协同过滤——隐式评级及基于物品的过滤
第一篇讲的是显示评级,是用户确实打了的分,是过于理想的情况,现实中有很多不可控因素,有时用户打分口是心非,有时懒得打分,有时初次评价之后即使后来发现当初打分打低了,有时仅仅是与个人联系紧密的独家偏好……
隐式评级,不要求用户打分,而是观察用户的行为,可观察的维度很多:
上述讲的都是基于用户的过滤,也叫基于内存的过滤,意思是要进行大量的计算,尤其当用户很多的时候,对计算机内存要求比较高。现在亚马逊有上百万用户,计算扩展性是一个问题,更重要的是有时找不到最近邻。基于以上原因,最好采用基于物品的过滤。也叫基于模型的过滤。
1. 基于物品的过滤
利用物品之间的相似度进行推荐。从所有商品中找出与用户购买过的商品最相似的商品推荐给用户。
2. 计算物品之间的相似度,使用调整后的余弦相似度
和第一篇的余弦相似度类似,为了消除分数贬值,调整后的余弦相似度与余弦相似度公式有一点不同,用户U给物品i的打分减去用户U对所有物品打分的平均值。因为是基于物品的推荐,所以如果使用之前的余弦相似度,就要用物品的每一列属性中的每一项减去这一列的平均值,显然与实际情况不符。
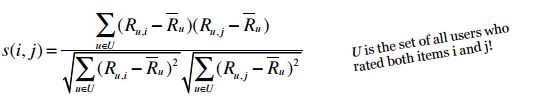
U 表示所有同时对i和j 进行过评级的用户的集合。
这个公式计算的是** 物品 i 和物品 j 之间的相似度 **。这个公式的直观解释是:
要计算 物品i 和 物品j 之间的相似度
1. 找出同时对物品i和物品j打分的用户
2. 计算每个用户对自己购买的书打分的平均值 R
3. 按照公式计算
Python 代码:
# -*- coding: utf-8 -*-
from math import sqrt
users3 = {"David": {"Imagine Dragons": 3, "Daft Punk": 5,
"Lorde": 4, "Fall Out Boy": 1},
"Matt": {"Imagine Dragons": 3, "Daft Punk": 4,
"Lorde": 4, "Fall Out Boy": 1},
"Ben": {"Kacey Musgraves": 4, "Imagine Dragons": 3,
"Lorde": 3, "Fall Out Boy": 1},
"Chris": {"Kacey Musgraves": 4, "Imagine Dragons": 4,
"Daft Punk": 4, "Lorde": 3, "Fall Out Boy": 1},
"Tori": {"Kacey Musgraves": 5, "Imagine Dragons": 4,
"Daft Punk": 5, "Fall Out Boy": 3}}
def computeSimilarity(band1, band2, userRatings):
averages = {}
for (key, ratings) in userRatings.items():
averages[key] = (float(sum(ratings.values())) /len(ratings.values()))
num = 0 # 分子
dem1 = 0 # 分母的第一部分
dem2 = 0
for (user, ratings) in userRatings.items():
if band1 in ratings and band2 in ratings:
avg = averages[user]
num += (ratings[band1] - avg) * (ratings[band2] - avg)
dem1 += (ratings[band1] - avg) ** 2
dem2 += (ratings[band2] - avg) ** 2
return num / (sqrt(dem1) * sqrt(dem2))
print computeSimilarity('Kacey Musgraves', 'Lorde', users3)
print computeSimilarity('Imagine Dragons', 'Lorde', users3)
print computeSimilarity('Daft Punk', 'Lorde', users3)
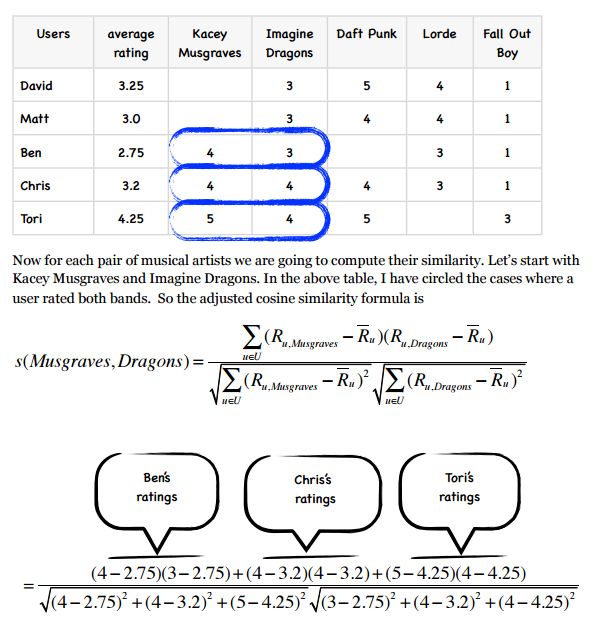
得到的结果填入表中:

3. 利用相似度矩阵进行预测
公式如下图,p(u,i) 指的是用户u将对物品i的评分的预测值(即用户u对物品i的喜欢程度)。
N 是用户u的所有评级物品中每个和物品i得分相似的物品。存在在相似度矩阵中。R(u,N) 是u给N的评分。S(i,N)是i和N的相似度。

4. 对用户的打分结果归一化
类似皮尔逊相关系数对结果做处理的原因,让用户对物品的评分结果值位于-1到1之间。
公式如下图所示,NR(u,N) 是归一化的结果,即用户u对物品N打分的结果的处理。MinR表示评级范围(比如1~5)中的最小值,MaxR表示最大值。

计算举例,很简单,比如某人的对某本书的打分是2分,归一化后结果如下:
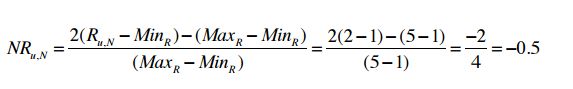
将第3点里面的预测用户打分的公式更新为:

最后用归一化的结果反推真实的分数公式:

就得到了预测的打分。
5. Slope One 算法
据说 Slope One 算法简洁,易实现,来自 Daniel Lemire 和 Anna Machlachlan 的论文 ↓
Slope One Predictors for Online Rating-Based Collaborative
Filtering” by Daniel Lemire and Anna Machlachlan (http://www.daniel-lemire.com/fr/abstracts/SDM2005.html).
1. 问题描述
假设 Amy 给 PSY 打了 3分,给 WH 打了 4 分,Ben 给 PSY 打了 4 分,想预测 Ben 给 WH 打多少分?
描述如图:
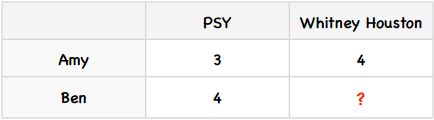
我们直观进行预测,依据只能是 Amy 对 WH 的打分,相对而言,Ben 对 WH 的打分可能是 5 分。
Slope One 算法将问题看成两部分:
第一部分: 计算所有物品对的偏差
第二部分: 利用偏差进行预测
2. 计算偏差
数据如下:

计算物品i 到 物品j 的平均偏差的公式:
其中,card(S) 是S集合中的元素个数,X 是整个评分集合。
card(S(X))即为所有同时对i和j评分的用户个数。

举个例子:

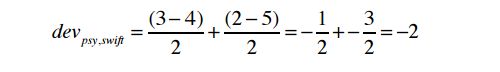
3. 利用加权的 Slope One 算法进行预测
公式如下:
该公式最终得出的结果是用户对某物品的打分的预测值。其中,c(i,j) 表示所有同时对物品i和物品j打分的用户数。

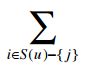
公式看似复杂,计算却不复杂,举个例子:
给出了Ben的评分表及物品之间的偏差表:


6. 加权 Slope One : 推荐模块
通过 Slope One 算法得出用户对某一商品的预测值,如何对用户推荐呢?
(整个的利用 Slope One 算法推荐商品的代码在这里)
- 先从一大堆商品中找出用户没有打过分的商品,并且用户评过分的商品与未评过分的商品之间的偏差存在。
- 用 Python 程序计算所有用户对未评过分的商品的可能评分。
- 根据预测分数由高到低展示出来(可只展示前几项),排名越靠前,推荐给用户的可能性越高。
作业:对 数据集 中的10部影片进行评级,看看 Slope One 推荐系统会给你推荐哪些影片。