语料库就是我们要分析文件的合计。
语料库构建
http://blog.csdn.net/happylife_haha/article/details/44566975
构建方法:
os.walk(fileDir)
fileDir 文件夹路径
文件读取:
codecs.open(filePath, method, encoding)
filePath 文件路径
method 打开方式,r 读, w 写, rw 读写;
encoding 文件的编码,打开方式UTF-8。
# -*- coding: utf-8 -*-
import os
import os.path
#导入OS模块
#定义
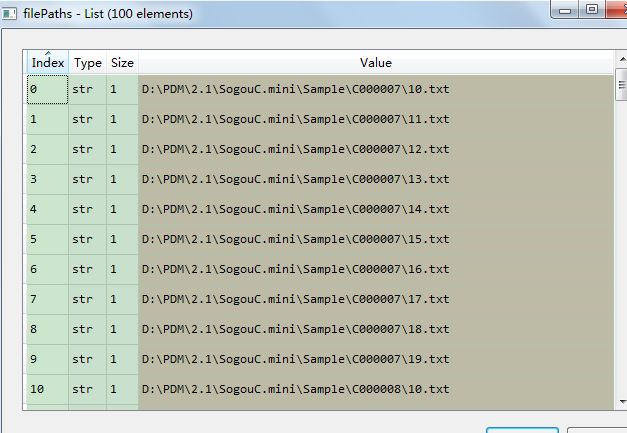
filePaths = []
for root, dirs, files in os.walk(
"D:\\PDM\\2.1\\SogouC.mini\\Sample"
):
for name in files:
filePaths.append(os.path.join(root, name))
import codecs
filePaths = [];
fileContents = [];
for root, dirs, files in os.walk(
"D:\\PDM\\2.1\\SogouC.mini\\Sample"
):
#遍历目录下所有的文件,
for name in files:
filePath = os.path.join(root, name);
filePaths.append(filePath);
#只读文件
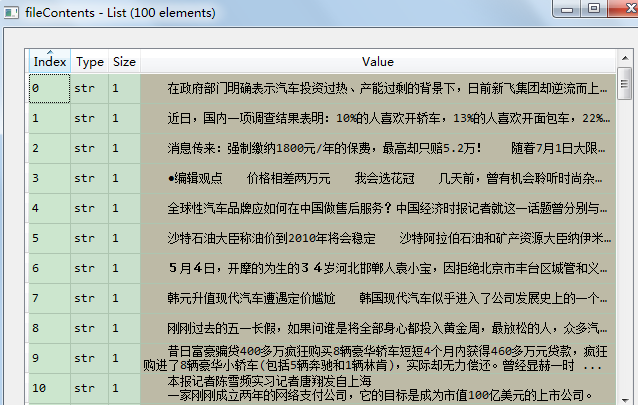
f = codecs.open(filePath, 'r', 'utf-8')#打开文件
fileContent = f.read()
f.close()#关闭文件
fileContents.append(fileContent)
#构建语料库
import pandas;
corpos = pandas.DataFrame({
'filePath': filePaths,
'fileContent': fileContents
})
