实战计划0430-石头的练习作业
练习的要求
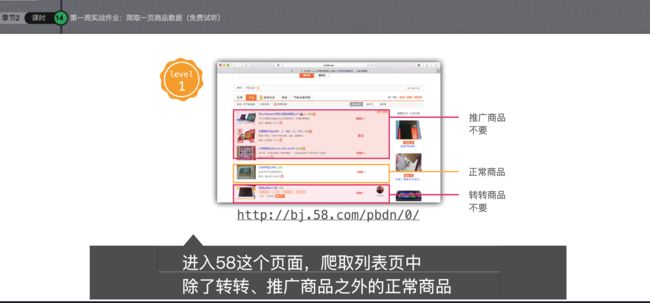
爬取列表页
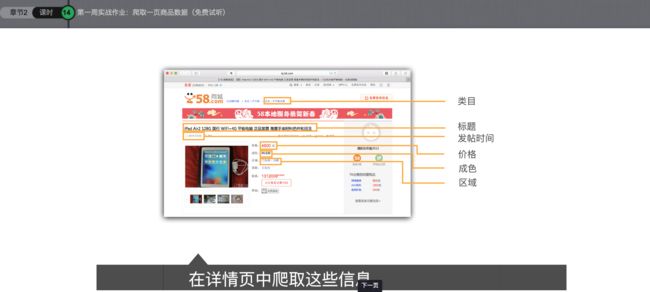
爬取详情页
效果如下:

实现效果
实现的代码
__author__ = 'daijielei'
'''
14课时练习:
1、抓取58同城的列表页中的除转转和推广商品外的全部列表内容
2、抓取详情页里的各项信息内容
!!!未完全实现该部分功能,抓取浏览量因为该部分由JS控制,目前找到的方法无效
'''
#requests用于抓取html页面,BeautifulSoup用于html页面的解析
from bs4 import BeautifulSoup
import requests
import time
url = "http://bj.58.com/pbdn/0/"
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36',
'Cookie':'f=n; ipcity=ly%7C%u9F99%u5CA9; userid360_xml=ECD6EBC44A953F262599ECBF200466C6; time_create=1462540691216; myfeet_tooltip=end; bj58_new_session=1; bj58_init_refer=""; bj58_new_uv=1; bj58_id58s="cj1xSHUxVUZhWnhZNjc3Nw=="; sessionid=72fb3011-18c9-4edb-bab8-6da3336820e3; id58=c5/njVcFC7yd81HAAxYnAg==; 58tj_uuid=ab2a30b9-8b32-43fc-8e6c-52d7cff7254f; new_session=1; new_uv=1; utm_source=; spm=; init_refer=; als=0; br58=index_old; f=n',
'host':'bj.58.com'
}
'''
get58List
用于抓取58的列表里的基础信息
会剔除推广和转转的链接
测试用#url = "http://bj.58.com/pbdn/0/"
'''
def get58List(url):
webData = requests.get(url)
soup = BeautifulSoup(webData.text,'lxml')
infos = soup.select('table[class="tbimg"]')#每一块的结构类似,先根据其基本结构提取出一块块内容
count = 0
#对每一块结构进行处理,以做更细致的处理
for info in infos:
if(info.find('td',attrs={'class':'img'})):#判断是否有效,以过滤掉百度推广的数据
count = count + 1
img = info.find('td',attrs={'class':'img'}).img.get('lazy_src')
title = info.find('a',attrs={'class':'t'}).get_text()
jumpUrl = str(info.find('td',attrs={'class':'img'}).a.get('href')).replace('&','')#抓取跳转链接,对地址替换掉58的限制用内容
qq_attest = info.find('div',attrs={'class':'qq_attest'})
if(qq_attest==None):#对转转的数据进行识别,只有对58的页面才进行详情页的抓取
if('x.shtml' in jumpUrl):
jumpUrl = jumpUrl.split('?psid')[0]
get58Info(jumpUrl)
#print(img,title,jumpUrl,qq_attest)
#提取下一页的地址
if(soup.find('a',attrs={'class':'next'})):
if(count == 0):#判断该页是否有数据,如果已经没有数据,则停止返回下一页地址
print('本页已经无内容')
return None
nextUrl = "http://bj.58.com" + str(soup.find('a',attrs={'class':'next'}).get('href')).replace('&','')
print("nextUrl:"+nextUrl)
return nextUrl
'''
get58Info_Count
获取JS里的count数据,
!!!目前该部分无法使用
'''
def get58Info_Count(url):
count = "0"
#http://bj.58.com/pingbandiannao/25461164017856x.shtml
id = url.rsplit('/')[-1].replace("x.shtml","")#从连接里提取出页面ID
api = "http://jst1.58.com/counter?infoid={}".format(id)#将页面ID并入API中
data = requests.get(api)
count = data.text.split('=')[-1]#从返回的数据中提取出count值
return count
'''
get58Info
用于抓取58详情页里的相关信息
1、价格、成色、区域的获取比较特殊,没有能够识别的标签,故采用抓取内容后识别对应文字的方法
2、count来源于js里,直接抓取的数据0为无效数据
测试用#url = "http://bj.58.com/pingbandiannao/25461164017856x.shtml"
'''
def get58Info(url):
webData = requests.get(url)
soup = BeautifulSoup(webData.text,'lxml')
time.sleep(1)
#利用BeautifulSoup从html文件里抓取到对应的数据
#格式化数据,在格式化数据中直接给数据赋值
data = {
"type":soup.find('div',attrs={'class':'breadCrumb f12'}).get_text().replace('\n', '-').replace('\t', '-'),
"title":soup.find('div',attrs={'class':'col_sub mainTitle'}).h1.get_text(),
"time":soup.find('li',attrs={'class':'time'}).get_text(),
"count":soup.find('li',attrs={'class':'count'}).get_text(),
"price":soup.select('span.price')[0].get_text(),
"howGood":"None",
"where":soup.select('.c_25d')[0].get_text().split() if soup.select('.c_25d') else "None" #安全判断,防止无该数据项出错
}
#成色没法直接区分,抓取出数据后通过if进行文字判断进行筛选
for element in soup.find('ul',attrs={'class':'suUl'}).find_all('li'):
text = str(element.get_text())
if('成色' in text):
data["howGood"] = text.replace(' ', '').replace('\n', '').replace('\t', '')
break
data["count"] = str(get58Info_Count(url))
print(data)
'''
get58ByNum
通过url的组装规则,根据要便利的页面范围,去生成对应的url列表,通过遍历列表调用get58List去实现数据抓取
'''
def get58ByNum(start=0,end=5):
urls = ["http://bj.58.com/pbdn/0/pn{}/".format(str(i)) for i in range(start,end)]
for url in urls:
get58List(url)
'''
get58fromPageToEnd
通过在get58List里加入返回值,会返回下一页的地址,通过while语句不断的访问,直到返回的url无效为止。
'''
def get58fromPageToEnd(start=0):
url = "http://bj.58.com/pbdn/0/pn{}/".format(str(start))
while url:
url = get58List(url)
time.sleep(3)
#入口
__Mode__ = ''#'PageNumber2PageNumber' # 'PageNumber2END'
if __name__ == '__main__':
if __Mode__ == 'PageNumber2PageNumber':
get58ByNum(0,3)
elif __Mode__ == 'PageNumber2END':
get58fromPageToEnd(50)
#url = "http://bj.58.com/pingbandiannao/25461164017856x.shtml"
#get58Info(url)
url = "http://bj.58.com/pbdn/0/"
get58List(url)
想法、笔记、总结
1、这个的实现,主要有2块,一块是抓取列表里的信息,把列表里的每个详情页的url抓取出来
1、抓取列表里的信息,把每个列表里的详情页的url抓取出来,交由get58Info去获取详情页里的内容
def get58List(url):
2、将详情页里的详细内容抓取出来,把需要抓取的都抓取出来
def get58Info(url):
2、里面有些数据比较难以获取,比如说成色,需要获取一类的类似标签后从中便利挑选
其html代码段如下,没办法细分出全部内容:
价格:
1100元
成色:
-
区域:
只能获取出同类的项目进行便利,然后进行判断是否是成色,是的话从中提取出对应的数据
for element in soup.find('ul',attrs={'class':'suUl'}).find_all('li'):
text = str(element.get_text())
if('成色' in text):
data["howGood"] = text.replace(' ', '').replace('\n', '').replace('\t', '')
break