hadoop的安装
新建hadoop目录,并创建source文件夹用来存放相关的软件。
mkdir /opt/hadoop
mkdir /opt/hadoop/source
# 解压安装
tar -xzvf /usr/local/hadoop-2.7.3.tar.gz
#将解压后的文件夹移动到 hadoop目录下
mv hadoop-2.7.3 /opt/hadoop
配置环境变量
编辑配置文件
vim /etc/profile
#添加如下内容
#HADOOP
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
# hadoop data direcotory
export HADOOP_DATA_DIR=/mnt/hdfs
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
#使配置文件生效
source /etc/profile
#更改文件所有者
chown hadoop $HADOOP_HOME
建立数据存储目录namenode和datanode
环境变量HADOOP_DATA_DIR=/mnt/hdfs
#建立目录
mkdir $HADOOP_DATA_DIR/namenode
mkdir $HADOOP_DATA_DIR/datanode
#更改文件所有者
chown hadoop /mnt/hdfs/namenode
chown hadoop /mnt/hdfs/datanode
修改hadoop配置文件
进入相应的路径
cd /opt/hadoop/hadoop-2.7.3/etc/hadoop
对要修改的文件进行备份
cp core-site.xml core-site.xml.bak
cp hdfs-site.xml hdfs-site.xml.bak
cp yarn-site.xml yarn-site.xml.bak
cp hadoop-env.sh hadoop-env.sh.bak
cp mapred-site.xml.template mapred-site.xml
修改hadoop-env.sh
# 将变量改成常量即路径!!!不然会找不到JAVA_HOME
export JAVA_HOME=$JAVA_HOME //默认
export JAVA_HOME=/opt/IBM/WebSphere/AppServer/java //改成java安装路径
**修改core-site.xml **
在
增加的内容如下:
fs.default.name
hdfs://localhost:9000
hadoop.tmp.dir
/home/tmp
修改hdfs-site.xml
在
dfs.replication
1
dfs.namenode.dir
file:/mnt/hdfs/namenode
dfs.datanode.dir
file:/mnt/hdfs/datanode
修改mapred-site.xml文件
mapreduce.framework.name
yarn
修改yarn-site.xml文件
在
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
启动hadoop
- 格式化namenode
hadoop namenode -format - 启动所有hadoop守护进程
start-all.sh - 查看守护进程是否全部启动
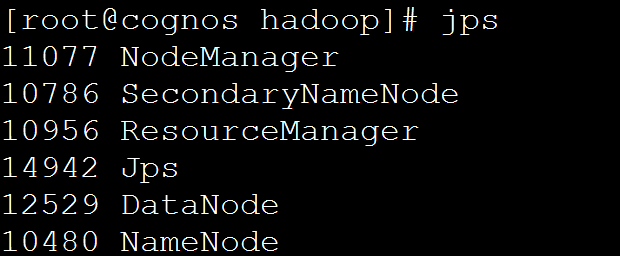
jps
hadoop全部守护进程启动应该有5个,如下:
遇到的错误
注意:
在搭建过程中遇到报错一定要去查看日志,然后再去解决问题,会事半功倍。错误日志所在目录为:hadoop的安装路径/logs
Could not find the main class
hadoop格式化时报错org.apache.hadoop.hdfs.server.namenode.NameNode。。。
我这里是由于之前安装过cognos,java环境变量设置的是cognos的自带java环境。
解决办法
- 下载java
yum install java*
下载完成后可以看到下载了多个java版本,从1.5到1.7。这里我们选择使用1.7版本。 - 利用linux下的多版本管理软件alternatives来实现jdk的版本更改
在/usr/lib/jvm文件夹下时间存储了各个jdk版本的软件,而alternatives正是通过修改它的java引用达到版本切换的目的。 - 使用alternatives实现版本切换
-
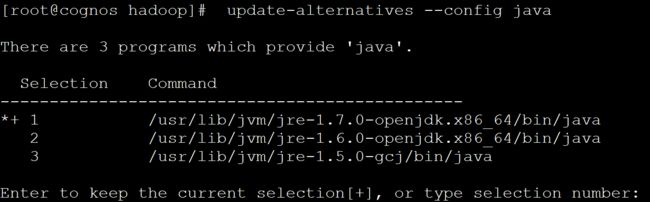
查看相应的jdk是否在redhat的jdk菜单里。并选择序号,回车即可;
update-alternatives --config java
update-alternatives --config javac
- java -version,javac -version查看当前jdk版本
- 如果java版本没有进行更改,则需要在环境变量path中添加选择的java变量。
通过如下命令可以在$PATH的开始或末尾添加jdk的环境变量(bin目录下保存了java, javac, javah等可执行命令)
export JAVA_HOME=/usr/lib/jvm/java-1.7.0-openjdk.x86_64
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
由于执行的时候总是从$PATH的开始搜索可执行文件的位置,所以如果环境变量中已经设置了一个jdk,那么把新的jdk设置在PATH的开始才会有用。
No route to host
jps发现少了nodemanager,于是查看日志文件hadoop-root-datanode-cognos.log
发现报了一下错误:

解决办法
先检查防火墙是否关闭。是关闭的。然后检查hosts,发现ip地址出错了。进行更改。
DataNode: Initialization failed for Block pool
格式化并启动所有进程后没有datanode进程
查看datanode日志发现
#java.io.IOException: Incompatible clusterIDs in /home/tmp/dfs/data: namenode clusterID = CID-07c55851-43ac-4c60-8920-4222ebdae886; datanode clusterID = CID-f3af4a31-2c73-4a0d-a6f0-8e1d310df111
at org.apache.hadoop.hdfs.server.datanode.DataStorage.doTransition(DataStorage.java:775)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadStorageDirectory(DataStorage.java:300)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.loadDataStorage(DataStorage.java:416)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.addStorageLocations(DataStorage.java:395)
at org.apache.hadoop.hdfs.server.datanode.DataStorage.recoverTransitionRead(DataStorage.java:573)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initStorage(DataNode.java:1362)
at org.apache.hadoop.hdfs.server.datanode.DataNode.initBlockPool(DataNode.java:1327)
at org.apache.hadoop.hdfs.server.datanode.BPOfferService.verifyAndSetNamespaceInfo(BPOfferService.java:317)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:223)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:802)
at java.lang.Thread.run(Thread.java:744)
#2017-01-11 09:20:00,862 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for Block pool (Datanode Uuid unassigned) service to cognos/172.16.7.191:9000. Exiting.
#java.io.IOException: All specified directories are failed to load.
这是由于datanode的clusterID 和 namenode的clusterID 不匹配造成的。
造成这个原因的操作是我刚开始配置core-site.xml的时候,hdfs的value配置的是:hdfs://localhost:9000。而后来我又改成了hdfs://172.16.7.191:9000。这导致在两次执行格式化操作的时候datanode的clusterID 和 namenode的clusterID 不匹配。
解决办法
- 将/home/tmp/dfs/data/current目录里的version文件的clusterID替换成/home/tmp/dfs/name/current目录下的version文件里的clusterID
- 执行重启操作 start-dfs.sh 然后用 jps命令查看 就可以看到namenode已被启动
参考文章:
jdk版本切换
通过web端口查看主节点、slave1节点及集群运行状态