大家好,上一篇支持向量机(Support Vector Machines-SVM)算法笔记(一)-Python主要提到了支持向量机的算法原理、简单SMO算法的实现等,今天接着上一篇提到的内容,主要侧重于:完整SMO算法的实现、编程遇到的小问题等。核函数的变成实现将在下一阶段深入学习中来研究
再次申明:本文的理论知识来自Peter Harrington的《机器学习实战》和李航的《统计学习方法》,非常感谢这些优秀人物和优秀书籍
1、完整SMO算法
上一篇支持向量机(Support Vector Machines-SVM)算法笔记(一)-Python最后提到的简单SMO算法,在100个数据集、2个特征值的处理问题中,花了6秒30左右,那么当数据集在万级以上,这个算法的效率估计可以回到解放前了。之所以这个算法在大量数据集上效果这么差,很大一部分原因出在alpha参数的选择。
SMO算法是通过一个外循环来选择第一个alpha值,并且其选择过程会在两种方式之间进行交替:一种方式是在所有的数据集进行单遍扫描,另一种方式则是在非边界alpha中实现单遍扫描。而所谓非边界alpha指的是那些不等于边界0或C的alpha值。对整个数据集的容易,而在实现非边界alpha值的扫描时,首先需要建立这些alpha值的列表,然后再对这个表进行遍历。同时,该步骤会跳过那些已知的不会改变的alpha值。在选择第一个alpha值后,算法会通过一个内循环来选择第二个alpha值。在优化过程中,会通过最大化步长的方式来获得第二个alpha值。 在上一篇中的简单SMO算法的实现中,我们在选择j之后计算错误率Ej。但是,在完整版的SMO算法里,将建立一个全局的缓存用于保存误差值,并从中选择使得步长或者Ei-Ej最大的alpha值。
完整版SMO算法的相关代码如下:
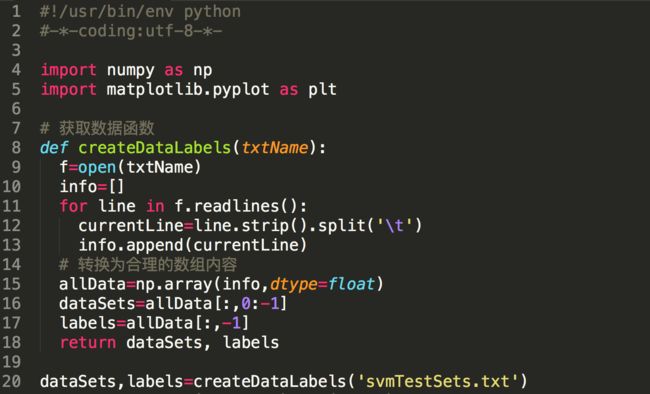
1)准备数据
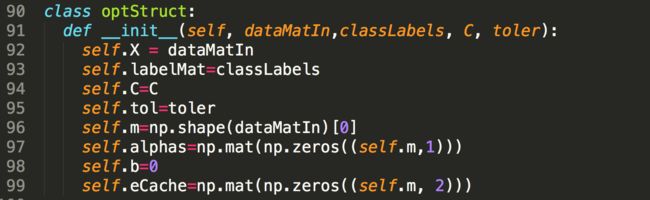
2)建立一个类存放基本数据以及alphas的缓存
3)建立计算错误率的函数

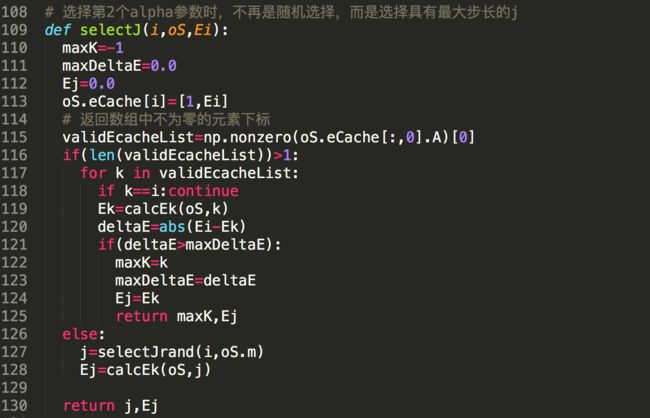
4)在选择第2个alphas参数时(也就是进行SMO的内循环时),不再是随机选择,而是选择最长步长的那个(就是选择|E_i-Ej|最大的)
5)更新错误率Ek

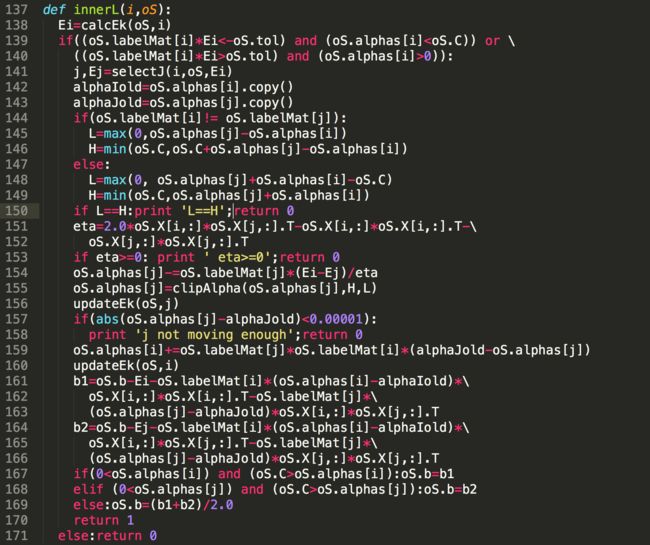
6)更新b并且返回两个alpha参数是否改变的情况
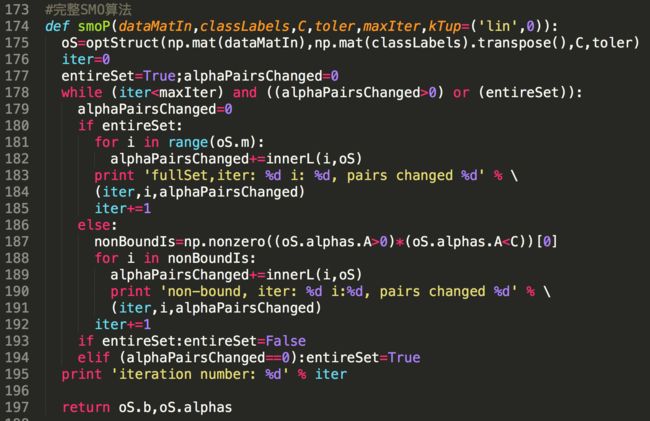
7)完整版SMO算法
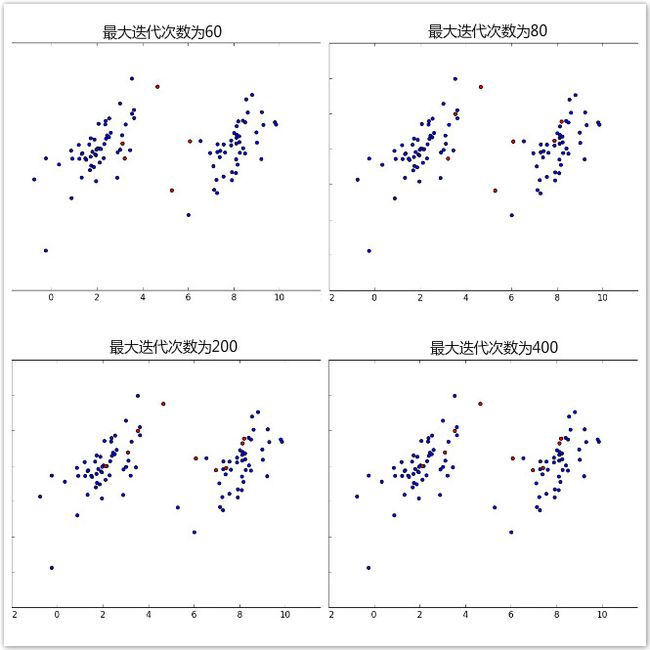
8)查看完整的SMO算法的效果怎么样
设置不同的最大迭代次数,发现迭代次数的增加,支持向量的数量会增加,但是到某些数值后,将不再增加,比如迭代次数200和迭代次数400时基本不变了,见图8(红色点为支持向量)
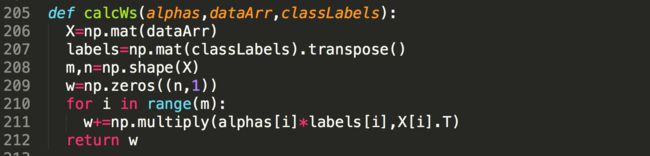
9)基于支持向量来进行样本分类-求解权重
先求解超平面的权重参数w,计算公式主要是依据上一篇支持向量机(Support Vector Machines-SVM)算法笔记(一)-Python第11张图中的w计算方法。代码如下:
10)最终SMO分类
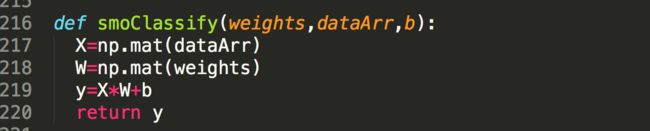
图中10中返回正数,则分类标记为+1;图10中返回负数,则标记为-1
好哒,SMO函数基本告一段落,接下来主要是分享一些Python编程问题。关于numpy等Python科学库,建议参考One document to learn numerics, science, and data with Python
1、对比numpy中的array与mat
1)np.array([...])和np.array([[...]])是不一样的
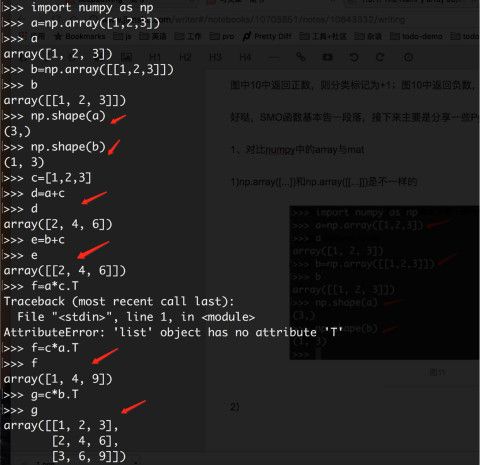
2)np.array创建的数组,获取元素的方法([a,b],a表示行,b表示列,当然在二维范围内)
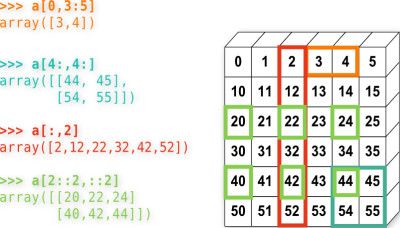
3)np.array的siblings包括:chararray,maskedarray,matrix
chararray

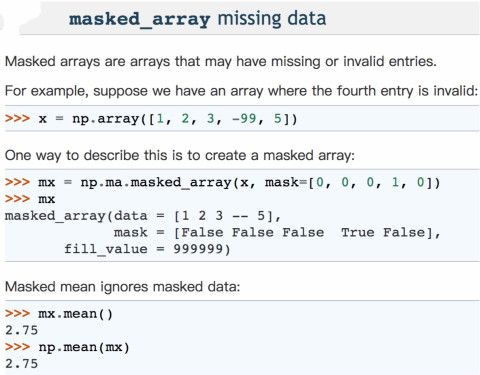
maskedarray:这个函数主要是针对数组中有丢失数据或者无效的数据,比如有时候在计算中,不想让某些异常点参与运算,可以让他遮罩处理,比如下面的-99
matrix(可以简写为np.mat):这是为了计算方便,单独作为array的子模块,只针对二维数组
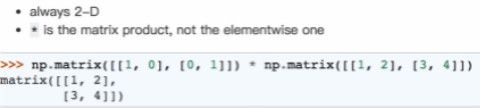
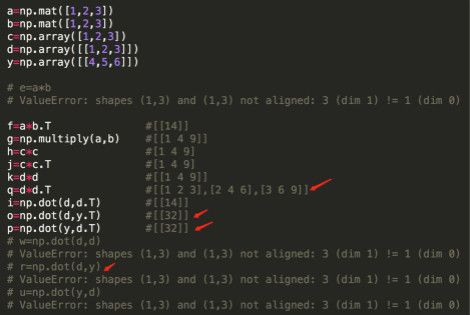
在图15中,提到的matrix数组的“*”表示数组相乘。而np.array数组‘*’表示两个数组的相同位置上的数字做乘法,np.dot(a,b)表示数组a和b相乘
numpy中,matrix与array的对比:
1)np.matrix([1,2,3])与np.array([[1,2,3]])一样的效果,但是不同于np.array([1,2,3]):
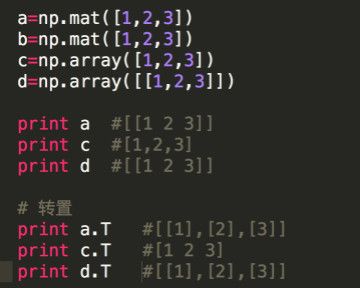
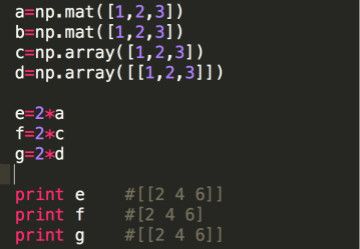
2)数乘:np.matrix与np.array没有差异
3)向量相乘,matrix矩阵的“*”相当于np.dot,而np.multiply与np.array矩阵的‘*’是一样的效果-数组相同位置上的数相乘
4)向量除法
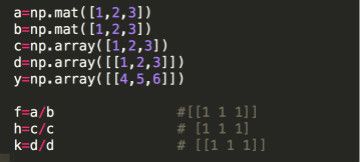
5)矩阵相除
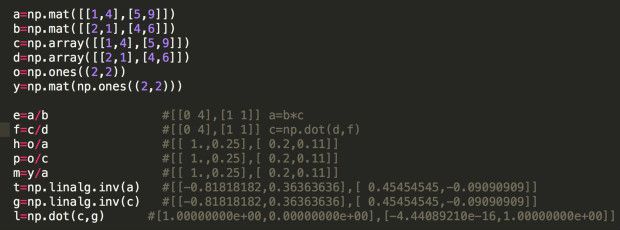
在进行矩阵除法的过程中,我发现以下问题:
(1)np.linalg.inv(a)是求解a的逆矩阵,但是,因为精度的问题,矩阵a和他的逆矩阵乘起来,不一定为矩阵理论中的单位1矩阵I
(2)用ones矩阵除以任何一个矩阵时,发现结果不是另一个矩阵的逆矩阵,而是相同位置上,原来数组的取值均被1相除,有意思
(3)其余矩阵相除满足一般矩阵理论的除法。
一般明确知道是二维数组时,常用matrix构建,因为其计算与矩阵理论以及matlab里计算方法更加贴切。但是,高维数组则只能用np.array()来处理了。
基本就是这些,希望对大家有所帮助,同请大牛知道,谢谢~~