原文链接
- Grunt -> Gulp
早些年提到构建工具,难免会让人联想到历史比较悠久的Make,Ant,以及后来为了更方便的构建结构类似的Java项目而出现的Maven。Node催生了一批自动化工具,像Bower,Yeoman,Grunt等。而如今前端提到构建工具会自然想起Grunt。Java世界里的Maven提供了强大的包依赖管理和构建生命周期管理。
在JavaScript的世界里,Grunt.js是基于Node.js的自动化任务运行器。2013年02月18日,Grunt v0.4.0 发布。Fractal公司积极参与了数个流行Node.js模块的开发,它去年发布了一个新的构建系统Gulp,希望能够取其精华,并取代Grunt,成为最流行的JavaScript任务运行器。 - Grunt的特点
Grunt有一个完善的社区,插件丰富
它简单易学,你可以随便安装插件并配置它们
你不需要多先进的理念,也不需要任何经验
完善 – Grunt的插件数据: 根据社区的结果显示,共计3,439个插件,其中49个官方插件。
易用 – Grunt的插件丰富: 许多常见的任务都有现成的Grunt插件,而且有众多第三方插件,如:
- CoffeeScript
- Handlebars
- Jade
- JsHint
- Less
- RequireJS
- Sass
- Styles
。而且通过参考文档进行配置便可以使用。
- Gulp和Grunt的异同点
易于使用:采用代码优于配置策略,Gulp让简单的事情继续简单,复杂的任务变得可管理。
高效:通过利用Node.js强大的流,不需要往磁盘写中间文件,可以更快地完成构建。
高质量:Gulp严格的插件指导方针,确保插件简单并且按你期望的方式工作。
易于学习:通过把API降到最少,你能在很短的时间内学会Gulp。构建工作就像你设想的一样:是一系列流管道。易用
Gulp相比Grunt更简洁,而且遵循代码优于配置策略,维护Gulp更像是写代码。高效
Gulp相比Grunt更有设计感,核心设计基于Unix流的概念,通过管道连接,不需要写中间文件。高质量
Gulp的每个插件只完成一个功能,这也是Unix的设计原则之一,各个功能通过流进行整合并完成复杂的任务。例如:Grunt的imagemin
插件不仅压缩图片,同时还包括缓存功能。他表示,在Gulp中,缓存是另一个插件,可以被别的插件使用,这样就促进了插件的可重用性。目前官方列出的有673个插件。
易学
Gulp的核心API只有5个,掌握了5个API就学会了Gulp,之后便可以通过管道流组合自己想要的任务。
- Yeoman Team Talks
Yeoman团队去年12月份时在Github上也专门提过一个issue,讨论是否使用Gulp取代Grunt:他们提到Gulp是一个新的基于流的管道式构建系统,需要很少的配置并且更快。 - Gruntfile.js
module.exports = function(grunt) {grunt.initConfig({ concat: { 'dist/all.js': ['src/*.js'] }, uglify: { 'dist/all.min.js': ['dist/all.js'] }, jshint: { files: ['gruntfile.js', 'src/*.js'] }, watch: { files: ['gruntfile.js', 'src/*.js'], tasks: ['jshint', 'concat', 'uglify'] }});// Load Our Pluginsgrunt.loadNpmTasks('grunt-contrib-jshint');grunt.loadNpmTasks('grunt-contrib-concat');grunt.loadNpmTasks('grunt-contrib-uglify');grunt.loadNpmTasks('grunt-contrib-watch');// Register Default Taskgrunt.registerTask('default', ['jshint', 'concat', 'uglify']);};
- Gulpfile.js
var gulp = require('gulp');var jshint = require('gulp-jshint');var concat = require('gulp-concat');var rename = require('gulp-rename');var uglify = require('gulp-uglify');// Lint JSgulp.task('lint', function() {return gulp.src('src/*.js') .pipe(jshint()) .pipe(jshint.reporter('default'));});// Concat & Minify JSgulp.task('minify', function(){return gulp.src('src/*.js') .pipe(concat('all.js')) .pipe(gulp.dest('dist')) .pipe(rename('all.min.js')) .pipe(uglify()) .pipe(gulp.dest('dist'));});// Watch Our Filesgulp.task('watch', function() {gulp.watch('src/*.js', ['lint', 'minify']);});// Defaultgulp.task('default', ['lint', 'minify', 'watch']);
差异和不同
流:Gulp是一个基于流的构建系统,使用代码优于配置的策略。
插件:Gulp的插件更纯粹,单一的功能,并坚持一个插件只做一件事。
代码优于配置:维护Gulp更像是写代码,而且Gulp遵循CommonJS规范,因此跟写Node程序没有差别。
没有产生中间文件I/O流程的不同
使用Grunt的I/O过程中会产生一些中间态的临时文件,一些任务生成临时文件,其它任务可能会基于临时文件再做处理并生成最终的构建后文件。
而使用Gulp的优势就是利用流的方式进行文件的处理,通过管道将多个任务和操作连接起来,因此只有一次I/O的过程,流程更清晰,更纯粹。Gulp的核心:流
Gulp通过流和代码优于配置策略来尽量简化任务编写的工作。这看起来有点“像jQuery”的方法,把动作串起来创建构建任务。早在Unix的初期,流就已经存在了。流在Node.js生态系统中也扮演了重要的角色,类似于*nix将几乎所有设备抽象为文件一样,Node将几乎所有IO操作都抽象成了Stream的操作。因此用Gulp编写任务也可看作是用Node.js编写任务。当使用流时,Gulp去除了中间文件,只将最后的输出写入磁盘,整个过程因此变得更快。
Doug McIlroy, then head of the Bell Labs CSRC (Computing Sciences Research Center), and inventor of the Unix pipe, summarized the Unix philosophy as follows:
This is the Unix philosophy: Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface.
基于流的模块特点:
Write modules that do one thing and do it well.
Write modules that work together.
Write modules that handle events and streams.
Unix管道示例:
tput setaf 88 ; whoami | figlet | tr _ … | tr \ \ | tr | ¡ | tr / √
`
- 为什么应该使用流?
Node中的I/O操作是异步的,因此磁盘的读写和网络操作都需要传递回调函数。
var http = require('http');var fs = require('fs');var server = http.createServer(function (req, res) { fs.readFile(__dirname + '/data.txt', function (err, data) { res.end(data); });});server.listen(8000);
这个Node.js应用很简单,估计所有学习过Node的人都做过这样的练习,可以说是Node的Hello World了。这段代码没有任何问题,你使用node可以正常的运行起来,使用浏览器或者其他的http客户端都可以正常的访问运行程序主机的8000端口读取主机上的data.txt文件。但是这种方式隐含了一个潜在的问题,node会把整个data.txt文件都缓存到内存中以便响应客户端的请求(request),随着客户端请求的增加内存的消耗将是非常惊人的,而且客户端需要等待很长传输时间才能得到结果。让我们再看一看另外一种方式,使用流:
var http = require('http');var fs = require('fs');var server = http.createServer(function (req, res) { var stream = fs.createReadStream(__dirname + '/data.txt'); stream.pipe(res);});server.listen(8000);
这里面有一个非常大的变化就是使用createReadStream这个fs的方法创建了stream这个变量,并由这个变量的pip方法来响应客户端的请求。使用stream这个变量就可以让node读取data.txt一定量的时候就开始向客户端发送响应的内容,而无需服务缓存以及客户端的等待。
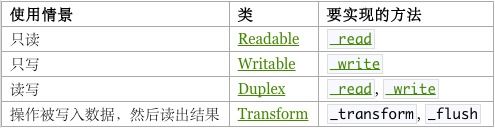
Node中Stream的种类
Readable(可读)
Writeable(可写)
Duplex(双工)
Transform(运算双工)
流可以是可读(Readable)或可写(Writable),或者兼具两者(Duplex,双工)的。所有流都是 EventEmitter,但它们也具有其它自定义方法和属性,取决于它们是 Readable、Writable 或 Duplex。
Depends on
Liftoff
Through2
Vinyl
, Vinyl-fs
Orchestrator
Liftoff
模块解决的问题是全局安装一个CLI工具,但支持多个项目多个配置文件,并且当前目录没有配置文件时,可以就近向上级目录找到已有的配置文件,或者在项目目录外执行命令行时可以指定配置文件的目录。所以Gulp基于liftoff
可以实现,多个项目多个Gulpfile,并且可以执行gulp
时指定配置文件路径。
Through2
是为Node的streams2.Transform
的小型封装,来避免subclassing
的烦恼。可以更简单的通过一个函数来创建一个流,而不用再繁琐的设置原型链的_transform
,_flush
,以及再扩充的Transform类中调用构造函数,以便缓冲设定能够正确初始化。
Vinyl
是用来描述文件的一个非常简单的元信息对象,Vinyl对象有两个主要的属性:path
和content
。因为一个文件不仅可能是你硬盘上的一些内容,还可能是你托管在S3,FTP,甚至DropBox上的一些内容,所以Vinyl可以描述所有这些来源的文件。它提供了一种简洁的描述文件的方式,但如果你需要访问本地文件系统上的一个文件,还需要通过一个所谓的Vinyl Adapter
,它会暴漏一些方法:如.src(globs)
,.dest(folder)
,和watch(globs, fn)
。globs是路径模式匹配。
Orchestrator
其实是一个基于Node的模块,负责任务依赖关系定义,处理和执行,很像我们目前所用的AMD模块加载器,而且默认是最大限度的并行加载的方式。
事实上,gulp中的任务运行系统并不是自己实现的,而是直接使用了orchestrator。在gulp的源代码中可以发现,gulp继承了orchestrator,而gulp.task仅仅只是orchestrator.add的别名而已:
//gulp source codevar util = require('util');var Orchestrator = require('orchestrator');function Gulp() { Orchestrator.call(this);}util.inherits(Gulp, Orchestrator);Gulp.prototype.task = Gulp.prototype.add;
- Gulp的API
- gulp.task
- gulp.run
- gulp.watch
- gulp.src
- gulp.dest
- gulp.task
在orchestrator中,解决上述任务依赖的方式有三种:
在任务定义的function中返回一个数据流,当该数据流的end事件触发时,任务结束。
在任务定义的function中返回一个promise对象,当该promise对象resolve时,任务结束。
在任务定义的function中传入callback变量,当callback()执行时,任务结束。
Gulp脚本中可以使用这三种方法来实现任务依赖,不过由于Gulp中的任务大多是数据流操作,因此以第一种方法为主。
- Gulp的插件开发
所有的Gulp.js插件基本都是through
(后面不再使用transform这个词)streams,即是消费者(接收gulp.src()
传递出来的数据,然后进行处理加工处理),又是生产者(将加工后的数据传递出去)。Gulp.js的使用和插件的开发都很简单,当然里面还有很多细节,抛砖引玉,具体请看Gulp.js的官方文档。