 = open('train.ctx.en', 'w+')
pre = ''
print('--start--')
for i, cur in enumerate(f.readlines()):
str = (pre + ' ' + cur).replace('\n','')
print(str, file=f1)
pre = cur
f.close()
f1.close()
print('--finished--')
有了相应的语料之后,就可以训练一下虚拟的context_transformer模型了
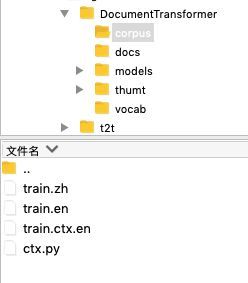
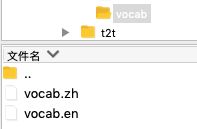
代码如下:
python2 thumt/bin/trainer_ctx.py \
--input corpus/train.en corpus/train.zh \
--context corpus/train.ctx.en \
--vocabulary vocab/vocab.en vocab/vocab.zh \
--output models/dummy \
--model contextual_transformer \
--parameters train_steps=1
只能用python2去跑,并且会报两个错,一个是找不到thumt这个包。
windows下要修改相应的环境变量。mac或者linux要创建.bashrc这个目录,添加
export PYTHONPATH=$PYTHONPATH:/container_data/zgk/DocumentTransformer/
再执行以下命令即可。
source .bashrc
另一个错是python2的KeyEthumt/data/datasey.py 在 python2 中报了错。
params.mapping["target"][params.unk]
报了一个KeyError的错,我直接改成
default_value=0
5,将第一步得到的基本transformer模型merge到第二步的虚拟模型中,以初始化context模型;
python2 thumt/scripts/combine_add.py \
--model models/dummy \
--part models/transformer/model.ckpt-100000 \
--output models/train/
6,训练context模型。
python2 thumt/bin/trainer_ctx.py \
--input corpus/train.en corpus/train.zh \
--context corpus/train.ctx.en \
--output models/sentence_doc \
--vocabulary vocab/vocab.en vocab/vocab.zh \
--model contextual_transformer \
--parameters start_steps=95000,num_context_layers=1,batch_size=6250,train_steps=100000,save_checkpoint_steps=5000,keep_checkpoint_max=50,beam_size=5
以上就可以训练出一个基于上下文的transformer模型了。至于训练出来的模型效果怎么样,该怎么优化,是后续的工作,不在本文的讨论范围……
在跑t2t的时候,经常遇到内存爆了的情况。因为我将
--hparams='batch_size=5120'
错写为
--batch_size=5120
另外也有可能是
--hparams_set=transformer_big 导致的……
本来还想着用8块2080Ti爽一把……