R语言中的类SQL操作
plyr包可以进行类似于数据透视表的操作,将数据分割成更小的数据,对分割后的数据进行些操作,最后把操作的结果汇总。
本文主要介绍以下内容:
- Split-Aapply-Combine 原理介绍
- baby_names的名字排名
- 求分段拟合的系数
- 部分其他函数介绍
在正式开始之前,请确保电脑上已经安装plyr,如果没有,通过install.packages()函数安装。
install.packages(plyr) # 安装plyr包
require(plyr) #载入plyr包
假设有美国新生婴儿的取名汇总,每一年,会统计男孩和女孩的取名情况,形成如下的一张表。
| year| name| percent| sex|
|---------:||---------:||---------:||---------:|
| 1880| John| 0.081541| boy|
| 1880| William| 0.080511| boy|
| 1880| James| 0.050057| boy|
| 1880| Charles| 0.045167| boy|
| 1880| George| 0.043292| boy|
| 1880| Frank| 0.02738| boy|
| 1880| Joseph| 0.022229| boy|
| 1880| Thomas| 0.021401| boy|
baby_names数据集包含1880 ~ 2008年间的数据, 包含统计的年份(year),新生婴儿的性别、名字、以及改名字的比例。
以提问并解决问题的形式对plyr做介绍。
- 想知道数据集中,每年都有多少记录?
- 数据集中,男孩和女孩名的各自排名?
- 男孩名和女孩名各自排名前100在当年中的比例?
数据集中,每年都有多少记录
先假设我们有某一年的数据,我们会如何统计其中的记录数呢?由于数据集中,每条记录一行,只需要统计对应的行数就可以得到对应的记录数。
写个函数试试
record_count <- function(df) {
return(data.frame(count = nrow(df)))
}
返回值类型是data.frame类型,是为即将介绍的ddply()函数做铺垫。先来看看2008年,数据集中有多少记录。
baby_names_2008 <- subset(baby_names, year == 2008)
record_count(baby_names_2008)
# 2000
结果显示2000条,貌似我们已经得到答案。下面想想,该如何得到1880 ~ 2008这129年间,每年的记录数呢?
ddply(baby_names, # 数据集
.(year), # 分类的标准
record_count # 函数
)
结果比较长,只摘取其中一部分
| year | count |
|---|---|
| 1880 | 2000 |
| 1881 | 2000 |
| 1882 | 2000 |
| 1883 | 2000 |
| 1884 | 2000 |
| 1885 | 2000 |
| 1886 | 2000 |
| 1887 | 2000 |
| 1888 | 2000 |
| 1889 | 2000 |
| 1890 | 2000 |
| 1891 | 2000 |
| 1892 | 2000 |
不错,每年都是2000条记录。再来看看,刚在我们做了什么。
- 定义了一个负责计数的函数
record_count() - 调用
ddply(),这里出现刚刚定义的函数
ddply()函数是plyr包中用于对data.frame结构的数据做处理的函数,其结果也是data.frame。ddply的参数列表如下:
ddply(.data, .variables, .fun = NULL, ..., .progress = "none",
.inform = FALSE, .drop = TRUE, .parallel = FALSE, .paropts = NULL)
各部分解释如下
- 第一个参数是要操作的原始数据集,比如
baby_name - 第二个参数是按照某个(也可以几个)变量,对数据集分割,比如按照
year对数据集分割,可以写成.(year)的形式 - 第三个参数是具体执行操作的函数,对分割后的每一个子数据集,调用该函数
- 第四个参数可选,表示第三个参数对应函数所需的额外参数
其他参数,可以暂时不用考虑。ddply()函数会自动的将分割后的每一小部分的计算结果汇总,以data.frame的格式保存。分割后的数据,是fun的第一个参数。
在上面的描述中,提到的分割、操作、汇总,在plyr包中是一种处理方式("frame"),即"Split - Apply - Combine"。在plyr包中有很多这种处理方式的函数,在介绍这些函数之前,我们再来看看ddply()的一些更深入的用法。
各年,男孩名与女孩名的各自排名
以2008年的数据为例,男孩名"Jacob"的比例最高,排名应当是第一,"Michael"紧跟其后,排名应当第二,依此类推。对于女孩名,"Emma"排名第一,"Isabella"排名第二,"Emily"排名第三等等。我们希望得到这样的结果。
对于2008年的数据,可以通过简单的rank即可得到,不过要对男孩和女孩分别排序。
baby_names_2008_boy <- subset(baby_names_2008, sex == "boy") # 获取男孩名
baby_names_2008_boy$rank <- rank(- baby_names_2008_boy$percent) # 排序
head(baby_names_2008_boy) # 查看
对女孩名也执行相同的操作,这里就不写出来了,只需要在subset中,将"boy"替换成"girl"就行。下面来看看2008年,男孩名的排名情况
| year | name | percent | sex | rank |
|---|---|---|---|---|
| 2008 | Jacob | 0.010355 | boy | 1 |
| 2008 | Michael | 0.009437 | boy | 2 |
| 2008 | Ethan | 0.009301 | boy | 3 |
| 2008 | Joshua | 0.008799 | boy | 4 |
| 2008 | Daniel | 0.008702 | boy | 5 |
| 2008 | Alexander | 0.008566 | boy | 6 |
再来看看女孩名的排名结果:
| year | name | percent | sex | rank |
|---|---|---|---|---|
| 2008 | Emma | 0.009043 | girl | 1 |
| 2008 | Isabella | 0.008941 | girl | 2 |
| 2008 | Emily | 0.008377 | girl | 3 |
| 2008 | Madison | 0.008199 | girl | 4 |
| 2008 | Ava | 0.008198 | girl | 5 |
| 2008 | Olivia | 0.008196 | girl | 6 |
如何利用ddply()对原始数据集做相应的操作呢?这里需要介绍R语言中的一个函数transform(),该函数对原始数据集做一些操作,并把结果存储在原始数据中,更详细的用法,参见帮助文档?transform。
第一个版本的处理方式是这样的
ddply(baby_names,
.(year, sex),
transform,
rank = rank(-percent, ties.method = "first")
)
第二个参数有点变化,除了year,还有sex,这表示对baby_name数据集,对year和sex分类(类似于SQL中的group by year, sex)。
第四个参数是transform的额外参数,如果查看transform的帮助文档,其函数调用方式如下:
transform(_data, ...)
第一参数为操作的数据,在
ddply()中为按年份和性别分割后的子数据集;后面的...参数是tag = value的形式,这种tag:value将追加在数据中。
由于rank默认对数据进行升序排序,若要实现逆序排序,常规的做法是将数据的符号取反,这也就是上面的rank函数中出现-percent的原因。在plyr中,有一个类似的函数,实现取反的操作,是desc。
x <- 1:10
desc(x)
# -1 -2 -3 -4 -5 -6 -7 -8 -9 -10
所以,上面对percent取反的操作,可以写得更优雅些,就有了第二个版本的函数
baby_names <- ddply(baby_names,
.(year, sex),
transform,
rank = rank(desc(percent), ties.method = "first")
)
注意这里把结果赋给了baby_name,因为后面还会用到排名的信息,就把结果保存下来。
** 排名前100的男孩名与女孩名在当年中的比例**
跟前一问类似,处理方法是:
- 把每年排名前100的数据筛选出来
- 把男孩和女孩对应的
percent相加
baby_names_top100 <- subset(baby_names, rank <= 100) # 将前100排名的数据筛选出来
baby_names_top100_trend <- ddply(baby_names_top100,
.(year, sex), # 按年和性别分割
summarize, # 汇总数据
trend = sum(percent)) # 汇总方式(求和)
这里出现一个新的操作函数summarize(),该函数是对数据做汇总,与transform不一样的是,该函数并不追加结果到原始数据,而是产生新的数据集。比如想知道,2008年的男孩名中,排名最高和最低的名字的百分比之差,可以通过如下方式求得:
summarize(baby_names_2008_boy, trend = max(percent) - min(percent))
# 0.010266
回到刚才的问题,从1880 ~ 2008年间,男孩名与女孩名的前100所占比例(可以衡量名字大众化的程度)到底是什么样的呢?画个图就知道了。
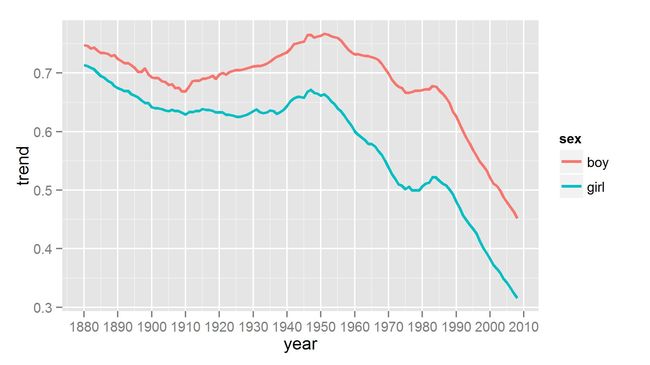
还有什么类似函数
上面介绍的ddply()是plyr包中处理data.frame的函数,还有处理list,array的函数,汇总起来如下
| arrary | data.frame | list | discarded | |
|---|---|---|---|---|
| arrary | aaply | adply | alply | a_ply |
| data.frame | daply | ddply | dlply | d_ply |
| list | laply | ldply | llply | l_ply |
所有的函数具有xyply的形式,其中x表示数据数据类型,y表示输出数据类型,而_表示丢弃。
应用举例
在R语言基础数据集中,有mtcars数据,其中记录了车重"weight"、"miles per galon"、"cylinder"等参数。由图可知,不同气缸下,车重与行驶里程有着不同的关系,如果以线性函数来刻画,是三条有着明显区别的函数。

该如何求着三条直线的参数呢(截距与斜率)?
将问题简化下,对于数据集df,有自变量x,因变量y,如何求y = a x + b的参数a和b?写个函数试试
linear_fit <- function(df) {
model <- lm(mpg ~ wt, df)
linear_coef <- coef(model)
linear_coef <- data.frame(intercept = linear_coef[1],
slope = linear_coef[-1])
row.names(linear_coef) <- NULL
linear_coef
}
下面再应用split - apply - combine的思想求出每一种cyl对应数据的截距和斜率
mtcars_coef <- ddply(mtcars, .(cyl), linear_fit)
names(mtcars_coef)[2:3] <- c("intercept", "slope")
所得拟合直线的截距和斜率为
| cyl | intercept | slope | |
|---|---|---|---|
| 1 | 4 | 39.57120 | -5.647025 |
| 2 | 6 | 28.40884 | -2.780106 |
| 3 | 8 | 23.86803 | -2.192438 |
再结合这原图,把这些直线画出来,与原图做个比较。
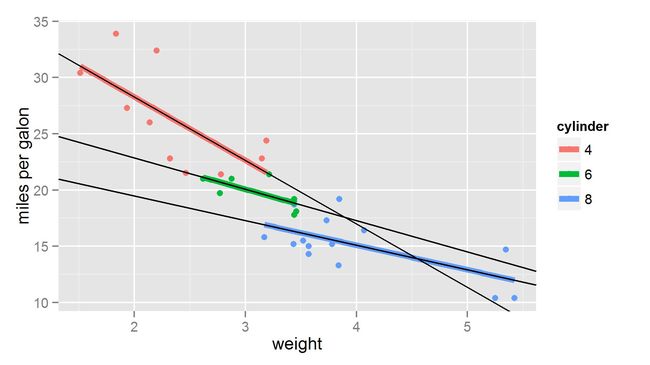
黑色的线为拟合的曲线,而彩色短线为系统所绘制的拟合曲线,说明我们的方法正确。
再来看看上面的拟合过程,将对每个子数据集的拟合封装成一个函数linear_fit,这样做没有问题,但是使得代码的可读性比较差,一种比价优雅的方式是在dlply的第三个参数处,直接放上lm函数,将额外的参数赋给第四个参数。
mtcars_model <- dlply(mtcars, .(cyl), lm,
formula = mpg ~ wt)
mtcars_coef <- ldply(mtcars_model, coef)
names(mtcars_coef)[2:3] <- c("intercept", "slope")
注意,这里通过dlply()函数调用拟合函数lm,而把具体的拟合形式formula = mpg ~ wt赋值给第四个参数。dlply()函数返回的是list,list的每个元素是一个lm的返回结果,通过ldply()调用coef获得每个模型对应的系数,记得到上述结果。
读入多个文件中的数据,并合并
下面来看看一个实际生活中的问题:
假设文件夹下有若干.csv文件, 每个文件的数据格式相同,且含有表头,如何将多个文件合并成一个文件呢?
如果没有表头的话,操作起来比较容易,可以直接用命令行工具实现,比如在linux下可以cat *.csv > total.csv实现文件合并。 此处给出一种使用plyr包中提供的ldaply的函数,实现上出操作,效率不一定是最高的,但可以进一步掌握plyr包的特性。
可以继续使用上述使用的baby_names数据集,使用如下命令, 将baby_names按年份写到不同的csv文件中。
d_ply(baby_names, .(year),
function(baby) write.csv(baby, paste0(baby$year[1], ".csv"), row.names = FALSE)
)
上述命令将在当前文件夹下,产生129个csv文件,从1880 ~ 2008, 每年一个文件,以年份命名。
使用如下的命令将
files <- list.files(pattern = "^\\d+\\.csv")
baby_names_recovered <- ldply(files, read.csv, stringsAsFactors = FALSE)
上述命令将129个文件名存储在files变量中,通过ldply,读取每个文件,并最后通过ldply合并成一个data.frame。需要说明的是ldply的第一个参数要求list,但是files变量却是vector,这个没有影响,函数内部会将第一个参数通过as.list()转换成list。
现在需要验证读入的baby_names_recovered与原始的baby_names一致,使用如下参数可以做相应的比较。
identical(arrange(baby_names, year, name, sex), arrange(baby_names_recovered, year, name, sex))
# TRUE
返回的结果是TRUE,即二者其实是一致的。至于为什么要用arrange函数对数据做一下排列,是因重新生成的baby_names_recovered,其读入数据的顺序并没有严格按照年份进行。
这里抛出一个问题,如果不使用plyr包,如何实现上述操作。
提示:查阅lapply和do.call函数,剩下的函数,已经在上面的示例中讲解。
部分其他函数
这一部分将简略介绍plyr 包中未提及的函数,以及其用法。
未完待续
参考文献
- http://courses.had.co.nz/09-user/
- baby names. http://courses.had.co.nz/09-user/code-data/bnames.csv