Python 2.7
IDE Pycharm 5.0.3
Firefox 47.0.1
豆瓣电影系列:
- 基础抓取(限于“豆瓣高分”选项电影及评论)请看↓
Python自定义豆瓣电影种类,排行,点评的爬取与存储(基础) - 初级抓取(限于“豆瓣电影”的各种选项,包括“热门”,“豆瓣高分”等十几个类别及评论,并打包exe)请看↓
Python自定义豆瓣电影种类,排行,点评的爬取与存储(初级) - 进阶抓取(在初级抓取基础上,套上GUI框架,图像显示更加人性化,并打包成exe)请看↓
Python自定义豆瓣电影种类,排行,点评的爬取与存储(进阶上) - 在进阶上的基础上新增TV选项及相应功能,新增TOP10 M&T 请看↓
Python自定义豆瓣电影种类,排行,点评的爬取与存储(进阶下)
更新说明
1.新增CMD版本,并打包处理
2.新增存入word操作。
3.新增预告片链接,新增推荐相关电影。
4.自由度加强,可自定义对评论,简介,写入存储,推荐,计时(针对cmd版本)等采集开关,采集何种数据真正自由选择。
5.简化代码,优化代码结构,更加清晰明了富有逻辑(自认为)
版本预览
GUI版本
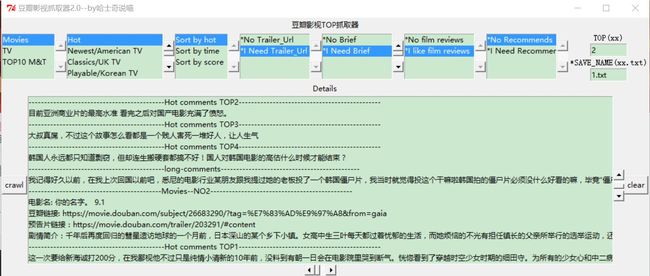
CMD版本
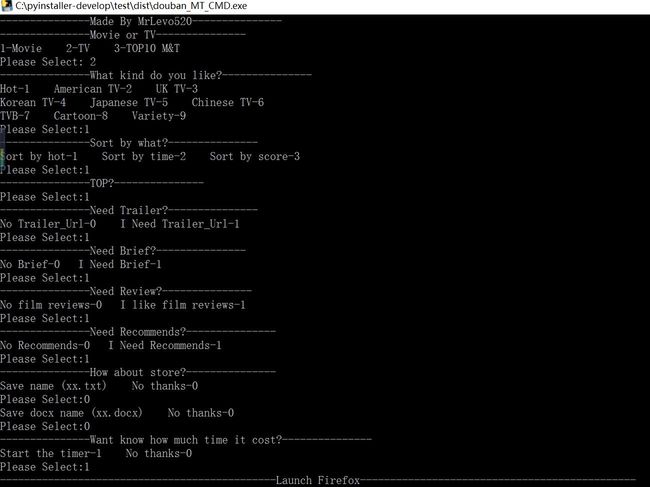
总的来说,我优化的是cmd版本的,因为gui版本的我实在无力了,好麻烦的,cmd版本的比较适合,python做gui真的不怎么好看,这个gui版本凑合能用,符合更新的功能
效果预览
主要就是放cmd效果的了,还有采集后的txt和word存储
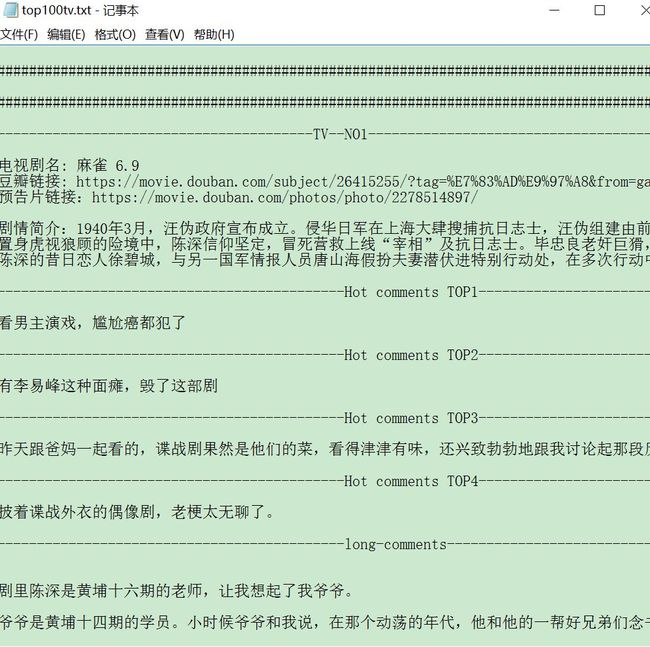
存储在word中

其中存储在word中的,我昨晚一直让他自己跑,大概花了三个小时左右,采集的是全类数据,也就是加载各类选项等。word中436页,34W字瞩目。。。
CMD版本代码
# -*- coding: utf-8 -*-
#Author:哈士奇说喵
#爬豆瓣高分电影及hot影评CMD版本1.0
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
from docx import Document
def Main(j=1):
class_MT,kind,sort,ask_urls,ask_brief,ask_comments,ask_recommends,number,save_name,save_docx_name,timer = Init()
if timer == 1:start = time.time()
SUMRESOURCES=0
url="https://movie.douban.com/"
print "----------------------------------------------Launch Firefox----------------------------------------------"
driver_item=webdriver.Firefox()
#driver_item=webdriver.Chrome("C:\\Program Files (x86)\\Google\\Chrome\\Application\\chromedriver.exe")
wait = ui.WebDriverWait(driver_item,15)
driver_item.get(url)
Write_txt('\\n##########################################################################################','\\n##########################################################################################',save_name)
print "----------------------------------------------Crawling...----------------------------------------------"
##############################################################################
#进行网页get后,先进行电影种类选择的模拟点击操作,然后再是排序方式的选择
#最后等待一会,元素都加载完了,才能开始爬电影,不然元素隐藏起来,不能被获取
#wait.until是等待元素加载完成!
##############################################################################
if class_MT==1:
#选完参数后,开始爬操作
if save_docx_name != 0:document.add_heading('Movie TOP', 0)
driver_item.get(url)
time.sleep(1) # 更加模拟人类操作,在点击电影的同是肯定过段时间点击按照何种排序
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind).click()
time.sleep(1)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort).click()
num=number+1#比如输入想看的TOP22,那需要+1在进行操作,细节问题
#打开几次“加载更多”保险起见,多开一次加载
num_time = num/20+2
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[20]"))
for times in range(1,num_time):
driver_item.find_element_by_xpath("//div[@class='list-wp']/a[@class='more']").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[%d]"%(20*(times+1))))
#使用wait.until使元素全部加载好能定位之后再操作,相当于try/except再套个while把
for i in range(j,num):
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a[%d]"%num))
list_title=driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%i)
print '----------------------------------------------'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------'
moviename = u'电影名: ' + list_title.text
movieurl = u'豆瓣链接: ' + list_title.get_attribute('href')
print moviename
print movieurl
#防止页面出现重复错误,增加迭代修正
while list_title.text==driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%(i+20)).text:
print u'遇到页面加载重复项bug,开始重新加载...'
j = i
driver_item.quit()
Main(j)
#写入txt中
if save_name != 0:
Write_txt('\\n------------------------------------------Movies--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------','',save_name)
Write_txt(moviename.encode('utf-8'),movieurl.encode('utf-8'),save_name)
# 写入word操作
if save_docx_name != 0:
p = document.add_paragraph('-----------------------------------------------Movies--'+'NO' + str(SUMRESOURCES +1)+'---------------------------------------------------')
p = document.add_paragraph("%s"%(moviename))
p = document.add_paragraph("%s"%(movieurl))
#document.save('demo.docx')
SUMRESOURCES = SUMRESOURCES +1
#获取具体内容和评论。href是每个超链接也就是资源单独的url
try:
getDetails(str(list_title.get_attribute('href')),ask_comments,ask_brief,ask_recommends,ask_urls,save_name,save_docx_name,timer)
except:
print 'can not get the details!'
#爬完数据后关闭浏览器,只保留GUI进行下一步操作
driver_item.quit()
#选择电视剧之后的操作,也不知道为什么电视剧按照hot排序一直重复页面,只有设置静态等待时间
if class_MT == 2:
#选完参数后,开始爬操作,选电视剧需要多点击一次,因为默认为电影
driver_item.get(url)
if save_docx_name != 0:document.add_heading('TV TOP', 0)
time.sleep(1)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/h2/a[2]"))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/h2/a[2]").click()
time.sleep(1)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div/div/label[%s]"%kind).click()
time.sleep(1)
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort))
driver_item.find_element_by_xpath("//div[@class='fliter-wp']/div/form/div[3]/div/label[%s]"%sort).click()
num=number+1#比如输入想看的TOP22,那需要+1在进行操作,细节问题
driver_item.find_element_by_xpath(".//*[@id='gallery-frames']/div[1]/div[1]/span[2]/a").click()
driver_item.find_element_by_xpath(".//*[@id='gallery-frames']/div[1]/div[1]/span[1]/a").click()
#打开几次"加载更多",因为要解决点击后页面可能重复的问题,所以这里多点一次
num_time = num/20+2
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[20]"))
for times in range(1,num_time):
driver_item.find_element_by_xpath("//div[@class='list-wp']//a[@class='more']").click()
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list-wp']/div/a[%d]"%(20*(times+1))))
#使用wait.until使元素全部加载好能定位之后再操作,相当于try/except再套个while把
for i in range(j,num):
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='list']/a[%d]"%num))
list_title=driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%i)
print '-------------------------------------------TV--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------'
moviename = u'电视剧名: ' + list_title.text
movieurl = u'豆瓣链接: ' + list_title.get_attribute('href')
print moviename
print movieurl
#print unicode码自动转换为utf-8的
#防止页面出现重复错误,增加迭代修正
while list_title.text==driver_item.find_element_by_xpath("//div[@class='list']/a[%d]"%(i+20)).text:
print u'遇到页面加载重复项bug,开始重新加载...'
j = i # 从重复起始项开始加载
driver_item.quit()
Main(j)
if save_docx_name != 0:
p = document.add_paragraph('-----------------------------------------------TV--'+'NO' + str(SUMRESOURCES +1)+'---------------------------------------------------')
p = document.add_paragraph("%s"%(moviename))
p = document.add_paragraph("%s"%(movieurl))
#写入txt中
if save_name != 0:
Write_txt('\\n----------------------------------------TV--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------','',save_name)
Write_txt(moviename.encode('utf-8'),movieurl.encode('utf-8'),save_name)
SUMRESOURCES = SUMRESOURCES +1
#获取具体内容和评论。href是每个超链接也就是资源单独的url
try:
getDetails(str(list_title.get_attribute('href')),ask_comments,ask_brief,ask_recommends,ask_urls,save_name,save_docx_name,timer)
except:
print 'can not get the details!'
#爬完数据后关闭浏览器,只保留GUI进行下一步操作
driver_item.quit()
#本周口碑榜TOP10
if class_MT==3:
#选完参数后,开始爬操作
driver_item.get(url)
if save_docx_name != 0:document.add_heading('TOP10 M&T', 0)
for i in range(1,11):
wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='billboard-bd']/table/tbody/tr"))
list_title=driver_item.find_element_by_xpath("//div[@class='billboard-bd']/table/tbody/tr[%d]/td[2]/a"%i)
print '----------------------------------------------'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------'
moviename = u'影视名: ' + list_title.text+' '+getStar(list_title.get_attribute('href'))
movieurl = u'豆瓣链接: ' + list_title.get_attribute('href')
print moviename
print movieurl
if save_docx_name != 0:
# 写入word操作
p = document.add_paragraph('----------------------------------------------WeekTOP--'+'NO' + str(SUMRESOURCES +1)+'--------------------------------------------------')
p = document.add_paragraph("%s"%(moviename))
p = document.add_paragraph("%s"%(movieurl))
#写入txt中
if save_name != 0:
Write_txt('\\n------------------------------------------WeekTOP--'+'NO' + str(SUMRESOURCES +1)+'----------------------------------------------','',save_name)
Write_txt(moviename.encode('utf-8'),movieurl.encode('utf-8'),save_name)
SUMRESOURCES = SUMRESOURCES +1
#获取具体内容和评论。href是每个超链接也就是资源单独的url
try:
getDetails(str(list_title.get_attribute('href')),ask_comments,ask_brief,ask_recommends,ask_urls,save_name,save_docx_name,timer)
except:
print 'can not get the details!'
#爬完数据后关闭浏览器,只保留GUI进行下一步操作
driver_item.quit()
if timer == 1:
end = time.time()
print "------------------------Done!It Costs About %.2f Seconds-------------------------"%(end-start)
if save_docx_name != 0:document.save(save_docx_name)
##############################################################################
#当选择一部电影后,进入这部电影的超链接,然后才能获取
#同时别忽视元素加载的问题
#在加载长评论的时候,注意模拟点击一次小三角,不然可能会使内容隐藏
##############################################################################
def getDetails(url,comments,brief,recommends,needurl,save_name,save_docx_name,timer):
driver_detail = webdriver.PhantomJS(executable_path="phantomjs.exe")
wait1 = ui.WebDriverWait(driver_detail,15)
driver_detail.get(url)
wait1.until(lambda driver: driver.find_element_by_xpath("//div[@id='link-report']/span"))
drama = driver_detail.find_element_by_xpath("//div[@id='link-report']/span")
pre_url = driver_detail.find_element_by_xpath("//div[@id='related-pic']/ul/li/a").get_attribute('href')
# 判断是否需要预告片链接
if needurl == 1:
pre_urlp = u"预告片链接:"+pre_url
print pre_urlp
if save_docx_name != 0:p = document.add_paragraph("%s"%(pre_urlp))
if save_name != 0:Write_txt(pre_urlp.encode('utf-8'),'',save_name)
# 是否需要加载简介
if brief == 1:
dramap = u"剧情简介:"+drama.text
print "----------------------------------------------Synopsis----------------------------------------------"
print drama.text
if save_docx_name != 0:p = document.add_paragraph("%s"%(dramap))
if save_name != 0:Write_txt(dramap.encode('utf-8'),'',save_name)
# 是否加载评论
if comments == 1:
print "--------------------------------------------Hot comments TOP----------------------------------------------"
#加载四个短评
for i in range(1,5):
try:
comments_hot = driver_detail.find_element_by_xpath("//div[@id='hot-comments']/div[%s]/div/p"%i)
print u"最新热评:"+comments_hot.text
if save_docx_name != 0:
p = document.add_paragraph("--------------------------Hot comments TOP%d--------------------------"%i)
p = document.add_paragraph(u"最新热评:%s"%(comments_hot.text))
comments_hot_wr=comments_hot.text.encode('utf-8')
if save_name != 0:
Write_txt("--------------------------------------------Hot comments TOP%d----------------------------------------------"%i,'',save_name)
Write_txt(comments_hot_wr,'',save_name)
except:
print 'can not caught the comments!'
#尝试加载长评
try:
driver_detail.find_element_by_xpath("//img[@class='bn-arrow']").click()
#wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='review-bd']/div[2]/div/div"))
time.sleep(1)
#解决加载长评会提示剧透问题导致无法加载
comments_get = driver_detail.find_element_by_xpath("//div[@class='review-bd']/div[2]/div")
if comments_get.text.encode('utf-8')=='提示: 这篇影评可能有剧透':
comments_deep=driver_detail.find_element_by_xpath("//div[@class='review-bd']/div[2]/div[2]")
else:
comments_deep = comments_get
print "--------------------------------------------Long-comments---------------------------------------------"
print u"深度长评:"+comments_deep.text
if save_docx_name != 0:
p = document.add_paragraph("--------------------------------------------Long-comments--------------------------------------------")
p = document.add_paragraph("%s"%(comments_deep.text))
comments_deep_wr=comments_deep.text.encode('utf-8')
if save_name != 0:
Write_txt("--------------------------------------------long-comments---------------------------------------------\\n",'',save_name)
Write_txt(comments_deep_wr,'',save_name)
except:
print 'can not caught the deep_comments!'
if recommends == 1:
print u"------------------------------------------喜欢该片的人还喜欢------------------------------------------"
if save_docx_name != 0:p = document.add_paragraph("------------------------------------------Recommends------------------------------------------")
if save_name != 0:Write_txt("------------------------------------------Recommends------------------------------------------",'',save_name)
for i in range(1,11):
recommand = driver_detail.find_element_by_xpath("//div[@class='recommendations-bd']/dl[%d]/dd/a"%i)
recommand_name =recommand.text
recommand_url = recommand.get_attribute('href')
star = getStar(recommand_url)
more = u"%s %s : %s"%(recommand_name,star,recommand_url)
print more
if save_docx_name != 0:p = document.add_paragraph("%s"%(more))
if save_name != 0:Write_txt(more.encode('utf-8'),'',save_name)
##############################################################################
#将print输出的写入txt中查看,也可以在cmd中查看,换行符是为了美观
##############################################################################
def Write_txt(text1='',text2='',title='douban.txt'):
with open(title,"a") as f:
for i in text1:
f.write(i)
f.write("\\n")
for j in text2:
f.write(j)
f.write("\\n")
# 自定义了一个单纯获取评分的子函数,用于推荐电影时候把其获取评分
def getStar(url):
driver_star = webdriver.PhantomJS(executable_path="phantomjs.exe")
wait1 = ui.WebDriverWait(driver_star,15)
try:
driver_star.get(url)
wait1.until(lambda driver: driver.find_element_by_xpath("//div[@class='rating_self clearfix']"))
star = driver_star.find_element_by_xpath("//div[@class='rating_self clearfix']/strong").text
return star
except:
return None
def Init():
class_MT = input("---------------Movie or TV---------------\\n1-Movie 2-TV 3-TOP10 M&T\\nPlease Select: ")
if class_MT != 3:
if class_MT == 1:
kind=input("---------------What kind do you like?---------------\\nHot-1 Newest-2 Classics-3\\nPlayable-4 High Scores-5 Wonderful but not popular-6\\nChinese film-7 Hollywood-8 Korea-9\\nJapan-10 Action movies-11 Comedy-12\\n1Love story-13 Science fiction-14 Thriller-15\\nHorror film-16 Cartoon-17\\nPlease Select:")
if class_MT ==2:
kind=input("---------------What kind do you like?---------------\\nHot-1 American TV-2 UK TV-3\\nKorean TV-4 Japanese TV-5 Chinese TV-6\\nTVB-7 Cartoon-8 Variety-9\\nPlease Select:")
sort=input("---------------Sort by what?---------------\\nSort by hot-1 Sort by time-2 Sort by score-3\\nPlease Select:")
number = input("---------------TOP?---------------\\nPlease Select:")
else:
kind = 1
sort = 1
number= 1
ask_urls = input("---------------Need Trailer?---------------\\nNo Trailer_Url-0 I Need Trailer_Url-1\\nPlease Select:")
ask_brief = input("---------------Need Brief?---------------\\nNo Brief-0 I Need Brief-1\\nPlease Select:")
ask_comments = input("---------------Need Review?---------------\\nNo film reviews-0 I like film reviews-1\\nPlease Select:")
ask_recommends = input("---------------Need Recommends?---------------\\nNo Recommends-0 I Need Recommends-1\\nPlease Select:")
save_name=raw_input("---------------How about store?---------------\\nSave name (xx.txt) No thanks-0\\nPlease Select:")
save_docx_name=raw_input("Save docx name (xx.docx) No thanks-0\\nPlease Select:")
timer = input("---------------Want know how much time it cost?---------------\\nStart the timer-1 No thanks-0\\nPlease Select:")
return class_MT,kind,sort,ask_urls,ask_brief,ask_comments,ask_recommends,number,save_name,save_docx_name,timer
if __name__ == '__main__':
print "---------------Made By MrLevo520---------------"
document = Document()
while True:
Main()
contiune = raw_input("---------------Enter 1 To Continue Others To Quit---------------\\nPlease Select:")
if contiune != "1":break
如果不算乱七八糟的注解大概两百多行把,貌似还是有点多额,不过核心的都有点重复了,我懒得再写子函数了,或许下次再精简一下代码
已上传GUI版本源码和CMD版本源以及成品exe文件,如有需要可以下载豆瓣自定义抓取2.0版本
写入Word
- python docx包下载
- python docx实例参考
上面提供了第三包的下载地址和实例,如果第三方包还不会安装,请百度安装。
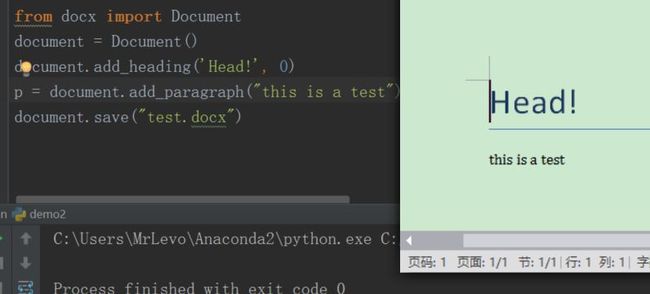
实例用法比较多,我们大概只需要用到其中的一两种就可以了,比如添加heading和正文 最简单的实例如下
from docx import Document # 导入包
document = Document() # 实例化
document.add_heading('Head!', 0) # 添加heading和摆放位置
p = document.add_paragraph("this is a test") # 添加正文
document.save("test.docx") # 存储文件
大概是这样的
Q&A
1.出现不能获取评论的bug,在我昨晚的采集活动中,发现最后几个电影都没有获取到评论,但是其余的电影获取没有问题,应该不是代码问题,截图测试
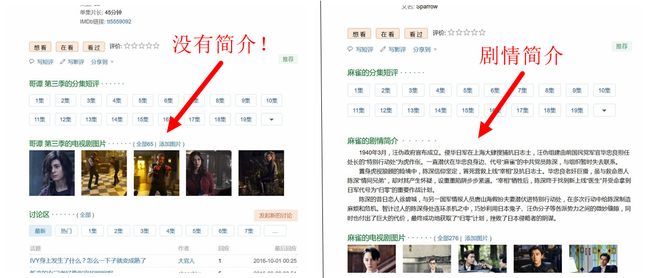
坑爹的连简介都没有!!!豆瓣是太懒了么,,,,还是丢了。。。。。我才不会为几个特例重写规则,还好我用try不然卡死在半夜这多不值啊。
2.重复加载bug几率太高。在测试过程中,特别是sort by hot的时候,每次几乎都会出现重复加载bug,就是点击加载更多,之后重复加载了第一页,这个bug我在以前的文章中尝试用递归重新加载去解决,虽然可以解决,但是重复加载的bug日益明显,我在考虑是不是我的策略错误,思想的方法要把爬虫想成人类,人类一般点击完电影选项后不可能非常快的点击排序方式的,所以我使用我以前鄙视的静态等待一秒的时间,竟然完美解决问题。可喜可贺!
Pay Attention
关于采集速度太慢的问题,没办法,取决于网速,还有策略,这里用的是动态爬取的,所以不能用requests和urllib2等静态方法,selenium+PhantomJS/Firefox本来就是这个鸟速度,我也无解,不知是我写法问题还是本身问题
在打包成exe的cmd版本时候,如果需要显示中文,最好的方法就是在编译器中的中文是unicode码的,也就是说,像是这样
print u"----中文测试----"在IDE下输出当然是自动转化成utf-8输出的,但是在打包文件时候直接写utf-8的中文会乱码的。但是,写入txt的时候需要encode成utf-8的,而在写入word中的时候则是直接用unicode码写入,具体得可以自己测试。
最后
豆瓣的爬取项目好久没碰了,今天国庆,一边看电影一边把代码修改下,羞愧的用了"高阶"这个标题了,暂且用个"高阶上"把,以后采用分布式和多线程集群等方法的时候再重写"高阶下"把。
最后的最后
前几天刚拿到绿盟的实习offer,还是我很喜欢的数据挖掘/机器学习工程师的职位,很开心,虽然自己折腾的时间或许会少一点了,但这都不重要,这本身就是我自己记录学习历程的博客,如果有人关注,也很荣幸。
大家国庆快乐咯!
致谢
python docx包下载
python docx实例参考
@MrLevo520--Python自定义豆瓣电影种类,排行,点评的爬取与存储(基础)
@MrLevo520--Python自定义豆瓣电影种类,排行,点评的爬取与存储(初级)
@MrLevo520--Python自定义豆瓣电影种类,排行,点评的爬取与存储(进阶上)
@MrLevo520--Python自定义豆瓣电影种类,排行,点评的爬取与存储(进阶下)