学习器模型中一般有两类参数,一类是可以从数据中学习估计得到,还有一类参数时无法从数据中估计,只能靠人的经验进行设计指定,后者成为超参数。比如,支持向量机里面的C, Kernal, game;朴素贝叶斯里面的alpha等。
使用以下的方法获得学习器模型的参数列表和当前取值, estimator.get_params()
参数空间的搜索有以下几个部分构成:
- 一个estimator(回归器 or 分类器)
- 一个参数空间
- 一个搜索或采样方法来获得候选参数集合
- 一个交叉验证机制
- 一个评分函数
有些学习器模型有自己独特的参数选择优化方法。
Sklearn提供了两种通用的超参数优化方法: 网格搜索 与 随机采样。
网格搜索交叉验证(GridSearchCV): 以穷举方法遍历所有的可能的参数组合。
随机采样交叉验证(RandomizedSearchCV): 依据某种分布对参数空间采样,随即得到参数组合方案。
模型 |
---|---
sklearn.model_selection.GridSearchCV |
sklearn.model_selection.RandomizedSearchCV |
sklearn.model_selection.ParameterGrid |
sklearn.model_selection.ParameterSampler |
sklearn.model_selection.fit_grid_point |
GridSearchCV
GridSearchCV提供了在参数网格上穷举候选参数组合的方法。参数网格由参数param_grid来指定。比如,下面展示了舍子参数网格param_grid的一个例子。
param_grid = [
{'C': [1,10,100,1000], 'kernel': ['linear']},
{'C': [1,10,100,1000], 'gamma': [0.001,0.0001], 'kernel':['rbf']},
]
上面的参数指定了要搜索的两个网格(每个网格是一个字典):第一个网格是线性核然后c
在[1, 10, 100, 1000]中取值;第二个参数时RFB核然后再是gamma的取值列表[0.001, 0.0001]以及C的取回列表[1, 10, 100, 1000]。第一个里面有4
个参数组合节点,第二个里面有4*2=8个参数组合节点。
from sklearn import svm,datasets
from sklearn.model_selection import GridSearchCV
iris = datasets.load_iris()
# 定义参数网格,2*3=6个参数组合
parameters = {'kernel': ('rbf', 'linear'), 'C': [1, 5, 10]}
svr = svm.SVC()
# 对所有的参数组合进行测试,选择最好的一个组合
clf = GridSearchCV(svr, parameters)
clf.fit(iris.data, iris.target)
print(clf.best_estimator_)

RandomizedSearchCV
RandomizedSearchCV实现了一个在参数空间上进行随机搜索到机制,起哄参数的选值是从某种概率分布中抽取的。这个概率分布描述了对应的参数的所有取值情况的可能性。这种随机采样机制与网格搜索穷举搜索相比,有两大优点:
- 相比于整体参数空间,可以选择相对较少的参数组合数量。
- 添加参数节点不会影响性能,不会降低效率。
指定参数的采样范围和分布可以用一个字典来完成,跟网格搜索很像。另外,计算预算(总共要随机采样多少个参数组合或者迭代多少次)可以使用参数n_iter来指定,针对每一个参数范围内的概率,既可以使用可能取值范围内的概率分布,也可以指定一个离散的取值列表(会被均匀采样)。
{'C':scipy.stats.expon(scale=100), 'gamma':scipy.stats.expon(scale=0.1),
'kernel':['rbf'], 'class_weight':['balanced', None]
}
这个例子使用了scipy.stats模块,其中包含了很多有用的分布来产生参数采样点,像expon, gamma, uniform or randint。原则上,任何一个函数都要可以传递进去,只要他提供了一个rvs(random variate sample)方法来返回采样值,rvs函数的连续调用应该能保证产生独立同分布的样本值。
对于连续取值的参数,比如上面的C, 给他指定一个连续的分布非常重要,这样可以保证充分利用随机化带来的好处,增加迭代次数,n_iter将会带来非常精准的搜索。
import numpy as np
import time
from scipy.stats import randint
from sklearn.datasets import load_digits
from sklearn.model_selection import RandomizedSearchCV, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# 用于报告超参数搜索的最好结果的函数
def report(results, n_top=3):
for i in range(1, n_top + 1):
candidates = np.flatnonzero(results['rank_test_score'] == i)
for candidate in candidates:
print('Model with rank: {0}'.format(i))
print('Mean validation score: {0:.3f}(std: {1:.3f})'.format(
results['mean_test_score'][candidate],
results['std_test_score'][candidate]))
print('Parameters: {0}'.format(results['params'][candidate]))
print('')
# 取得数据,手写字符分类
digits = load_digits()
X, y = digits.data, digits.target
# 构建一个随机方森林分类器,有20棵数
clf = RandomForestClassifier(n_estimators=20)
# 设置想要优化的超参数以及他们的取值分布
param_dist = {
'max_depth': [3, None],
'max_features': randint(1,11),
'min_samples_split': randint(2,11),
'bootstrap': [True, False],
'criterion': ['gini', 'entropy']
}
# 开启超参数空间的随机搜索
n_iter_search = 20
random_search = RandomizedSearchCV(clf, param_distributions=param_dist, n_iter=n_iter_search)
start = time.time()
random_search.fit(X, y)
print('time use: {}'.format(time.time() - start))
report(random_search.cv_results_)

下面将这两种方法进行比较
import numpy as np
import time
from scipy.stats import randint
from sklearn.datasets import load_digits
from sklearn.model_selection import RandomizedSearchCV, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
# 用于报告超参数搜索的最好结果的函数
def report(results, n_top=3):
for i in range(1, n_top + 1):
candidates = np.flatnonzero(results['rank_test_score'] == i)
for candidate in candidates:
print('Model with rank: {0}'.format(i))
print('Mean validation score: {0:.3f}(std: {1:.3f})'.format(
results['mean_test_score'][candidate],
results['std_test_score'][candidate]))
print('Parameters: {0}'.format(results['params'][candidate]))
print('')
# 取得数据,手写字符分类
digits = load_digits()
X, y = digits.data, digits.target
# 构建一个随机方森林分类器,有20棵数
clf = RandomForestClassifier(n_estimators=20)
print('==========下面是RandomizedSearchCV结果==============')
# 设置想要优化的超参数以及他们的取值分布
param_dist = {
'max_depth': [3, None],
'max_features': randint(1,11),
'min_samples_split': randint(2,11),
'bootstrap': [True, False],
'criterion': ['gini', 'entropy']
}
# 开启超参数空间的随机搜索
n_iter_search = 20
random_search = RandomizedSearchCV(clf, param_distributions=param_dist, n_iter=n_iter_search)
start = time.time()
random_search.fit(X, y)
print('time use: {}'.format(time.time() - start))
report(random_search.cv_results_)
print('==========下面是GridSearchCV结果==============')
# 设置想要优化的超参数以及他们的取值分布
param_grid = {
'max_depth': [3, None],
'max_features': [1, 3, 10],
'min_samples_split': [2, 3, 10],
'bootstrap': [True, False],
'criterion': ['gini', 'entropy']
}
# 开启超参数空间的随机搜索
grid_search = GridSearchCV(clf, param_grid=param_grid)
start = time.time()
grid_search.fit(X, y)
print('time use: {}'.format(time.time() - start))
report(grid_search.cv_results_)
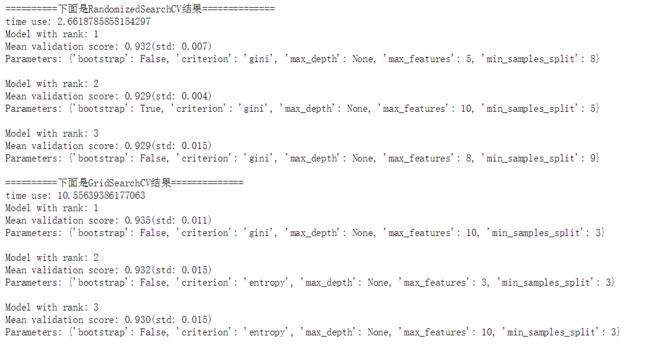
实验结果:
以随机森林分类器为优化对象,所有影响分类器学习的参数都被搜索了,除了树的数量之外,随机搜索和网格优化都在同一个超参数空间上对随机森林分类器进行优化。虽然得到的超参数设置组合比较相似,但是随机搜索运行的时间却网格搜索的时间显著减少,随季节搜索得到的超参数组合的性能稍微差一点,但是这很大程度上是有噪声引起的,在实践中, 我们只是挑选几个比较重要的参数进行随机组合来进行优化。
超参空间搜索技巧
- 指定一个合适的目标测度对木星进行评估,默认情况下,参数搜索使用的是estimator的score函数来评价模型在某种参数配置下的性能。分类器使用的是sklearn.metrics.accuracy_score, 回归器使用的是sklearn.metrics.r2_score。但是在某些情况下,其他的评分函数更加实用。
- 实用sklearn的Pineline将estimator和它们的参数空间组合起来
- 合理划分数据集:开发集(用于GridSearchCV)+ 测试集(Test)使用model_selection.train_test_split()函数。
- 并行化:以上两者在参数节点的计算上可以做到并行运算,这个通过'n_jobs'来指定。
- 提高在某些参数节点上发生错误时的鲁莽性:在出错节点上只是提示警告。设置参数error_score = 0(or np.NaN)来解决。