作为刚刚学习C的新手,水平较低,难免出错。希望各位前辈不吝赐教,批评指正。
在C语言学习了一段时间之后,我们开始入了课程设计。初学了一些简单的语法之后,感觉要完成一项工程还是有些困难的。
听说在写课程设计时,比起一下子打出来完,不如分模块,分功能的有步骤的去写。
课程设计的核心,是对链表的操作,实现动态链表的增、删、改、查。这里主要说一下课程设计的思路和想法。
对于链表的具体操作,诸君都比我水平高,不敢赘言,就简单提一下。
1.显示主菜单
在复杂面前,先做一些微不足道的小工作。先把菜单的内容写了出来,在主函数里调动menu()就会出来这个直接显示的界面。

其实一开始,考虑到menu()只是用来显示,我就把它定义成了void型,后来在学长的提醒下,把void改为了int,原来在一些其他的编译器里,void型被淘汰或者是会报错。为了养成良好的编程习惯,就把剩下的void都改成了int或其他。
2.操作菜单
接下来,在操作菜单里,填写以下内容 :

这个就是提供一个选择功能的途径,至于功能,之后再补全,总之先把位置留出来。
通过输入数字的方式来选择功能,在1--8的范围内(图中的printf是添加读档功能前的7个,不必在意),输入正确就让flag=1,如果输入其他的,那就循环回来重输。
至于那个while里的判断(真or假),只要n不在1--8,就一直为真,一直循环,当然你要是高兴,把(flag==0)换成(1)也行。
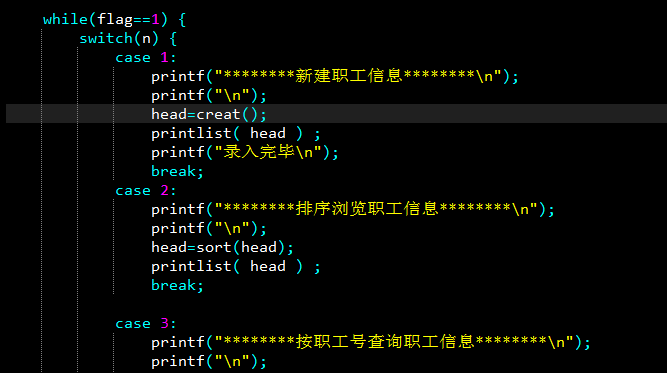
上一步对flag的操作,目的就是为了引出下面的循环,在正确的选择功能里,通过swich实现相关功能的函数调动,n也就是用到这里,当然在一开始并没有这些函数,我只是写了printf和break而已。
为了方便起见,我把switch里的内容先折叠一下。
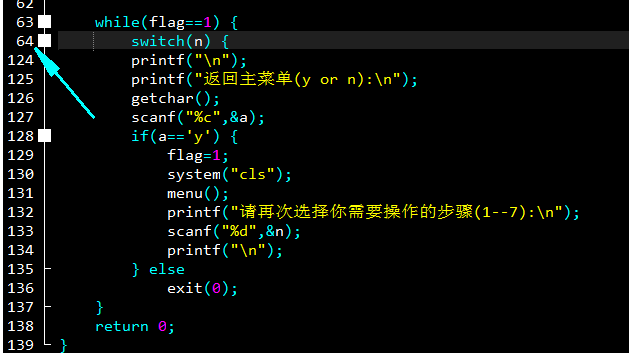
在你选择并实现了相关功能以后,顺序执行,在125行进行询问是否继续,并且通过getchar()来获取一个字符。如果y(yes),再次获取n,再次循环,周而复始。
如果输入其他的,那就直接退出了exit(0)。
(函数exit()通常是用在子程序中用来终结程序用的,要加上头文件#include
3.创建链表
说起创建链表,大家都有自己的做法。我的做法就是定义了两个结构体指针,先共同赋了一片空间,为p1赋值,(图中的sca就是我调动赋值的函数)。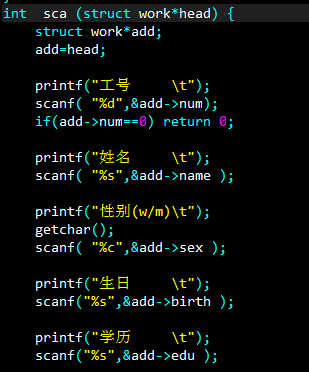
其实再一开始,我就声明了一个全局变量:
struct work*head=NULL;
在之后的对链表操作都是在对头进行操作。让链表停止的操作,就是在初始化时,使工号为0。在第一个节点时,需要特殊处理一下,即令p和head指向同一片空间,这样就能起到 拿起链表头就能拿起一串的效果。
之后的操作就司空见惯了,让p1申请空间并赋值,再让p2指向p1所开辟的新空间,循环往复的增加节点,直到工号为0时停止。
最后,别忘了单链表的尾要置空。最后的返回值就是把“头head”返回去了,因而可以实现case 1里的 head=creat(head)了。
*那个system("cls")是后来为了美观加上的,在前期修改时为了及时的反馈问题,尽量不要加。
4.显示节点和链表
刚刚做了一套貌似复杂的操作,现在我们来看一些轻松的东西。
在我们对链表进行操作时,难免要经常查看节点和整个链表,要是每次都输出的话那是多么的繁琐,不如直接调动函数。我就写了两个方便自己查看的,一个是看单个节点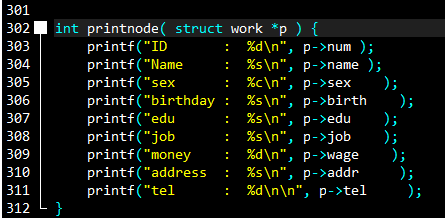
如你所见,传入参数结构体指针,把每一个数据成员都显示出来。
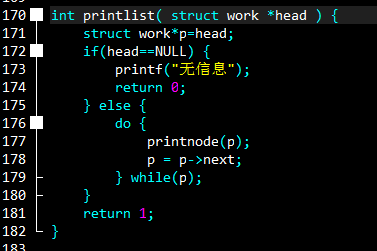
另一个是显示整个链表,把头head传进来,为了防止对head进行误操作,临时定义结构体指针p。令p和head指向同一片空间,再通过 do-while 对p进行遍历。在printnode()的基础上输出一个一个又一个的节点。
5.增加
毫无疑问,这是这里面最简单的功能操作。
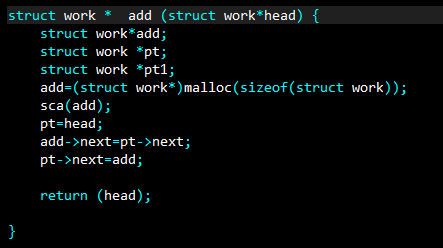
如你所见,为了图方便,我甚至都没有去找最后的节点插入,而是就直接放到了头结点的后面。反正就算只有一个节点也可以放到后面。
6.查找
除了增加以外,最简单的就算是查找了,因为这个遍历的过程,会是其他功能的基础。
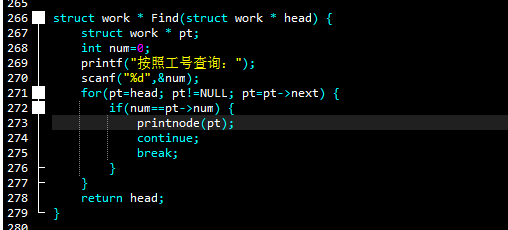
图中for循环的过程,就是链表遍历的过程,在一遍的搜索之后,如果出现的需要的东西,那就停止搜索,可以拿出来操作了。这里只是作为显示,并不需要操作什么。
图中的continue是考虑到会有工号重复的情况。
7.删除
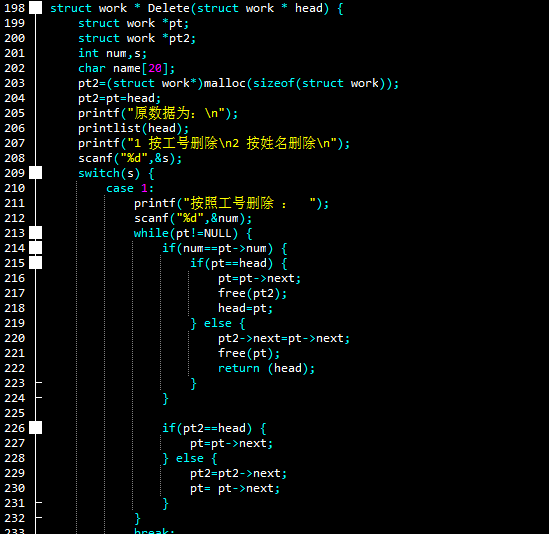
进入了删除模式之后,会有两个选项,按工号或者姓名删除,其实原理都一样,这里就以工号删除为例。
令新的指针代替头指针实现遍历(213),判断出来要删除的节点之后,再进行一次判断:你要删除的,是头结点,还是其他的。
a.头结点删除:
直接让指针指向下一位,释放掉原本的第一个,再让头指针重新指向原本的第二个。这里实现的过程就是pt比pt2多走了一位,以便进行操作。
b.其他节点:
直接令p2的后继指向pt的后继,也就是把pt直接隔过去,再进行释放。
至于下面的if,如你所见,它的功能就是在while循环里,使指针不断向后推进,直至目标出现。
当然了,按姓名删除的操作几乎一模一样,唯一的一点小区别就是,if的判断变成了这样:
if( strcmp(name,pt->name)==0 )
需要判断这两个字符串是否一致,完全一致的话,返回值就是0了,就能找到该节点了。strcmp需要头文件
7.修改
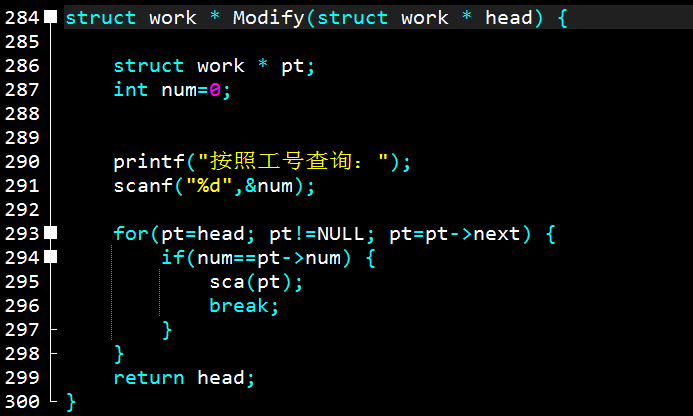 modify.png
modify.png
写之前感觉修改会很难,大概是不小心走了什么歪门邪道吧,写出来发现它的过程和遍历一样简单,无非是在我找到相关pt之后,又为它重新赋值了一遍而已(你当然会记得那个sca是我之前定义的赋值函数)。
排序!
如果你特别熟练链表以及它的增删改查,那么前面写的实在是基础。而排序的确让我为难困惑了一番。
a.冒泡的错
再最开始版本的排序里,我尝试了用冒泡排序对工号进行操作,排的过程也比较简略。可排出来之后感觉哪里好像有点不对,原来当时只是把num排了顺序,结果是其他的就乱了。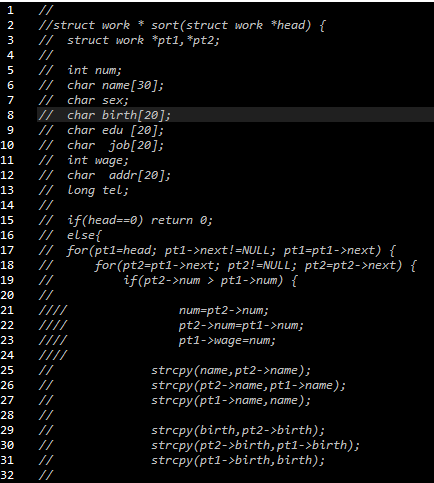
如你所见,它繁琐而低效(关键是还不对...)。
其实当时忘了一点,为什么不直接声明一个结构体变量,然后把它当做中间变量进行排序呢?
b.选择排序
并没有顺着那个思路想下去,换了个方法。
思想:如果说,原本的链表是无序的,而我最终的目的是创造出有序的。而且我有能力去找到这里面最大的或最小的(遍历就可以了),那么我何不再去创建一个新的链表,它是由原本链表摘出来的节点所组成,那必然是有序的。
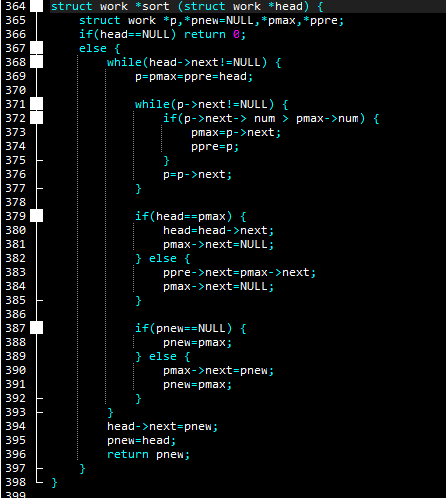
和其他操作的最开始一样,传入了头和它之后的一串链表,于以往不同的是,这次开始了直接对头指针的操作。
(366和367是为了防止传进来一个空头造成错误。
核心代码就是white里的循环了:
第一层循环
目的是为了让头不断向后遍历,只不过这次的目的,就是遍历到终点。期间每执行一次,就让我定义的指针重新指向同一块。
第二层循环
p(也就是头)的遍历,如果后一个大于前一个,就让后一个成为max,同时定位它的前一个节点,以这种方式标记过后,p再继续向后推进,以实现在循环过后,可以过滤出来最大的,找到了又怎样呢,我们来看接下来的操作。
第一个if(379)
这时还要考虑到那种情况,也就是头结点万一最大该怎么操作,这也并不难想,直接让head指向下一位,同时断开max(也就是头)与原链表的联系。
其它情况就是,既然上一步(371 while)找出来了max,那么就在这里把它摘出来,令刚刚标记的前一项(pre)指向max的后继,在断开max与原表的联系。
第二个if(387)
细心的你会发现,在每次的赋值里和之前的几步操作里,都没有用到pnew,不仅如此,它还在一开始就被置空了。
我的目的就是让它成为那个新的链表的头。在之前几步,我们分别找到了max,分离出了max,终于要在这一步为max找一个着落了。
当然,if第一次肯定是会执行的(因为上来就让pnew置空了),我们让最大的那个节点成了新链表的第一个,那么可想而知的是,在之后几次的循环里,每次都会执行else,并且在里面新摘出来的max被一个个的连到了链表的后面。
到最后,别忘了还有那个大循环的,它每次执行一遍里面的内容。如是,原本的无序链表每次少一个节点(最大的节点),而新有序链表每次会多一个。
原链表终结之日,也就是新链表生成之时。届时,循环也就彻底结束了,于是我们令头指针指向那个新生链表(394),再让它们共同指向这条有序的链表,传回去就行了。
到了这里,课程设计也就基本上结束了,增删改查带排序都说完了,如果你觉得意犹未尽,我们的学长学姐提出了一个新的要求:
该怎么做,才可以让你的数据保存下来,让我下次打开时还能看到这次的数据,下次开机时它们还在这里?
emmm....
对文件的操作
在学文件的时候,我总觉得这块的内容可以在今后用到的时候及搜及学。要实现如上功能,需要fwrite和fread :
(1)size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );
其中,ptr:指向保存结果的指针;size:每个数据类型的大小;count:数据的个数;stream:文件指针
函数返回读取数据的个数。
(2)size_t fwrite ( const void * ptr, size_t size, size_t count, FILE * stream );
其中,ptr:指向保存数据的指针;size:每
个数据类型的大小;count:数据的个数;stream:文件指针
函数返回写入数据的个数。
举个小例子:
fwrite(p,sizeof(int),1,fp )
这就是个每次向fp里存一个整型的,p就是那个要存到文件里的指针。
read同理,不表。
原本是要在每个功能的后面都加上这么一个写入文件的,后来在学长的提醒下,把最后一个功能改成了“保存并退出”,合理了不少。
save
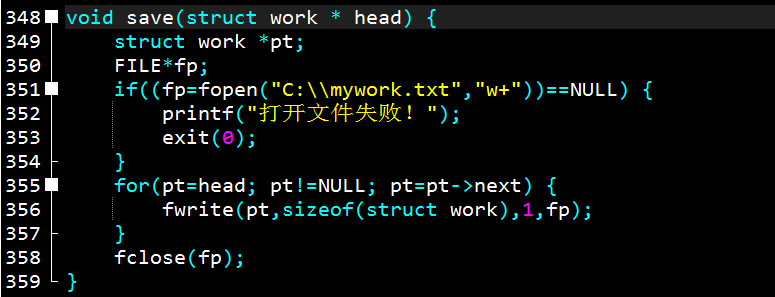
如我这个save函数:fopen打开,司空见惯。利用for循环,使pt从头到尾的指一遍,每次把一个struct work存进去,也就是一个节点,以这种方式把整条链表存进去。
read
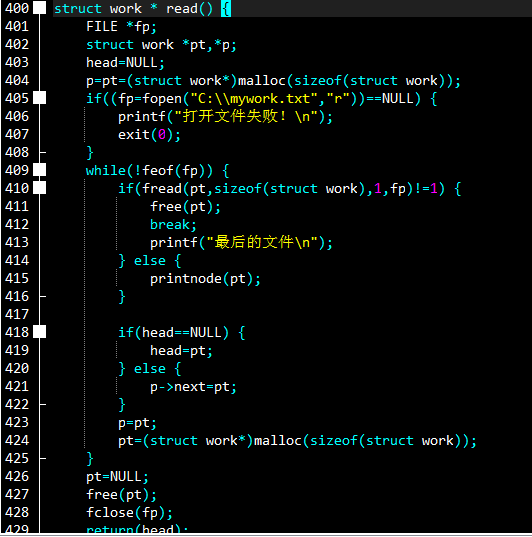
你会发现,这是个没有穿入参数的结构体函数,在直至文件fp的结尾之前,一直进行着循环。fread的返回值是写入数据的个数,也就是说每次从文件里面读一个,直到最后一个.
else的作用是把每一个节点都显示出来,显得有那么一点合情合理...
那每次读出来的节点都去了哪里呢?
这个和刚刚说的排序思路差不多,让head指向和pt一样的空间后,循环申请空间,每次都存入一个从文件里读出来的节点。形成了一条以head为头的新的链表(也就是上次你退出时的数据),被传回来得以继续操作。
这样,你也就得到了一个,可以增删改查排序的,还能记
录数据的课程设计了。
写课程设计,对于初学者来说是个漫长而复杂的过程,一筹莫展和万念俱灰的想法总是交相辉映。虽然有时也会绝望(比如我第一次运行有好几十个错误),但这就是个从中学习的过程。
把代码一点一点的改对,是个愉悦而有成就感的事。
last but not least :
感谢敏学姐、浪浪学长的指导和审阅,祝学长和429学长的鼓励支持。
感谢图书馆,提供了几乎所有知识。