第2章 这是一个简单的Lisp程序
Certum quod factum(吐槽:意大利语逼格是高呀~)
一切的本源都是自身的构成(吐槽:格言什么的最难理解了)
-Giovanni Battista Vico(意大利皇家史官)
只学词汇是永远不会精通一门外语的。必须要结合听说读写,才能精通一门语言。对于编程语言,道理也是一样。
本章展示的是如何将普通函数与Lisp的特殊形式结合在一起,形成一个完整的程序。通过学习这个构建的过程,Lisp剩下的词汇你也会学好的。
2.1 英语的一个子集也要有语法
我们将要开发的程序会生成随机的英语句子。下面是一个英语的子集的简单语法:
句子=>名词短语+动词短语
名词短语=>冠词+名词
动词短语=>动词+名词短语
冠词=>the,a…
名词=>man,ball,woman,table…
动词=>hit,took,saw,liked…
技术上来讲,上面的描述被称作上下文无关的短语结构语法,潜在的范式叫做生成型句法。这种概念是应用在我们生成句子的时候,我们会生成一个动词短语,之后是一个名词短语。名词短语的定义就是冠词后面加上一个名词。冠词的意思就是the,或者a或者其他冠词。这种形式主义是上下文无关的,因为应用的规则与所用的单词无关,这种生成的方法就是定义了一个语言的句法规则(相对的就是非句子的集合)。接下来我们演示一下单个句子使用规则的应用流程:
要获得一个句子,首先连接一个名词短语和一个动词短语
要获得一个名词短语,连接一个冠词和名词
选择冠词the
选择名词man
名词短语的结果是the man
为了获得动词短语,连接一个动词和一个名词短语
选择动词hit
获取一个名词短语,连接一个冠词和一个名词
选择冠词the
选怎名词ball
名词短语结果是the ball
动词短语的结果是hit the ball
句子是the man hit the ball
2.2 一个直截了当的解决方法
我们接下来开发的程序会用短语结构语法生成随机的句子。一个最直接的方法就是把每一个语法规则写成一个独立的Lisp函数:
(defun sentence () (append (noun-phrase) (verb-phrase)))
(defun noun-phrase () (append (Article) (Noun)))
(defun verb-phrase () (append (Verb) (noun-phrase)))
(defun Article () (one-of ‘(the a)))
(defun Noun () (one-of ‘(man ball woman table)))
(defun Verb () (one-of ‘(hit took saw liked)))
每一个函数定义的参数列表都是空的,以为这他不接受任何参数。严格来说,一个函数要是没有参数输入的话,它的返回值就是不变的值,所以我们会使用一个常量来代替。然而,这些函数会使用随机函数,因此,即使没有参数输入也会返回不同的值。这些函数在数学体系中是不存在的,但是我们仍然称他们为函数,因为他们是会返回一个值的。
现在剩下的就是去定义函数one-of,他接受的参数是一系列选择,随机返回其中的一个元素。这个函数的随后一部分是随机选择一个单词返回一个列表,这样就可以产生自由的互相组合了。
(defun one-of (set)
”Pick one element of set, and make a list of it.”
(list (random-elt set)))
(defun random-elt (choices)
”Choose an element from a list at random.”
(elt choices (random (length choices))))
这里出现了两个函数,elt和random。Elt会从列表中选择一个元素。第一个参数是列表,第二个参数是元素的位置。容易有疏漏的地方是它的位置编号是从0开始,所以表达式(elt choices 0)的结果是列表的第一个元素,而表达式(elt choices 1)的结果是第二个元素。函数random的返回值是一个0到n-1之间的整型数,所以表达式(random 4)返回的是0,1,2,3四个数当中的一个。
现在我们测试一下程序:
> (sentence) => (THE WOMAN HIT THE BALL)
> (sentence) => (THE WOMAN HIT THE MAN)
> (sentence) => (THE BALL SAW THE WOMAN)
> (sentence) => (THE BALL SAW THE TABLE)
> (noun-phrase) =>
> (verb-phrase) => (LIKED THE WOMAN)
> (trace sentence noun-phrase verb-phrase article noun verb) =>
(SENTENCE NOUN-PHRASE VERB-PHRASE ARTICLE NOUN VERB)
> (sentence) =>
(1 ENTER SENTENCE)
(1 ENTER NOUN-PHRASE)
(1 ENTER ARTICLE)
(1 EXIT ARTICLE: (THE))
(1 ENTER NOUN)
(1 EXIT NOUN: (MAN))
(1 EXIT NOUN-PHRASE: (THE MAN))
(1 ENTER VERB-PHRASE)
(1 ENTER VERB)
(1 EXIT VERB: (HIT))
(1 ENTER NOUN-PHRASE)
(1 ENTER ARTICLE)
(1 EXIT ARTICLE: (THE))
(1 ENTER NOUN)
(1 EXIT NOUN: (BALL))
(1 EXIT NOUN-PHRASE: (THE BALL))
(1 EXIT VERB-PHRASE: (HIT THE BALL))
(1 EXIT SENTENCE: (THE MAN HIT THE BALL))
(THE MAN HIT THE BALL)
程序运行的还可以,追踪信息的结果也和上面的理论推导和相似,但是Lisp定义比语法规则来说会有一些难以阅读。问题随着语法规则的复杂化慢慢变得复杂了。假设我们想要允许名词短语之前可以加上不限数量的形容词和介词。用语法的表达形式,我们会得出下面的规则:
Noun-Phrase => Article + Adj* + Noun + PP*
Adj* => 0, Adj + Adj*
PP* => 0, PP + PP*
PP => Prep + Noun-Phrase
Adj => big, little, blue, green, . . .
Prep => to, in, by, with, . . .
在这个表达形式中,0的意思是不选择,逗号分隔的是多个选项中的一个选择,后面加上星号的意思是可选。星号的具体意思是可以不加,也可以加多个。这种标记法叫做Kleene星号。之后我们会见到Kleene加号,PP+的意思是一个或者多个的重复PP。
现在的问题是,对于形容词和介词的选择,我们要使用Lisp的某种条件式来实现:
(defun Adj* ()
(if (= (random 2) 0)
nil
(append (Adj) (Adj*))))
(defun PP* ()
(if (random-elt ‘(t nil))
(append (PP) (PP*))
nil))
(defun noun-phrase () (append (Article) (Adj*) (Noun) (PP*)))
(defun PP () (append (Prep) (noun-phrase)))
(defun Adj () (one-of ‘(big little blue green adiabatic)))
(defun Prep () (one-of ‘(to in by with on)))
之前选择了两个Adj和PP的实现,都是可以用的,下面两个例子是错误的,不可用的程序:
(defun Adj* ()
“Warning – incorrect definition of Adjectives.”
(one-of ‘(nil (append (Adj) (Adj*)))))
(defun Adj* ()
“Warning – incorrect definition of Adjectives.”
(one-of ‘( list nil (append (Adj) (Adj*)))))
第一个例子错在返回的是字面上的append表达式而不是一个计算后的值的列表。第二个定义会引起无限递归。关键点在于,随着程序的渐渐开发,原来一些简单的函数将会变的复杂。为了理解他们我们需要理解很多Lisp的惯例-defun,(),case,if,quote还有很多求值规则,并且必须要符合现实情况下的语法规则。程序越来越庞大,问题也会越来越难弄。
2.3 一个基于规则的解决方法
另一个实现的方法就是先关注语法的规则,之后再去考虑怎么个流程。我们来回顾一下原始的语法规则:
句子=>名词短语+动词短语
名词短语=>冠词+名词
动词短语=>动词+名词短语
冠词=>the,a…
名词=>man,ball,woman,table…
动词=>hit,took,saw,liked…
这些规则的意思是左边的是由右边的组成的,有一点复杂的地方,右边的构成形式有两种,一种是两个对象的连接,比如名词短语=>冠词+名词,另一种是列表名词=>man,ball,。就实现来说,每一种可能性都可以用列表中的元素表示,至于两个对象的连接,也可以展开。下面是规则的代码实现:
(defparameter *simple-grammar*
'(sentence -> (noun-phrase verb-phrase))
(noun-phrase -> (Article Noun))
(verb-phrase -> (Verb noun-phrase))
(Article -> the a)
(Noun -> man ball woman table)
(Verb -> hit took saw liked))
"A grammar for a trivial subset of English.")
(defvar *grammar* *simple-grammar*
"The grammar used by generate. Initially, this is
这个规则的Lisp版本只是对原始规则的近似模仿。特别是符号->,没有什么特别的意义,只是装饰用的。
特殊形式操作符defvar和defparameter都会引入一个新的变量,赋值给他;他们之间的区别是变量,grammer,在程序运行期间是可变的。而一个参数,simple-grammar,一般来说是不可变的常量。更改一个参数被认为是对程序本身的修改,而不是程序修改值。
一旦规则的列表定义完成,就可以用给定的目录符号来修改了。函数assoc就是干这个活儿的。Assoc接受两个参数,一个关键字和一个列表的列表,返回的是第一个关键字打头的列表。没有的话就返回nil。下面是例子:
> (assoc ‘noun *grammar*) => (NOUN -> MAN BALL WOMAN TABLE)
虽然用列表实现的规则很简单,但是定义函数,中间差一个操作语法规则抽象层还是很重要的。我们需要三个函数:一个用来获取规则右边的对象,一个用来获取左边,还有一个根据目录寻找可能的对象。
(defun rule-lhs (rule)
”The lsft-hand side of a rule.”
(first rule))
(defun rule-rhs (rule)
”The right-hand side of a rule.”
(rest (rest rule)))
(defun rewrites (category)
“Return a list of the possible rewrites for the category.”
(rule-rhs (assoc category *grammar*)))
定义的这些个函数会让读取规则的函数更加方便,更改规则也会更好用。
现在,我们准备好直接面对问题了:定义一个函数,生成句子(或者其他的短语)。这个函数的名字叫做generate。他必须要应付三种情况:1,最简单的情况,一个相关规则的重写集合的符号传进generate。根据这个参数随机生成。2,如果符号不能重写规则,就必须是一个终极符号-单词或其他语法类别-就可以放一边了。事实上,我们返回的是输入的单词的列表。所有的结果都需要变成单词列表的形式。3,一些情况下,符号被修改的时候,我们会选择一个符号列表,并尝试根据这个生成。因此,generate也必须接受一个列表作为输入,生成列表的每一个元素,聚合在一起。接下来对应的部分是第一个对应第三种情况,第二个对应第一种,第三个对应第二种。在定义中可能会用到mappend函数。
(defun generate (phrase)
“Generate a random sentence or phrase”
(cond ((listp phrase)
(mappend #’generate phrase))
((rewrites phrase)
(generate (random-elt (rewrites phrase))))
(t (list phrase))))
如数中许多程序一样,函数篇幅很短,信息量很大:编程的精髓在于知道什么该写,什么不该写。
这种编程风格叫做数据驱动编程,因为数据(使用相关目录重写的列表)驱动接下来的程序操作。在Lisp中这是一种自然易用的方式,可以写出精细可扩展的程序,因为在不修改原来程序的基础上加上一段新的数据也是可以的。
下面是generate应用的例子:
> (generate 'sentence)=>(THE TABLE SAW THE BALL)
> (generate 'sentence) ¬=> (THE WOMAN HIT A TABLE)
> (generate 'noun-phrase) =>¬ (THE MAN)
> (generate 'verb-phrase) ¬=> (TOOK A TABLE)
使用if来替代cond来写generate也是可以的:
(defun generate (phrase)
“Generate a random sentence or phrase”
(if (listp phrase)
(mappend #’generate phrase)
(let ((choices (rewrites phrase)))
(if (null choices)
(list phrase)
(generate (random-elt choices))))))
接下来是使用特殊形式let的版本,let引入一个新的变量(在这里是choices)并且给变量绑定一个值。在这种情况下,引入这个变量会减少两次对rewrites的调用,let形式的一般形式是这样的:
(let ((变量 值)…))
包含变量的函数体)
Let函数是对那些没有参数的函数引入变量最常用的方式。一种竭力要避免的方式就是在引入变量之前尝试去使用变量:
(defun generate (phrase)
(setf choices …) ;;;wrong!
… choices …)
因为这个符号choices现在指向一个特殊变量或者全局变量,这个变量可能会被其它函数修改,所以这种方式要竭力避免。Generate函数现在还不可靠,因为没有保证choices会在接下来的引用中一直保持同样的值。使用let,我们会引入一个全新的变量,没有其他人可以访问;因此就保证了他的值会保持下去。
【m】2.1 使用cond写一个generate的版本,但是要避免调用rewrites两次。
【m】2.2 写一个generate的版本,显式区分终极符号(那些没有重写规则的符号)和非终极符号。
2.4 之后的两种思路
接下来程序的展现的两种方式的两个版本总是在程序开发的过程中一再出现:(1)将问题直接描述成Lisp代码。(2)使用最自然地方式描述问题,之后再来写这种方式的解释器。
第二种范式包括了一个额外的步骤,因此更加是个规模较小的问题。然而,使用第二种思路的程序更加容易修改和扩展。当需要处理特别多的数据的时候,这种思路就比较管用。自然语言的语法实际上就是这种情况,大部分AI问题都适用这个描述。方法2背后的思想就是将问题尽可能限制在自己的术语环境内,并且将解决方法的核心最小化,用Lisp直接写出来。
很幸运的是,Lisp设计一种新的表达法是很方便的,也就是设计一门新的编程语言。因此,Lisp所鼓励的是构建更加稳健的程序。通篇都是这两种方式。读者会注意到,很多情况下,我们使用第二种。
2.5 不改变程序就能改变语法
哦我们来展示一下方法(2)的核心功能,定义一个新的语法,包含的有形容词,介词短语,固有名称和代词。之后可以将函数generate函数应用,却不用修改新的语法。
(defparameter *bigger-grammar*
‘((sentence -> (noun-phrase verb-phrase))
(noun-phrase -> (Article Adj* Noun PP*) (Name) (Pronoun))
(verb-phrase -> (Verb noun-phrase PP*))
(PP* -> () (PP PP*))
(Adj* -> () (Adj Adj*))
(PP -> (Prep noun-phrase))
(Prep -> to in by with on)
(Adj -> big little blue green adiabatic)
(Article -> the a)
(Name -> Pat Kim Lee Terry Robin)
Noun -> man ball woman table)
(Verb -> hit took saw liked)
(Pronoun -> he she it these those that)))
(setf *grammar* *bigger-grammar*)
> (generate ‘sentence)
(A TABLE ON A TABLE IN THE BLUE ADIABATIC MAN SAW ROBIN WITH A LITTLE WOMAN)
> (generate ‘sentence)
(TERRY SAW A ADIABATIC TABLE ON THE GREEN BALL BY THAT WITH KIM IN THESE BY A GREEN WOMAN BY A LITTLE ADIABATIC TABLE IN ROBIN ON LEE)
> (generate 'sentence)
(THE GREEN TABLE HIT IT WITH HE)
很明显的是生成的句子有代词问题,with he应该是withhim才正确,才是正常的语法。随机输出的句子很显然有时候是没有什么意义的。
2.6 对一些程序使用相同的数据
Another advantage of representing information in a declarative form-as rules or
facts rather than as Lisp functions-is that it can be easier to use the information for
multiple purposes. Suppose we wanted a function that would generate not just the
list of words in a sentence but a representation of the complete syntax of a sentence.
For example, instead ofthe list< a woman took a ba 11 ), we wantto getthe nested list:
声明的形式(最为规则或者事实而不是函数)来展现信息的另一个好处就是这些信息可以对对个目的使用。假设我们想要一个函数,生成的不仅是单词的列表还要有一个句子的完整语法。例如,列表(a woman took a ball)的嵌套形式就是:
(SENTENCE (NOUN-PHRASE (ARTICLE A) (NOUN WOMAN))
(VERB-PHRASE (VERB TOOK)
(NOUN-PHRASE (ARTICLE A) (NOUN BALL))))
对应的语言意义树可以这么描述:
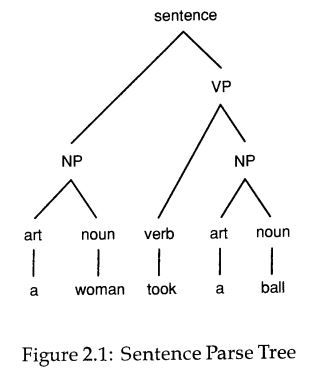
使用上面的直接的方法的话,我们会遇到很大的困难;不得不重写每一个函数来生成另外的结构。使用新的表示法,我们可以让语法就保持原样,只需要写一个新的函数:generate,可以生成嵌套列表的版本。有两个变化, 一个是使用cons将分门别类的重写进规则中,还有就是不用append聚合结果,而是使用mapcar来列印他们。
(defun generate-tree (phrase)
“Generate a random sentence or phrase,
With a complete parse tree.”
(cond ((listp phrase)
(mapcar #’generate-tree phrase))
((rewrites phrase)
(cons phrase
(generate-tree (random-elt (rewrites phrase)))))
(t (list phrase))))
下面是一些运行的例子:
> (generate-tree 'Sentence)
(SENTENCE (NOUN-PHRASE (ARTICLE A)
(ADJ*)
(NOUN WOMAN)
(PP*))
(VERB-PHRASE (VERB HIT)
(NOUN-PHRASE (PRONOUN HE))
(PP*)))
¬ > (generate-tree 'Sentence)
(SENTENCE (NOUN-PHRASE (ARTICLE A)
(NOUN WOMAN))
(VERB-PHRASE (VERB TOOK)
(NOUN-PHRASE (ARTICLE A) (NOUN BALL))))
我们可以开发一个函数来生成一个短语的所有可能的改写,作为单数据多程序方法的一个例子。Generate-all函数返回一个短语的列表接着定义一个备用的函数combine-all,来管理结果的组合。实际上为了进行空nil检查,是有四种而不是三种情况。完整的程序仍然是很简短的。
(defun generate-all (phrase)
“Generate a list of all possible expansions of this phrase.”
(cond ((null phrase) (list nil))
((listp phrase)
(combine-all (generate-all (first phrase))
(generate-all (rest phrase))))
((rewrites phrase)
(mappend #’generate-all (rewrites phrase)))
(t (list (list phrase)))))
(defun combine-all (xlist ylist)
“Return a list of lists forms by appending a y to an x.
E.g., (combine-all ‘((a) (b)) ‘((1) (2)))
->((A 1) (B 1) (A 2) (B 2)).”
(mappend #’(lambda (y)
(mapcar #’(lambda (x) (append x y)) xlist))
ylist))
现在我们可以使用generate-all来测试原始的语法,知识有一个缺陷,generate-all是不能处理递归的规则的,会导致无限的循环输出。但是有限的语言是OK的。
> (generate-all 'Article)
( (TH E ) ( A) )
> (generate-all 'Noun)
((MAN) (BALL) (WOMAN) (TABLE))
> (generate-all 'noun-phrase)
((A MAN) (A BALL) (A WOMAN) (A TABLE)
(THE MAN) (THE BALL) (THE WOMAN) (THE TABLE))
> (length (generate-all 'sentence))
256
256个句子的意思是每一个句子都是这样的结构,冠词-名词-动词-冠词-名词,有两个冠词,四个名词和四个动词,所以结果就是2x4x4xx2x4=256。
2.7 练习题
【h】2.3 写一个其他语言的语法,除了英语之外的,比如一种编程语言的子集。
【m】2.4 描述combine-all的一种方式就是两个列表的向量叉乘之后在append。写一个高阶函数croos-product,用它来定义combine-all。
这个练习的目的就是让你的代码尽可能的通用,因为你永远不知道接下来会面对什么。
2.8 习题答案
2.1
(defun generate (phrase)
“Generate a random sentence or phrase”
(let ((choices nil))
(cond ((listp phrase)
(mappend #’generate phrase))
((setf choices (rewrites phrase))
(generate (random-elt choices)))
(t (list phrase)))))
2.2
(defun generate (phrase)
“Generate a random sentence or phrase”
(cond ((listp phrase)
(mappend #’generate phrase))
((non-terminal-p phrase)
(generate (random-elt (rewrites phrase))))
(t (list phrase))))
(defun non-terminal-p (category)
“True if this is a category in the grammar.”
(not (null (rewrites category))))
2.4
(defun cross-product (fn xlist ylist)
“Return a list of all (fn x y) values.”
(mappend #’(lambda (y)
(mapcar #’(lambda (x) (funcall fn x y))
xlist))
ylist))
(defun combine-all (xlist ylist)
“Return a list of lists formed by appending a y to an x”
(cross-product #’append xlist ylist))
现在我们可以使用另一种方式来使用cross-product:
> (cross-product #'+ '(1 2 3) '(10 20 30))
(11 12 13
21 22 23
31 32 33)
> (cross-product #'list '(a b c d e f g h)
'(1 2 3 4 5 6 7 8))
(A 1) (8 1) (C 1) (0 1) (E 1) (F 1) (G 1) (H 1)
(A 2) (8 2) (C 2) (0 2) (E 2) (F 2) (G 2) (H 2)
(A 3) (8 3) (C 3) (0 3) (E 3) (F 3) (G 3) (H 3)
(A 4) (8 4) (C 4) (0 4) (E 4) (F 4) (G 4) (H 4)
(A 5) (8 5) (C 5) (0 5) (E 5) (F 5) (G 5) (H 5)
(A 6) (8 6) (C 6) (0 6) (E 6) (F 6) (G 6) (H 6)
(A 7) (8 7) (C 7) (0 7) (E 7) (F 7) (G 7) (H 7)
(A 8) (8 8) (C 8) (0 8) (E 8) (F 8) (G 8) (H 8))