下篇传送门:
吴教授的CNN课堂:进阶 | 从LeNet到残差网络(ResNet)和Inception Net
等了一个月,吴教授的Deeplearning.ai的第四部分,也就是关于卷积神经网络(Convolutional Neural Network,简写CNN)的课。
作为吴教授的忠实门徒(自封),除了在课堂上受到吴教授秀恩爱暴击外,当然也要好好做笔记。虽然之前也有过一些CNN基础,但这次收益还是挺多的。

CNN目前主要用于?
CNN目前主要用于CV领域,也就是计算机视觉领域。
很多当前最先进的计算机视觉方面的应用,如图片识别,物体检测,神经风格转换等等,都大量使用到了CNN。

而且不光是CV领域,很多CNN在CV领域应用的很多技巧,其他领域也可以从其中借鉴到很多,如自然语言处理。
为什么要用CNN
首先,假如我们要进行一个图像识别任务?这里就不用已经都快被玩烂了的的MNIST,用吴教授课上的SIGNS数据集(包含了用手势表示的从0到5的图片)。目标任务就是,给一个手势,识别出代表数字几。

如果是上过之前吴教授机器学习的同学的话,那么可能会问,为什么要用CNN呢?
何不直接像机器学习课里面一样,将图片拍扁(flatten),也就是直接将(高 x 宽 x 通道(如RGB))的图片展成一个一维向量呢。如SIGNS,本来是64x64x3的图片,我们将它拍成1x12288的向量。
之后直接输入全连接网络(即一般我们认为的神经网络),中间加点隐层,最后一层用softmax压一下直接输出结果就好了。
我们可以这样设计网络结构,第一层12288个单元,然后中间三个隐层,分别是1028个单元、256个单元、64个单元,最后一层6个单元,也就是我们的分类数。
搭建好网络后,然后训练。这样子确实也可以得到还过得去的结果,大概70~80%。但是相信大家也发现了,这样子搭建的网络需要很多很多参数,如这个例子里面
也就是大约一千三百万个参数。
而这个例子还只是很小的图片,因为只有64x64大小,而现在随意用手机拍张照片就比这大很多。处理这些图片时,用全连接网络搭建出来的网络的参数个数,将会是一个天文数字,不光优化困难,而且性能也不怎么样。
而这时候,就是CNN大展神威的时候了。只需要多少参数呢?之后再揭晓揭晓。
CNN基础:卷积层
卷积 Convolution
CNN网络最主要的计算部分就是首字母C,卷积(Convolutional)。
如下图,这里的一次卷积运算指的是,当我们有一个过滤器(filter),即下图移动的方块,将这个方块对应要处理的输入数据的一部分,然后位置一一对应相乘,然后把结果再相加得到一个数。
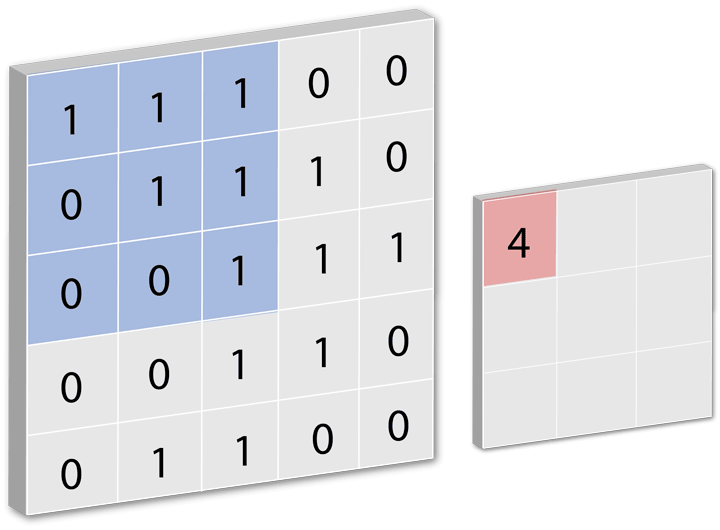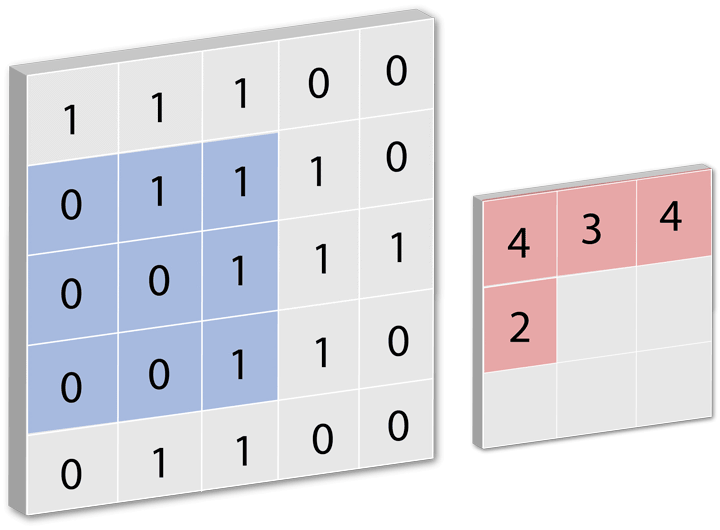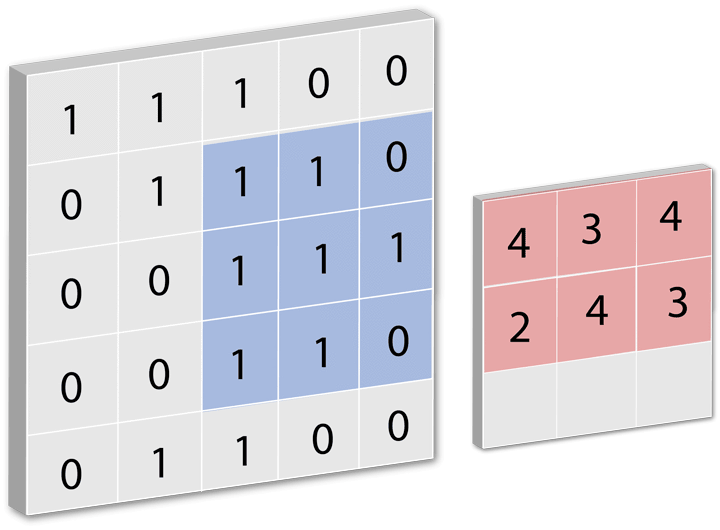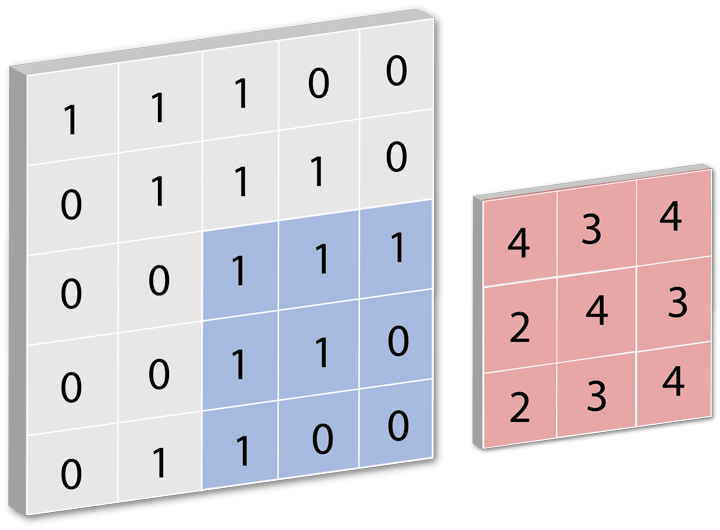
一个过滤器对一张图片进行卷积运算时,往往要进行多次卷积运算,对一部分进行计算完之后,然后移动一点距离再计算,继续移动,计算... 直到处理完整张图片。
为什么叫做过滤器呢(也有叫做kernel(核)的)?
因为我们可以把每个过滤器,当做是设定了一定条件的特征检测器,把不属于检测条件的都过滤掉。只有当前卷积的区域符合这个过滤器设置的条件时,卷积计算结果才会得到一个比较大的数。
举个栗子,如用于检测垂直和水平边线的过滤器。

可以试着自己计算一下。如下图,如果用灰度表示的话,黑的地方是255,白的地方是0。用上面的Gx来卷积下面这张图的话,就会在中间黑白边界获得比较大的值。

而CNN中会有很多个过滤器,每个过滤器对图片进行卷积后,会得到下一个结果的一个通道。CNN厉害的地方在于,过滤器的特征并不是人为设定的,而是通过大量图片自己训练出来的。
这样也就增加了它的灵活性,而且因为视觉底层特征的兼容特性,因此也保证了迁移学习的可能。
步长(Stride)与填充(Padding)
上面说了卷积计算,但还有一些小的细节没提。
如果用(f, f)的过滤器来卷积一张$(h, w)$大小的图片,每次移动一个像素的话,那么得出的结果就是(h-f+1, w-f+1)的输出结果。f是过滤器大小,h和w分别是图片的高宽。
如果每次不止移动一个像素,而是两个像素,或者是s个像素会怎么样呢。
那么结果就会变为
这个s被称为步长。
但是如果每次这样子进行卷积的话,会出现一个问题。只要是$f$和$s$的值比1要大的话,那么每次卷积之后结果的长宽,要比卷积前小一些。
因为这样子的卷积,实际上每次都丢弃了一些图片边缘的信息。一直这样卷积的话,一旦卷积层过多,就会有很多信息丢失。为了防止这种情况的发生,我们就需要对原来的图片四周进行填充(padding)。

一般都会用“0”值来填充,填充1就代表对周围填充一圈,如上图。填充2就填充两圈,填充为p就是p圈,长宽各增加2p。
有了填充之后,每次卷积后的大小会变为
此时假设卷积后高不变
那么我们可以获得
假设s步长为1,那么
也就是如果过滤器的高h=5的话,那么为了保持输出高宽不变,那么就需要p=2。
上面这种保持卷积前后高宽不变的填充方式叫做"Same(相同)填充"。
分数情况
之后来讨论一下分数情况吧。
万一f是4或者6这样的数呢,那么得到的p岂不是分数,怎么填充。答案是,那f就不要取偶数嘛。这就是为什么一般默认的过滤器大小都是5、7、11这样的单数。
好的,解决了填充的情况,那么如果输出的
是分数怎么办。如h=6,f=3,p=0,s=2的情况下,按照公式计算会得到2.5。一般的处理是,只取整数部分。
而这种p=0,然后结果取整数部分的处理方式,叫做"Valid(有效)填充"。
CNN基础:池化(Pooling)层
除了上面的卷积层,CNN里面还有一个很重要的部分,池化层。
一般会跟在卷积层之后,主要用到的Pooling层主要由有Max Pooling和Average Pooling, 也就是最大池化和平均池化。
其实概念很简单,最大池化就如下图。假设有一个2x2的窗口,每次移动步长也为2,每次对窗口里的数取最大值,然后输出。
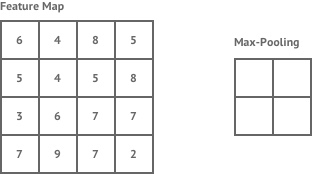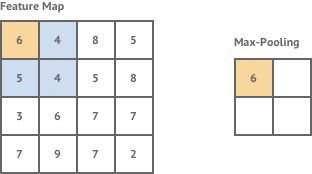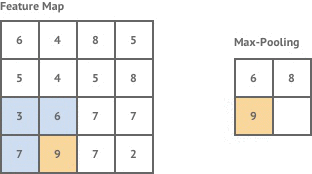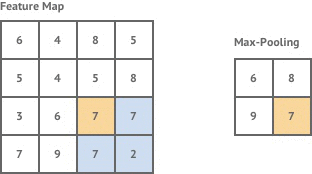
同样的平均池化,则就把取最大值这个操作换成取平均值就行了。
除了上面两种池化方式,当然还有一些其他的池化方法,如k-Max Pooling之类的,但是应用很少。在最大和平均两个里面,也是最大池化比较常用。
池化层输出大小的转换也和卷积层比较类似,用
来计算,一般池化层不用填充。而且池化层没有要需要训练的参数。
CNN基础:组合
有了卷积层和池化层两大部件之后,就只剩下组合了。下图是吴教授手绘LeNet-5网络。

结构很简单大概是这样子Input -> Conv1 -> Pool1 -> Conv2 -> Pool2 -> (Flatten) -> FC3 -> FC4 -> Output。
Conv是卷积层,Pool是池化层,FC指的是全连接网络层(Full-Connected)。其中Flatten指的是,因为卷积网络输出的数据形状(3维),和紧接着的全连接网络的输入形状(1维)不吻合,所以需要进行一些处理。
就是之前在直接用全连接网络提到的,把卷积网络的输出拍扁(flatten),把三维的拍成一维,之后再输入全连接网络。
建议大家可以按照前面提到的形状变换公式,还有吴教授的手绘图,亲自把LeNet-5过一遍,对之后编程CNN很有帮助的。
关于前面的参数个数的问题,用上面这个LeNet-5来处理的话
也就是大概114万。
一下子就缩小了一个数量级,当然对于越大的图片这个差还会更加大。
结尾
这就是吴教授CNN课堂的第一周上的内容了。这次在通道这个概念有了很多新的看法。
如果想要自己修的话,直接Coursera Deeplearning ai就能搜索到课程。
Coursera小技巧,点击注册,不想付钱的话,点左下角的那个小小的旁听就好了。之后想拿证的时候再充值。
习题很简单,这里是我的练习解答,如有困难可以参考。 repo