强大的List Comprehension (列表推导式)是Python中必须知道的概念。然而对于初学者来说是最具挑战性的。掌握这个概念将会在两个方面帮助你:
- 应该写更短和更高效率的代码
- 代码应该执行的更快
List Comprehension (列表推导式)比for循环快35%,比map快45% 。
注:下面将List Comprehension (列表推导式)简写为LC
什么是LC
看下面的例子:
{ x^2: x 是小于10的自然数 }
{ x: x是小于20的偶数 }
{ x: x是在 ‘MATHEMATICS’中的元音字母 }
对于初学者乍一看缺失有点懵逼,来让我们仔细观察。
每个例子包含三个方面:迭代,过滤条件,执行过程
因此,也可以认为这个只是for循环的另一种表现形式。
总之,一个for循环这样执行:
for (set of values to iterate):
if (conditional filtering):
output_expression()
同样用LC形式构造一行:
[ output_expression() for(set of values to iterate) if(conditional filtering) ]
另一个例子: { x: x是小于等于100的自然数, x的完全平方数 }
for循环写法:
for i in range(1,101): #the iterator
if int(i**0.5)==i**0.5: #conditional filtering
print i #output-expression
LC 写法:
[i for i in range(1,101) if int(i**0.5)==i**0.5]
找到一些感觉没?如果你理解了,那么LC是更简单且有效的强力工具,帮助你轻松完成很多工作。
记住:
- 1.List循环总是返回一个结果,无论你是否用到这个结果。
- 2.迭代和条件表达式可以嵌套多个实例。
- 3.甚至整个List循环都可以嵌套在另一个List循环中
- 4.多个变量可以同时迭代和操纵
应用1:平坦化矩阵(Flatten a Matrix)
目标:将一个矩阵输入,返回一个List,每一行放在一行的后面。
代码如下:
def eg1_for(matrix):
flat = []
for row in matrix:
for x in row:
flat.append(x)
return flat
def eg1_lc(matrix):
return [x for row in matrix for x in row ]
让我们定义一个矩阵,测试下结果:
matrix = [ range(0,5), range(5,10), range(10,15) ]
print "Original Matrix: " + str(matrix)
print "FOR-loop result: " + str(eg1_for(matrix))
print "LC result : " + str(eg1_lc(matrix))

应用二:将一个句子中的元音字母去掉
目标:一个string作为输入,返回一个去除元音字母的string
代码如下:
def eg2_for(sentence):
vowels = 'aeiou'
filtered_list = []
for l in sentence:
if l not in vowels:
filtered_list.append(l)
return ''.join(filtered_list)
def eg2_lc(sentence):
vowels = 'aeiou'
return ''.join([ l for l in sentence if l not in vowels])
测试下:
sentence = 'My name is Aarshay Jain!'
print "FOR-loop result: " + eg2_for(sentence)
print "LC result : " + eg2_lc(sentence)
应用三:字典推导式( Dictionary Comprehension)
目标:两个一样长度的List作为输入,返回一个字典,其中一个key,一个作为value
代码如下:
def eg3_for(keys, values):
dic = {}
for i in range(len(keys)):
dic[keys[i]] = values[i]
return dic
def eg3_lc(keys, values):
return { keys[i] : values[i] for i in range(len(keys)) }
测试:
country = ['India', 'Pakistan', 'Nepal', 'Bhutan', 'China', 'Bangladesh']
capital = ['New Delhi', 'Islamabad','Kathmandu', 'Thimphu', 'Beijing', 'Dhaka']
print "FOR-loop result: " + str(eg3_for(country, capital))
print "LC result : " + str(eg3_lc(country, capital))

到现在,我们都集中在LC的第一印象,即它的简洁和可读性。但这还不止!LC在各种场景中相比表现的更快。让我们进一步探讨,这里不做详细介绍。
在数据分析中的应用
对于数据分析,LC也是非常有用。
一个快速的回顾,记住LC的结构:
[ output_expression() for(set of values to iterate) if(conditional filtering) ]
应用4:读双重LIst
可能遇到过这样的场景,在数据集中每个列都包含一个LIst。下面我们举例说明,数据集包含两列:
- personID: 独一无二
- skills: 每个人会的运动
Lets load the dataset:
import pandas as pd
data = pd.read_csv("skills.csv")
print data

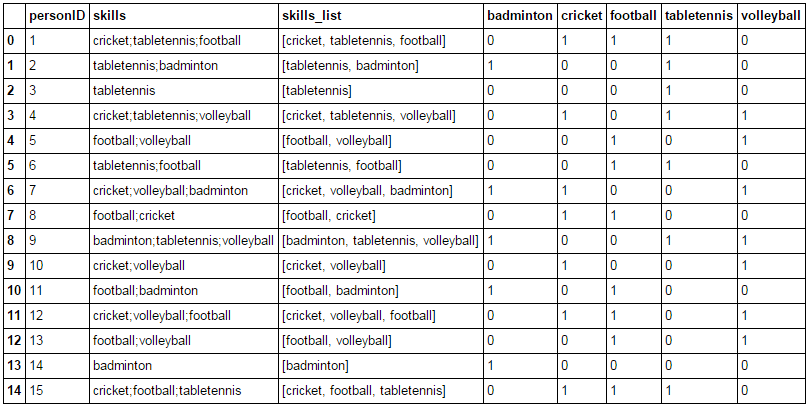
在这里,每个人会多种不同的运动。将这些数据永在预测模型,一个好主意通常是来创建一个新的列每个运动和将其标记为1或0。
第一步是将文本转换成可以访问列表,这样单独的条目。
#Split text with the separator ';'
data['skills_list'] = data['skills'].apply(lambda x: x.split(';'))
print data['skills_list']

接下来,我们需要一个独特的运动列表来确定所需的不同的列数。这可以通过理解,独特元素构成的set(集合)。
#Initialize the set
skills_unq = set()
#Update each entry into set. Since it takes only unique value, duplicates will be ignored automatically.
skills_unq.update( (sport for l in data['skills_list'] for sport in l) )
print skills_unq
注意,这里我们使用生成器表达式,这样每个值不必动态更新和存储。现在我们使用LC将生成一个与0 - 1矩阵包含5列标记相应的运动。
#Convert set to list:
skills_unq = list(skills_unq)
sport_matrix = [ [1 if skill in row else 0 for skill in skills_unq] for row in data['skills_list'] ]
print sport_matrix

最后一步是生用Pandas DataFrame 合成:
data = pd.concat([data, pd.DataFrame(sport_matrix,columns=skills_unq)],axis=1)
print data
应用5:为多项式回归创建一列权值(Creating powers of a columns for Polynomial regression)
多项式回归算法需要多种权值相同的变量,它可以使用LC创建。多达15 - 20的相同的变量可以用在岭回归分析建模以及减少过度拟合。
让我们简单的创建一列数据集:
data2 = pd.DataFrame([1,2,3,4,5], columns=['number'])
print data2

我们定义一个变量 “deg”,包含要求的程度。我们第一步是创建一个矩阵包含不同权值的‘number’ 变量。
#Define the degree:
deg=6
#Create the matrix:
power_matrix = [ [i**p for p in range(2,deg+1) ] for i in data2['number'] ]
print power_matrix

与前面的示例相似,现在我们将添加到dataframe。注意,在这种情况下,我们需要一个列名列表和LC可以用来容易获取它:
cols = ['power_%d'%i for i in range(2,deg+1)]
data2 = pd.concat([data2, pd.DataFrame(power_matrix,columns=cols)],axis=1)
print data2

应用6:过滤列名(Filtering column names)
个人而言,我面临过很多次这种问题,为了一个预测模型预测,选择dataframe中列的一个子集,。让我们考虑这种情况的总列:
cols = ['a', 'b', 'c', 'd',
'a_transform', 'b_transform', 'c_transform',
'd_power2', 'd_power3', 'd_power4', 'd_power5',
'temp1', 'temp2']
可以理解为:
- 1.a,b,c,d:原始数据列
- 2.a_transform,b_transform,c_transform:转换后的特征,比如log,平方根等等
- 3.d_power2,d_power3,d_power4,d_power5::相同变量的不同的权值对于多项式或者岭回归
- 4.temp1, temp2:中间变量创建执行特定的计算
根据正在执行的分析或使用的模型,可能有不同的用处: - 1.选择转换的变量
- 2.选择不同权值相同的变量
- 3.选择超过2个的组合
- 4.选择所有,除了临时变量
代码如下:
col_set1 = [x for x in cols if x.endswith('transform')]
col_set2 = [x for x in cols if 'power' in x]
col_set3 = [x for x in cols if (x.endswith('transform')) | ('power' in x)]
col_set4 = [x for x in cols if x not in ['temp1','temp2']]
print 'Set1: ', col_set1
print 'Set2: ', col_set2
print 'Set3: ', col_set3
print 'Set4: ', col_set4

End Notes
如果你已经达到这一点,我相信,现在你能够欣赏LC的重要性。你应该试着把这种技术在日常实践。尽管它可能会耗费不少时间开始,但是相信我当你进步时你会十分享受。
这篇文章能对你有帮助吗?我遗漏了什么了吗?你有一些更有趣的应用吗,您认为LC会有用吗?请分享你的评论,我们一起讨论。
英语原文链接:
https://www.analyticsvidhya.com/blog/2016/01/python-tutorial-list-comprehension-examples/