这学期刚回到所里的时候把c++数据结构看了一遍,基本的数据结构照着视频也敲了一遍,不过那个时候自己对c++的了解只限于一些基本的语法,c++primer也还没有看,对于数据结构的了解也很有限,只是硬抄下来了,最近刷题感觉到这块还是不太熟悉,所以又想到把这里重新写一遍,这一遍不能是硬抄了,每一个函数或者功能,先自己试着实现,如果遇到困难再去看视频,然后再写,这样应该能学的快一些,这里顺便做做笔记,以供自己以后复习。
写的代码我就放在这里
栈
栈是一种常用的数据结构,特点是:先进后出
根据构成的不同,栈一般有两种写法,一种是用数组,一种是用链表,这里只说明用数组的写法。
首先我们应该明白这个栈应该有下面的基本功能:
- 进栈。
- 出栈。
- 删除栈顶
- 栈是否为空
……
我们利用c++的模板类来创建栈类,做一个简单的,由上面说的功能,可以写出简单的类:
class MYstack
{
public:
MYstack(int stackCapacity = 10); //默认大小是10
~MYstack(); //析构函数
bool IsEmpty() const; //是否为空
T &Top() const; //栈顶元素
void Push(const T& item);
void Pop(); //删除栈顶元素
private:
T * stack; //利用这个指针动态创建数组
int top; //记录栈顶的位置
int capacity; //容量
};
这个写起来还是比较简单,直接把代码贴在下面。
#ifndef MY_stack
#define MY_stack
#include"myUtil.h"
template
class MYstack
{
public:
MYstack(int stackCapacity = 10); //默认大小是10
~MYstack();
bool IsEmpty() const;
T &Top() const; //栈顶元素
void Push(const T& item);
void Pop(); //删除栈顶元素
private:
T * stack; //利用这个指针动态创建数组
int top; //记录栈顶的位置
int capacity; //容量
};
//构造函数
template
MYstack::MYstack(int stackCapacity) :capacity(stackCapacity)
{
if (capacity < 1) throw "stack size must be >0";
stack = new T[capacity];
top = -1; //表示堆栈是空的
}
//析构函数
template
MYstack::~MYstack()
{
delete[] stack;
}
//是否为空
template
inline bool MYstack::IsEmpty() const
{
return top==-1;
}
//栈顶元素
template
inline T & MYstack::Top() const
{
if (this->IsEmpty()) throw "the stack is empty";
return stack[top];
}
//进栈
template
inline void MYstack::Push(const T & item)
{
if (top == capacity - 1) //如果满了,把数组放大
{
ChangeSize1D(stack, capacity, capacity * 2);
capacity *= 2;
}
stack[++top] = item; //先把top++,然后把这个数放进去。
}
//删除栈顶
template
inline void MYstack::Pop()
{
if (this->IsEmpty())
throw "the stack is empty,can not be deleted!";
//top--; //简单的删除这样就可以了
stack[top--].~T();
}
#endif // ! MY_stack
这里面有一个工具函数,是增加数组数量的一个,放在另外一个头文件里。
#ifndef _MYUTIL_H
#define _MYUTIL_H
int min(int a, int b)
{
if (a < b)
return a;
else return b;
}
template
void ChangeSize1D(T * &a, const int oldSize, const int newSize)
{
if (newSize < 0) throw "new length must be >=0";
T *temp = new T[newSize];
int number=min(oldSize,newSize); //这么多数
std::copy(a, a + number, temp); //拷贝过去
delete[] a;
a = temp; //指针指向新建的这个
}
#endif
代码里注释已经写的已经很清楚了,说一下要注意的几点:
- 不要忘记判断堆栈是否为空的情况,这是一种特殊情况。
- 删除栈顶的时候,可以top下移,更好的一种方法就是调用T的析构函数把所占的内存释放掉。
还有一个东西,和堆栈无关,是使用VS的时候可能会遇到的一个问题,以前遇到过,这次又遇到了。
在使用std::copy()的时候遇到的编译错误:
错误 C4996 'std::copy::_Unchecked_iterators::_Deprecate': Call to 'std::copy' with parameters that may be unsafe - this call relies on the caller to check that the passed values are correct. To disable this warning, use -D_SCL_SECURE_NO_WARNINGS. See documentation on how to use Visual C++ 'Checked Iterators' Data_Structrue c:\program files (x86)\microsoft visual studio 14.0\vc\include\xutility 2372
大概的意思说,copy这个函数可能是不安全的,copy的数据如果比被考入的容器的数量大的话很明显是不安全的,可以使用这样的一个预编译指令来忽略这样的一个编译命令-D_SCL_SECURE_NO_WARNINGS来忽略警告。
具体的操作方式是:项目--属性
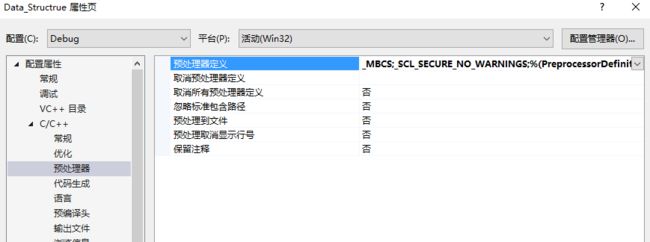
预处理器定义处添加:_SCL_SECURE_NO_WARNINGS,然后重新debug就没有问题了。
除了上述处理方法之外,还有一种比较简单的方法,添加一个
#pragma预处理来消除警告:
#pragma warning(disable:4996)
这样就没有问题了。
这一段参考 这里.
队列
队列和栈刚好是相反的,其主要特点是先进先出,后进后出。
依然的,我们设计一个简单的队列,需要下面几个功能:
- 访问队首和队尾。
- 删除队首(因为先进后出,所以只能删除队首)。
- 队尾插入元素。
- 判断是否为空。
根据这个要求,我们可以很容易写出队列的类的定义。
template
class MyQueue
{
public:
MyQueue(int queueCap = 10); //构造函数
bool IsEmpty() const;
T & Front() const;
T & Rear() const;
void Push(const T &item);
void Pop();
int getCap()
{
return capacity;
}
private:
T *Queue;
int front; //队首
int rear; //队尾
int capacity;
};
getCap()函数是我写来测试插入的时候是否增加了队列的容量。在设计这个队列时,延续了视频作者的思路,队首是空的,不存放任何元素。
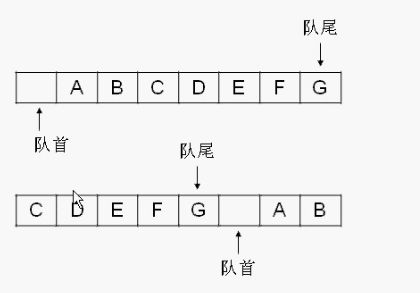
这样主要是为了判断队列是否是满的方便,判断满的条件应该是
(队尾+1)%capacity==队首,如果队尾和队首都放元素,这样判断的条件就是
队首==队尾,可是当队列为空的时候也是满足的,处理这个问题的一个好的方法就是把队首位置空出来,实际上的对象是从队首的下一个位置开始的。
有两点要注意的地方。
- 环绕现象
其他成员函数和堆栈的设计都有点像,但是要注意的是为了充分利用数组空间,我们允许循环移位,也就是说,如果插入的时候到了最右边,如果左边还有位置(可能队首被删除掉一部分),循序把元素插入到队首之前(这里的左右是针对于上面那张图说的)。
所以在插入和删除的时候要注意下这种环绕现象,这种寻址可以通过这样一个技巧来做:这两种写法是一样的,推荐第二种。
1.------------
if (rear == capacity - 1) //是不是最后一个
rear = 0;
else
{
rear++;
}
2.----------
rear = (rear + 1) % capacity;
-
扩充容量时要复制
另外一个值得注意的地方是扩充容量的时候要复制,这个不像堆栈那么简单了,我们不是把整个数组里的数据全部复制过来,而是按照队首到队尾的顺序铺展开再复制过去。
这样就有两种情况:环绕和不环绕。
没有环绕的话,队首肯定还是在第一个位置,队尾在最后一个位置。这样直接复制就行了。
环绕的话,要分两次去复制。
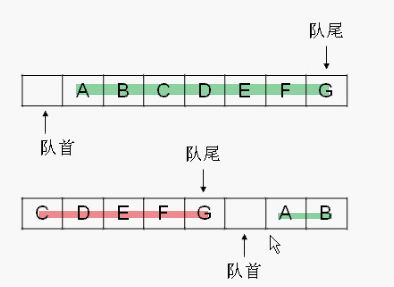 队列扩充示意
队列扩充示意
如图,第一个的话就直接复制后面的元素就行,对于第二个,先复制绿色的,然后在复制红色的。
主要代码为:
if ((rear + 1) % capacity == front) //如果满了增加一倍
{
T *newQueue = new T[2 * capacity];
int start = (front + 1) % capacity;
if (front < rear) //如果没有发生循环回绕
{
std::copy(Queue+start, Queue+capacity-1, newQueue+1);
}
else
{
std::copy(Queue+start, Queue+capacity - 1, newQueue+1); //复制后半部分
std::copy(Queue, Queue+rear, newQueue + 1 + (capacity - front - 1)); //复制前半部分
}
delete[] Queue;
Queue = newQueue;
front = 0;
rear = capacity;
capacity *= 2;
}
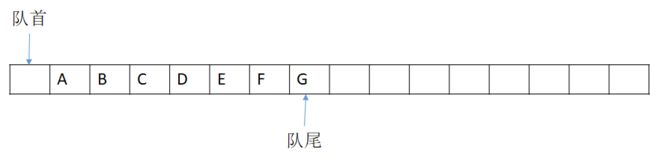
复制结束之后应该是这样的。
整个代码贴在下面:
#pragma once
#ifndef Queue_H
#define Queue_H
//这个队列队首是不存任何数据的,为了编程方便
template
class MyQueue
{
public:
MyQueue(int queueCap = 10); //构造函数
bool IsEmpty() const;
T & Front() const;
T & Rear() const;
void Push(const T &item);
void Pop();
int getCap()
{
return capacity;
}
private:
T *Queue;
int front;
int rear;
int capacity;
};
#endif // !Queue_H
template
inline MyQueue::MyQueue(int queueCap):capacity(queueCap)
{
if (capacity < 1) throw"queue capacity must be >=0";
Queue = new T[capacity];
front = 0;
rear = 0;
}
template
inline bool MyQueue::IsEmpty() const
{
return (front==rear); //队首和队尾相等就认为是空的
}
template
inline T & MyQueue::Front() const
{
if (this->IsEmpty())
throw"empty queue has no front";
return Queue[(front+1)%capacity];
}
template
inline T & MyQueue::Rear() const
{
if (this->IsEmpty())
throw"empty queue has no rear";
return Queue[rear];
}
template //主要是这个函数困难
inline void MyQueue::Push(const T & item)
{
//if (rear == capacity - 1) //是不是最后一个
// rear = 0;
//else
//{
// rear++;
//}
//这种写法可以写为 rear = (rear + 1) % capacity;
if ((rear + 1) % capacity == front) //如果满了增加一倍
{
T *newQueue = new T[2 * capacity];
int start = (front + 1) % capacity;
if (front < rear) //如果没有发生循环回绕
{
std::copy(Queue+start, Queue+capacity-1, newQueue+1);
}
else
{
std::copy(Queue+start, Queue+capacity - 1, newQueue+1); //复制后半部分
std::copy(Queue, Queue+rear, newQueue + 1 + (capacity - front - 1)); //复制前半部分
}
delete[] Queue;
Queue = newQueue;
front = 0;
rear = capacity;
capacity *= 2;
}
else
{
rear = (rear + 1) % capacity;
Queue[rear] = item;
}
}
template
inline void MyQueue::Pop()
{
if (this->IsEmpty())
throw"empty queue can not be deleted";
front = (front + 1) % capacity; //处理循环
Queue[front].~T(); //析构掉这个数据
}
链表
略,这部分我刷题时写了一部分,算比较熟了,以后有时间再写。
树
树是一种很常用的数据结构,结合了数组和链表的优点,插入以及查找的速度都是非常快。
常见的一些概念:
节点:这个很明显,没什么说的,一个数据对象为一个节点,最顶为树根节点。
度:每一个节点对应子树的个数叫做这个节点的度。对于二叉树来说这个度可能是0,1,2.
叶节点:没有子节点的节点成为叶节点,对应的由非叶结点。
父节点和子节点:节点之间的关系。
兄弟节点:同一层的节点互称兄弟节点。
树的深度:树的层数。
四种遍历方法:前序,后序,中序,层遍历,前三种是根据节点来说的,节点在前称作前序遍历,在后称作后序遍历,其他以此类推,层遍历即一层一层地遍历。
基本二叉树
这里我们先设计一个基本的二叉树,对于元素的位置先不做要求,用链表的思路来做,每一个树节点有两个指针,分别指向左右,来形成这么一个树。
那么对于一个基本的二叉树来说,这个树一旦形成,重要的就是如何去遍历这个树了,遍历的方法上面说过了,总共有四种。
先看树和树节点的定义:
//树节点类
template
class TreeNode
{
public:
TreeNode(const T &x)
{
data = x;
leftChild=nullptr;
rightChild = nullptr;
}
T data;
TreeNode *leftChild;
TreeNode *rightChild;
};
//树类
template
class BinaryTree
{
public:
void InOrder(); //中序遍历
void InOrder(TreeNode *currentNode);
void PreOrder(); //前序遍历
void PreOrder(TreeNode *currentNode);
void PostOrder(); //后序遍历
void PostOrder(TreeNode *currentNode);
void LevelOrder(); //层序遍历
void Visit(TreeNode *currentNode)
{
//这里也可以做其他的处理
std::cout << currentNode->data << "--";
}
TreeNode *root;
};
这里数据成员和指针都设计成public的是因为我们在遍历的时候要访问到这个数据,否则就要再写接口函数。
有了上面的定义我们就可以手动生成一个二叉树了,我们用A--G生成一个3层的二叉树,来做一个测试,树的结构如图:
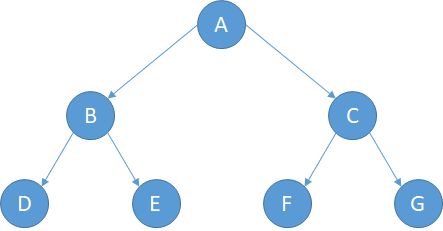
//先生成树节点,然后把节点链接起来
BinaryTree Tree;
TreeNode a('A');
TreeNode b('B');
TreeNode c('C');
TreeNode d('D');
TreeNode e('E');
TreeNode f('F');
TreeNode g('G');
// A
// / \
// B C
// / \ / \
// D E F G
Tree.root = &a;
a.leftChild = &b;
a.rightChild = &c;
b.leftChild = &d;
b.rightChild = &e;
c.leftChild = &f;
c.rightChild = &g;
然后我们来进行遍历:前序,后序,以及中序这三种的遍历方式是类似的,主要是利用了递归的思想(说实话,每次要用到递归心力都很抵抗),不过还好这个递归还是比较简单的(至少写起来是这样)。
以中序遍历为例:对于当前节点来说,我们先遍历其左子节点(左子节点有子节点时还要继续,直到没有),然后到右子节点(右子节点有子节点时要继续,直到没有),这用文字描述都是一个递归。
设计了另外一个函数去完成这样的一个过程:
template
inline void BinaryTree::InOrder()
{
InOrder(root);
}
//这是一个递归的写法
template
inline void BinaryTree::InOrder(TreeNode *currentNode)
{
if (currentNode) //不为空就可以做迭代
{
InOrder(currentNode->leftChild);
Visit(currentNode);
InOrder(currentNode->rightChild);
}
}
这样是一个递归的写法,看着程序自己慢慢理解吧,我也不知道怎么讲清楚,到现在我也没有真正的理解递归的写法技巧。
重点是想说一下层序遍历:
层序遍历显然是利用不了递归来做的,因为每一层的子节点都不一样,一种简单的方法是用队列来做吗,而且这么做也很巧妙得利用了队列的特点(先进先出),通过一系列操作,使得处在队首的始终是下一个要遍历的元素。
具体的操作是:先把根节点放入队列,然后把根节点的左右子节点依次放入队列(如果有的话),这样队列里现在有A,B,C,然后显示队首,再把队首删掉,然后把新的队首的左右子节点一次放入队列(如果有的话),依次类推,直到队列中没有元素为止。画一个图来更清晰些看到这种技巧:
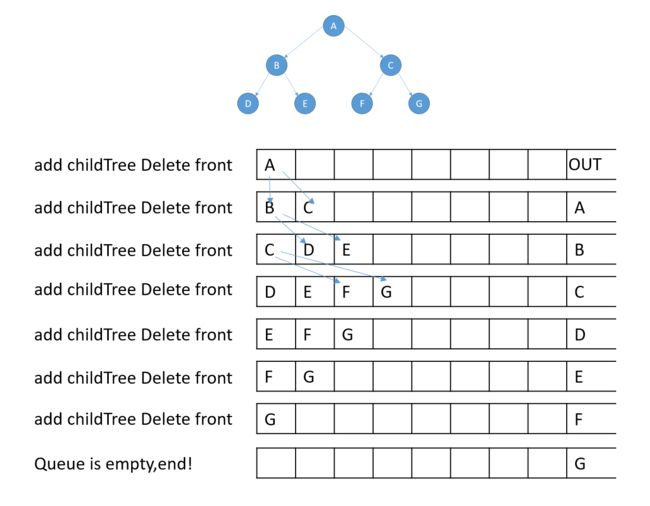
写起来也比较简单:直接利用的STL的队列来做,很好用。
//层序遍历使用队列来做,先进先出。
template
inline void BinaryTree::LevelOrder()
{
if (root == nullptr)
return;
std::queue *> q; //新建一个队列
q.push(root); //把根放进去
while (!q.empty())
{
Visit(q.front());
if(q.front()->leftChild) //如果有左树,放进队列,右树同理
q.push(q.front()->leftChild);
if (q.front()->rightChild)
q.push(q.front()->rightChild);
q.pop();
}
}
这个完整的代码我就不贴了,可以去上面开始给的github的链接里去找,主体代码和思路已经展示到这里了。
2018/1/23更新
二叉查找树
二叉查找树在二叉树基础上来的,符合二叉树所有的特点,另外定义了下面的规则:
- 每一个节点有一个键值,且不同节点的键值不允许重复。
- 每一个节点左子节点键值要比自身小,每一个右节点的键值要比自身大。
- 左右子树都是二叉查找树。
符合上述条件的二叉树称作二叉查找树,二叉查找树的优点是插入和查找元素都比较快。当然这个是在一定条件下,同样的数据,如果根据不同的顺序插入进来,有可能退化成一个链表,这样的话就失去了二叉查找树的优点。
今天做一个简单的二叉查找树,做出基本插入和查找的功能。
和二叉树不同的是,节点必须有一个可以比较大小的键值,所以我们把节点的data另外设计成一个数据类型,暂且称作element,element要有键值,还可以有其他数据元素。
template
class Element
{
public:
T key;
//可以添加其他数据类型
};
节点的类:
class BTreeNode
{
public:
friend class BST; //友元类,要访问数据和节点
Element data;
private:
BTreeNode *leftChild=nullptr;
BTreeNode *rightChild=nullptr;
void display(int i);
};
这次把数据和左右指针都设计成私有的,把二叉树的类设计成它的友元类以便可以访问私有成员(这里的data改成公有的是因为后面验证查找的结果用了一下)。
display是一个显式函数,定义为:
template
inline void BTreeNode::display(int i)
{
std::cout << "position:" << i; //显式节点的位置,在二叉树中的位置
std::cout << "\tdata:" << data.key << endl;
if (leftChild) leftChild->display(2 * i);
if (rightChild) rightChild->display(2 * i + 1);
}
这是一个递归显式,显式以此节点为根节点的所有节点。他们的位置是这么一个关系,按照一层一层的顺序排的话,左子节点的位置是父节点的2倍,右子节点+1。(根节点为1,画个图就知道了)。这个不是按照层遍历的,是一个前序遍历的形式显式的。
下面看BST的类定义:
template
class BST
{
public:
BST(BTreeNode *init)
{
root = init;
}
BST()
{
root = nullptr;
}
MyBool Insert(const Element &element); //插入,这也是一种二分插入的速度
BTreeNode* Search(const Element &element); //查找,这实际上是一种二分查找
BTreeNode* Search(BTreeNode *, const Element &element); //递归查找辅助函数
BTreeNode* IterSearch(const Element &element); //用循环写一个查找
void display()
{
if (root)
root->display(1);
else
std::cout << "empty tree!" << std::endl;
}
private:
BTreeNode *root=nullptr; //树根
};
最上面是两个构造函数,可以利用一个节点作为根节点来构造一棵二叉查找树,也可以构造一棵空树(想起一个《对对联》中的一个结尾上联:空树藏孔,孔进空树空树孔,孔出空树空树空)。
Insert();函数,插入。
Search(); 这个是递归写的,下面有个辅助函数。
IterSearch(); 这是用循环写的,也很简单。
displa(); 显示用的。
主要说一下插入和查找。
1. 插入
插入的时候首先要找到一个位置:这还是一个二分查找的一个思路。
首先:如果是空树,那么就把根节点初始化为这个节点就好了。
如果不是空树,那么就根据当前节点和要插入节点键值的大小来决定前往左子树还是右子树,直到找到一个空位置。这个位置就是要插入的位置,我们需要把这个位置的父节点记录下来,所有还需要一个指针,写起来也比较简单:
template
inline MyBool BST::Insert(const Element& element)
{
BTreeNode *p = root;
BTreeNode *q = nullptr;
while (p)
{
q = p; //把p的父节点保存起来,p下面会移动到子节点上
if (element.key == p->data.key) return FALSE;
else if (element.key < p->data.key)
p = p->leftChild;
else if (element.key >p->data.key)
p = p->rightChild;
}
//当循环结束之后,这个时候,就找到了一个位置,这个位置是q的左子或者右子;
p = new BTreeNode; //新建一个节点
p->data = element; //把数据赋值
if (!root)
root = p; //如果树本身是空的,那么新的节点就是根了。
//根据不同的情况,选择插入到哪边
else if (element.key < q->data.key)
q->leftChild = p;
else if (element.key > q->data.key)
q->rightChild = p;
return TRUE;
}
2. 查找。
2.1: 迭代查找
这个也比较简单,可以参考上面插入while循环里的那一段,但是不需要记录父节点位置,因为不是插入,只需要找到这个节点就可以,很简单,代码放下面:
template
inline BTreeNode* BST::IterSearch(const Element& element)
{
BTreeNode *tmp = root;
if (tmp == nullptr)
return nullptr;
while (tmp)
{
if (tmp->data.key == element.key)
return tmp;
else if (tmp->data.key < element.key)
tmp = tmp->rightChild;
else
tmp = tmp->leftChild;
}
return nullptr;
}
要注意的是把root复制一份,再做查找,因为这个节点的指向会发生变化,如果直接用root,查找倒是可以查找到,树就找不到了。
2.2 :递归查找
我确实有点恐惧递归,但是这个查找的递归说真的还真的不算难:
template
inline BTreeNode* BST::Search(const Element& element)
{
return Search(root, element);
}
template
inline BTreeNode* BST::Search(BTreeNode* b, const Element& element)
{
if (!b) return nullptr;
if (element.key == b->data.key) return b;
if (element.key < b->data.key)
return Search(b->leftChild,element);
if (element.key > b->data.key)
return Search(b->rightChild, element);
}
也是一个二分的思路,二分的两个大小判断一定要用if和else,这里因为直接return了,所以不用也没有关系,但是作为一种良好的编程习惯,还是应该用else。
差不多就这样了,最开始说了,二叉查找树的致命缺点是很严重的,这种树往往是不平衡的,所以后续的还有平衡二叉树的出现,以及红黑树等等,后面在讨论。
未完待续