Apache Sqoop is a tool designed for efficiently transferring bulk data between Apache Hadoop and structured datastores such as relational databases.
Sqoop是RDBMS和Hadoop之间的一个桥梁RDBMS<<==>>Hadoop
平时说的导入导出都是以Hadoop为基准,即
导入:RDBMS==>>Hadoop
导出:RDBMS<<==Hadoop
http://sqoop.apache.org/
Sqoop底层是通过MapReduce来实现的,而且只有map没有reduce,只负责数据的迁移
一、sqoop-1.4.6-cdh5.7.0部署
1)下载
下载地址:http://archive.cloudera.com/cdh5/cdh/5/sqoop-1.4.6-cdh5.7.0.tar.gz
2)解压
[hadoop@hadoop001 software]$ tar -zxvf sqoop-1.4.6-cdh5.7.0.tar.gz -C ~/app
3)配环境变量
[hadoop@hadoop001 ~]$ vi .bash_profile
export SQOOP_HOME=/home/hadoop/app/sqoop-1.4.6-cdh5.7.0
export PATH=$SQOOP_HOME/bin:$PATH
[hadoop@hadoop001 ~]$ source .bash_profile
[hadoop@hadoop001 ~]$ which sqoop
~/app/sqoop-1.4.6-cdh5.7.0/bin/sqoop
4)修改sqoop配置文件
[hadoop@hadoop001 ~]$ cd $SQOOP_HOME/conf
[hadoop@hadoop001 conf]$ cp sqoop-env-template.sh sqoop-env.sh
[hadoop@hadoop001 conf]$ vi sqoop-env.sh
export HADOOP_COMMON_HOME=/home/hadoop/app/hadoop-2.6.0
export HADOOP_MAPRED_HOME=/home/hadoop/app/hadoop-2.6.0
export HIVE_HOME=/home/hadoop/app/hive-1.1.0-cdh5.7.0
5)copy mysql驱动到$SQOOP_HOME/lib
6)查看帮助
[hadoop@hadoop001 bin]$ sqoop help

[hadoop@hadoop001 bin]$ sqoop version

[hadoop@hadoop001 bin]$ sqoop list-databases \
> --connect jdbc:mysql://localhost:3306 \
> --username root --password 123456
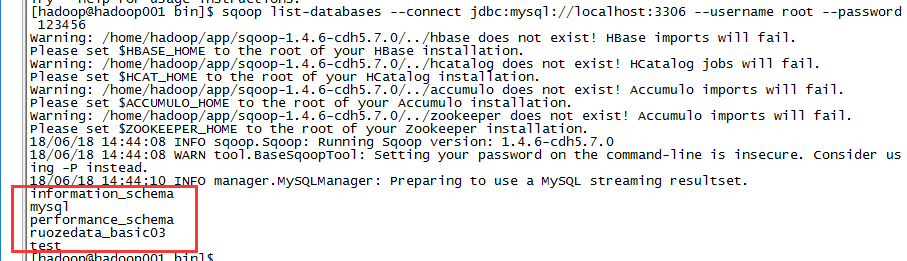
mysql中验证一下:

[hadoop@hadoop001 bin]$ sqoop list-tables \
> --connect jdbc:mysql://localhost:3306/ruozedata_basic03 \
> --username root --password 123456
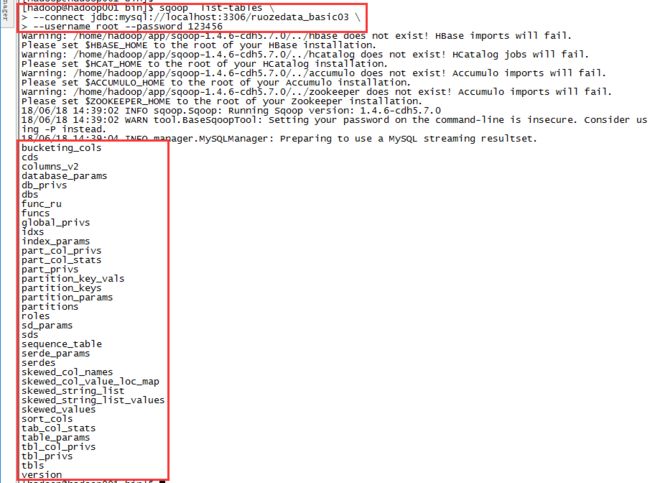
查看mysql

二、常用命令
1.RDBMS==>HDFS导入 import

1)--connect
Specify JDBC connect string 指定JDBC连接字符串
2)--username
Set authentication username 设置身份验证的用户名
3)--password
Set authentication password 设置身份验证密码
4)--append
Imports data in append mode 已追加的方式导入数据
5)--as-textfile
Imports data as plain text (default) 导入数据为纯文本(默认)
6)--columns
Columns to import from table 选择要从表导入的列
7)--delete-target-dir
Imports data in delete mode 先删除已有的数据,再导入
8)-e,--query
Import results of SQL 'statement' 导入SQL 'statement'的结果
9)-m,--num-mappers
Use 'n' map tasks to import in parallel 使用n个映射任务并行导入
10)--mapreduce-job-name
Set name for generated mapreduce job 为生成的mapreduce作业设置名称
11)--table
Table to read
12)--target-dir
HDFS plain table destination
13)--where
WHERE clause to use during import
14)--fields-terminated-by
Sets the field separator character 设置字段分隔符
15)--lines-terminated-by
Sets the end-of-line character 设置行尾字符
16)--input-fields-terminated-by
Sets the input field separator 设置输入字段分隔符
--input-lines-terminated-by
Sets the input end-of-line char 设置输入的行尾字符
17)--create-hive-table
Fail if the target hive table exists (一般不用)
18)--hive-import
Import tables into Hive (Uses Hive's default delimiters if none are set.) 将表导入到Hive中(如果没有设置,则使用Hive的默认分隔符)
19)--hive-overwrite
Overwrite existing data in the Hive table
20)--hive-partition-key
Sets the partition key to use when importing to hive
设置在导入hive时使用的分区键
21)--hive-partition-value
Sets the partition value to use when importing to hive
设置在导入到hive时要使用的分区值
实战如下:
1)在mysql中新建一个数据库hivetomysql,并新建一张表emp
create database hivetomysql;
create table emp (
empno int,
ename varchar(100),
job varchar(100),
mgr int,
hiredate varchar(100),
salary double,
comm double,
deptno int);

2)将hive中ruozedata数据库下的ruozedata_emp导出至mysql的表emp中
sqoop export \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp \
--export-dir \hdfs://192.168.137.141:9000/user/hive/warehouse/ruozedata.db/ruozedata_emp \
--input-fields-terminated-by '\t';
若没有--input-fields-terminated-by '\t'这句,MapReduce会运行失败,报错如下:
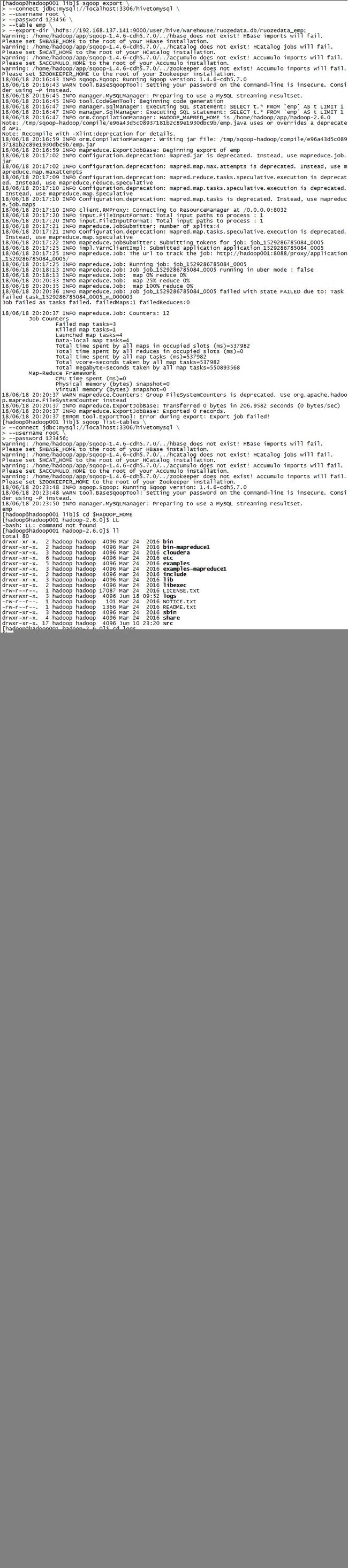
MapReduce运行日志保存在$HADOOP_HOME/logs/user logs下,MapReduce报错时可查看相应任务的日志来找到错误
加上--input-fields-terminated-by '\t'这句之后,运行成功
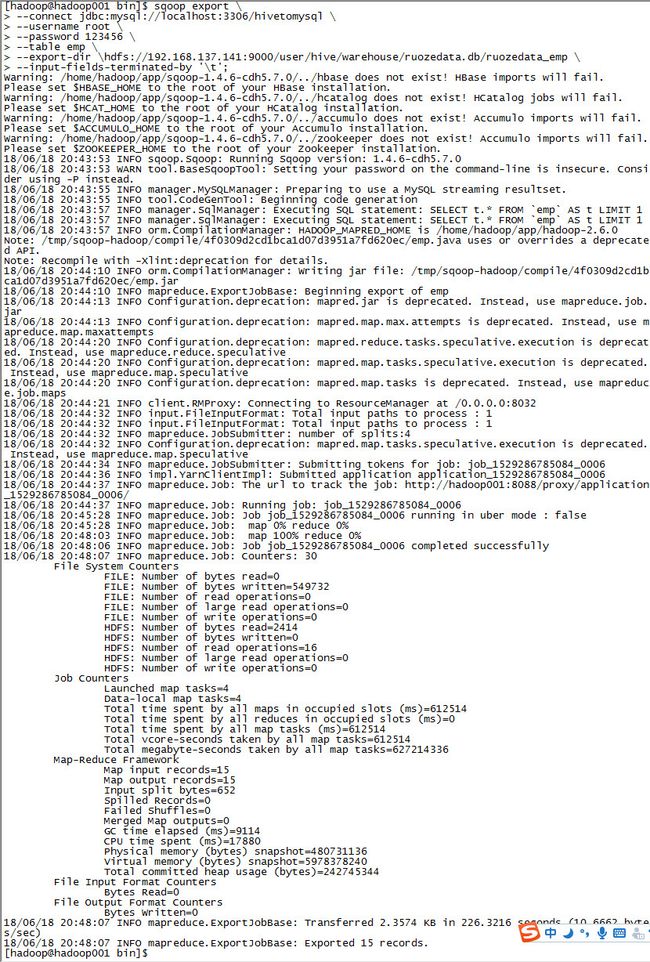

3)将emp表格导入到hadoop
a)
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp;
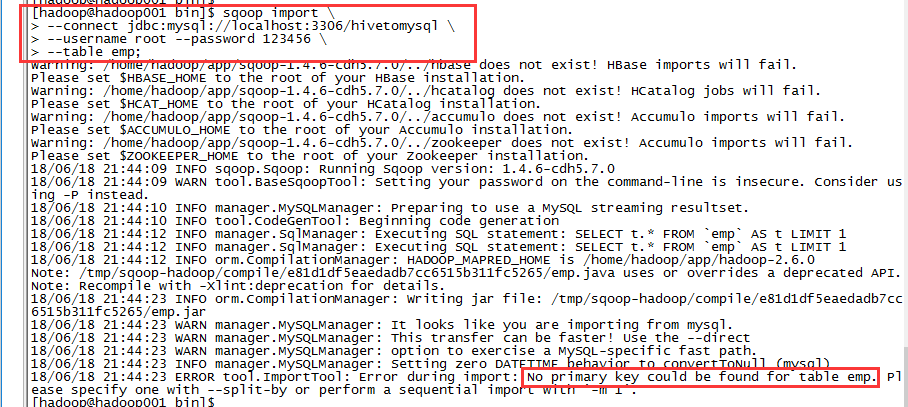
再次报错,提示表格emp没有主键,需要给emp表格增加主键
mysql> ALTER TABLE emp
-> ADD PRIMARY KEY (empno);
增加主键后再次执行命令,导入成功

默认的splits是4
[hadoop@hadoop001 ~]$ hadoop fs -ls emp
-rw-r--r-- 1 hadoop supergroup 0 2018-06-18 22:05 emp/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 297 2018-06-18 22:05 emp/part-m-00000
-rw-r--r-- 1 hadoop supergroup 386 2018-06-18 22:05 emp/part-m-00001
-rw-r--r-- 1 hadoop supergroup 0 2018-06-18 22:05 emp/part-m-00002
-rw-r--r-- 1 hadoop supergroup 51 2018-06-18 22:05 emp/part-m-00003

这15条数据是怎么分配的呢?

##补充:hadoop fs -ls 和hadoop fs -ls /user/hadoop进的是同一目录

b)
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp \
-m 2 \
--mapreduce-job-name FromMySQLToHDFS;
(将split改为2,并把MapReduce的job名称命名为 FromMySQLToHDFS)

报错:ERROR tool.ImportTool: Encountered IOException running import job: org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://192.168.137.141:9000/user/hadoop/emp already exists
emp已经存在
需要加一个语句
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp \
-m 2 \
--mapreduce-job-name FromMySQLToHDFS \
--delete-target-dir;

导入成功,并且可以看到number of splits变成了2

打开yarn查看任务

c)
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp \
-m 2 \
--mapreduce-job-name FromMySQLToHDFS \
--delete-target-dir \
--columns "empno,ename,job,salary,comm" \
--target-dir EMP_COLUMN;

d)
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp \
-m 2 \
--mapreduce-job-name FromMySQLToHDFS \
--delete-target-dir \
--columns "empno,ename,job,salary,comm" \
--target-dir EMP_COLUMN_SPLIT \
--fields-terminated-by '\t' \
--null-string '' --null-non-string '0';
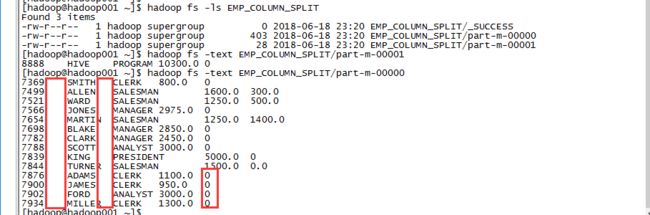
分隔符变为‘\t’(tab键),null变为空,非null字符串变为0
e)
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp \
-m 2 \
--mapreduce-job-name FromMySQLToHDFS \
--delete-target-dir \
--columns "empno,ename,job,salary,comm" \
--target-dir EMP_COLUMN_WHERE \
--fields-terminated-by '\t' \
--where 'salary>2000';
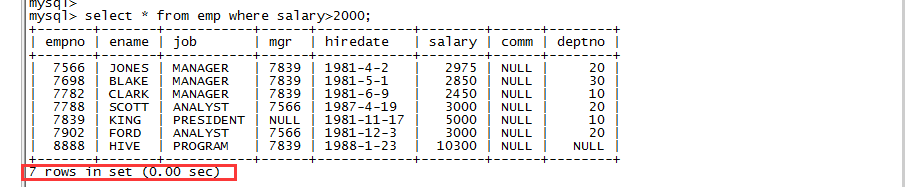

f)
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp \
-m 2 \
--mapreduce-job-name FromMySQLToHDFS \
--delete-target-dir \
--target-dir EMP_COLUMN_QUERY \
--fields-terminated-by '\t' \
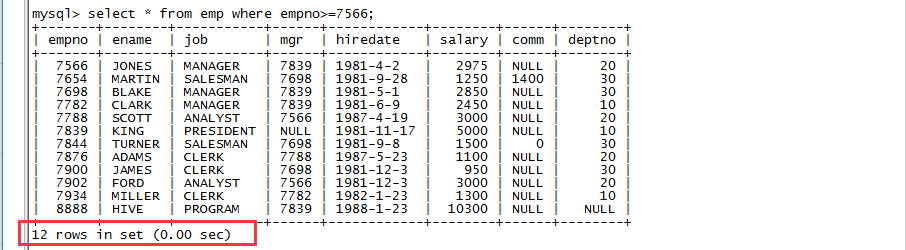
--query 'SELECT * FROM emp WHERE empno>=7566';

报错:Cannot specify --query and --table together.
--query和 --table不可以同时出现,因为query语法里有可能是多表查询
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
-m 2 \
--mapreduce-job-name FromMySQLToHDFS \
--delete-target-dir \
--target-dir EMP_COLUMN_QUERY \
--fields-terminated-by '\t' \
--query 'SELECT * FROM emp WHERE empno>=7566';
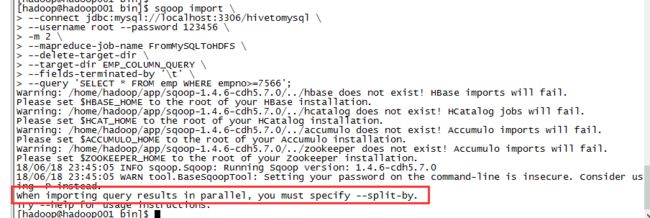
报错:When importing query results in parallel, you must specify --split-by.
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
-m 2 \
--mapreduce-job-name FromMySQLToHDFS \
--delete-target-dir \
--target-dir EMP_COLUMN_QUERY \
--fields-terminated-by '\t' \
--query 'SELECT * FROM emp WHERE empno>=7566' \
--split-by 'empno';

继续报错: must contain '$CONDITIONS' in WHERE clause.
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
-m 2 \
--mapreduce-job-name FromMySQLToHDFS \
--delete-target-dir \
--target-dir EMP_COLUMN_QUERY \
--fields-terminated-by '\t' \
--query 'SELECT * FROM emp WHERE empno>=7566 AND $CONDITIONS' \
--split-by 'empno';

终于成功了

g)命令封装
上边的例子命令太长了,可否封装到一个脚本里呢?
[hadoop@hadoop001 ~]$ cd shell
[hadoop@hadoop001 shell]$ vi emp.opt
import
--connect
jdbc:mysql://localhost:3306/hivetomysql
--username
root
--password
123456
--table
emp
--delete-target-dir
[hadoop@hadoop001 shell]$ sqoop --options-file emp.opt
2.export RDBMS<<==HDFS

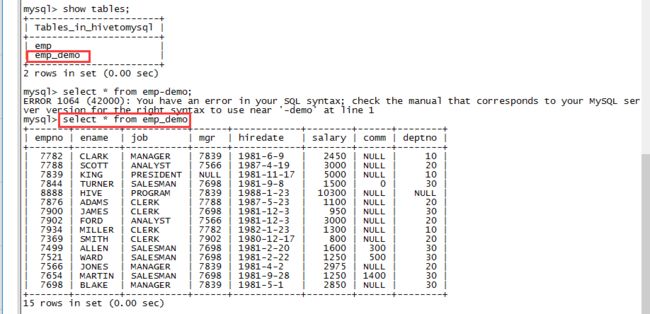
现在mysql中新建一张表emp_demo,且只需要表结构
mysql> create table emp_demo as select * from emp where 1=2;
[hadoop@hadoop001 bin]$ sqoop export \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--mapreduce-job-name FromHDFSToMySQL \
--table emp_demo \
--export-dir /user/hadoop/emp
3.RDBMS==>Hive
1)导入普通表
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp \
--mapreduce-job-name FromMySQLToHive \
--delete-target-dir \
--create-hive-table \ (直接自动创建一张表,不建议使用,问题见后续讲解)
--hive-database ruozedata \
--hive-table emp_sqoop \
--hive-import
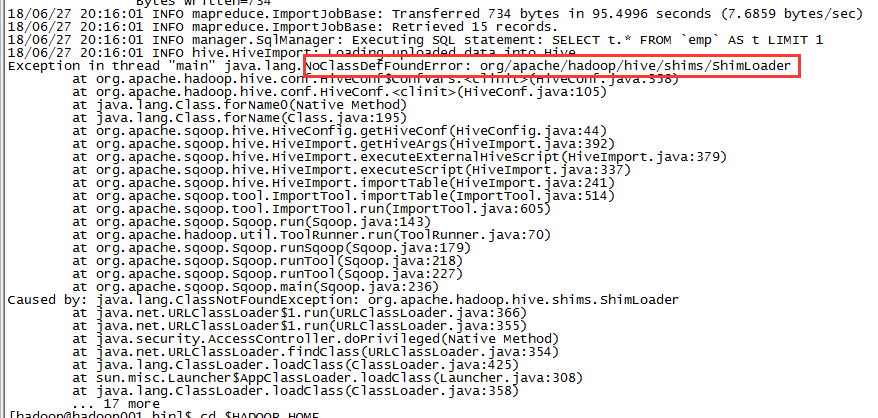
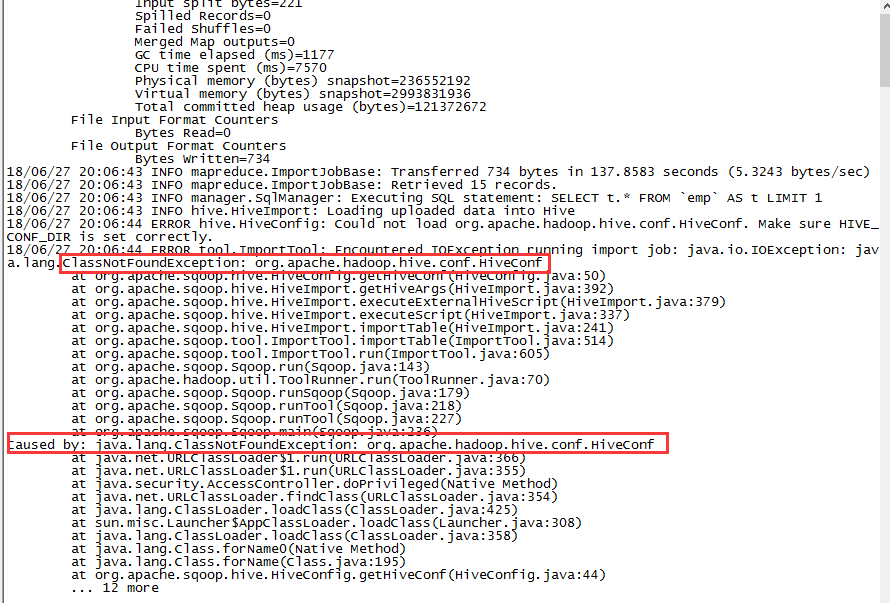
可能会遇到上面两种报错的情况,原因是缺少jar包
解决方法:
[hadoop@hadoop001 conf]$ vi sqoop-env.sh
export HADOOP_CLASSPATH=/home/hadoop/app/hive-1.1.0-cdh5.7.0/lib/*
再次运行,继续报错:

解决办法:将$HIVE_HOME/conf下的hive-site.xml拷贝至$SQOOP/HOME/conf
再次运行,成功
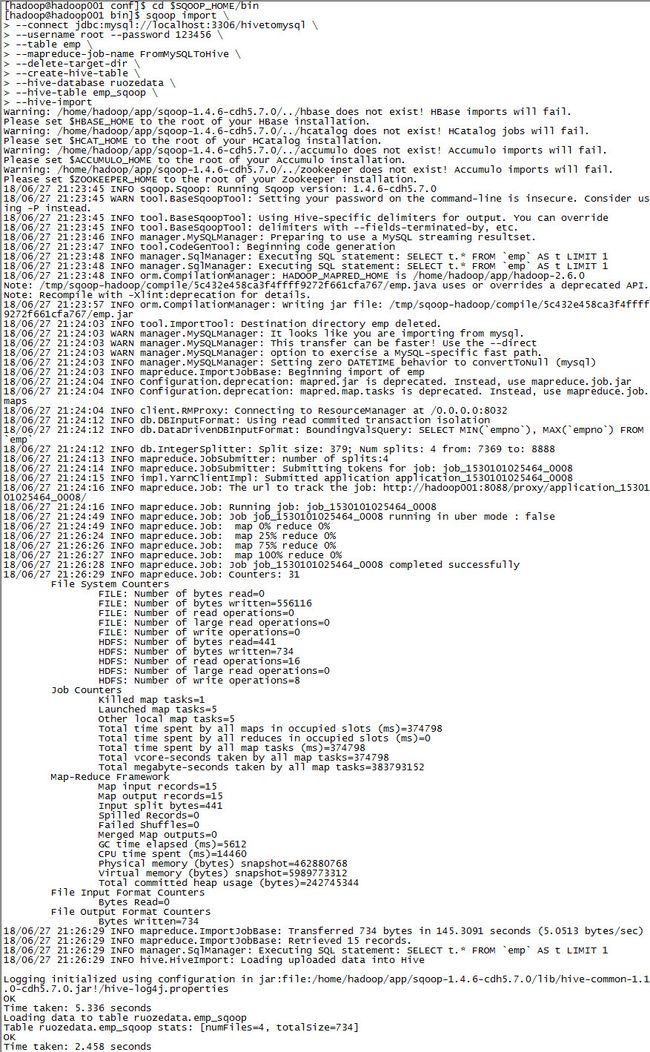

为什么说不建议使用--create-hive-table命令呢?

可以看到自动创建的表格是根据mysql中数据的字段类型来确定hive表中的字段类型的,本表中salary和comm都带小数点,所以,hive表中,salary和comm的字段类型为double。
假如最开始导入的salary和comm的数据中没有小数点,都是整数,如:
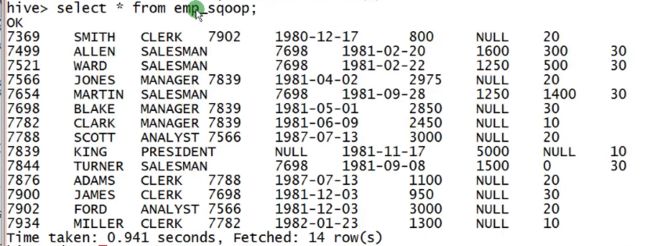
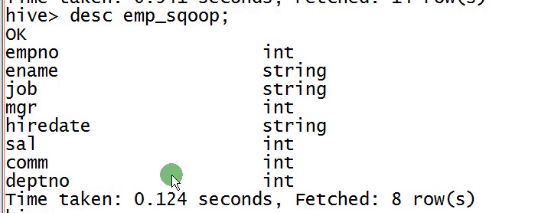
sal和comm便被默认为int类型,往后再插入带小数点的数据就会出现问题,因此最好事先创建一个hive表,再进行sqoop导入数据到hive表
2)导入分区表
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp \
--mapreduce-job-name FromMySQLToHive \
--delete-target-dir \
--hive-database ruozedata \
--hive-table ruozedata_emp_partition \
--hive-import \
--hive-partition-key 'pt' \
--hive-partition-value '2018-08-08'

但是,查看表内容发现有问题:

应该是分隔符的问题
sqoop import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp \
--mapreduce-job-name FromMySQLToHive \
--delete-target-dir \
--hive-database ruozedata \
--hive-table ruozedata_emp_partition \
--hive-import \
--hive-partition-key 'pt' \
--hive-partition-value '2018-08-08' \
--fields-terminated-by '\t' \ (规定分隔符为\t)
--hive-overwrite (覆盖之前数据)

3.hive导出到mysql
现在mysql里创建一张表
mysql> create table emp_export as select * from emp where 1=2;
sqoop export \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp_export \
--export-dir \hdfs://192.168.137.141:9000/user/hive/warehouse/ruozedata.db/ruozedata_emp \
--input-fields-terminated-by '\t';


4.job
先创建一个job
sqoop job --create ruozejob \
-- import \
--connect jdbc:mysql://localhost:3306/hivetomysql \
--username root --password 123456 \
--table emp -m 2 \
--mapreduce-job-name FromHiveToMySQL \
--delete-target-dir;
[hadoop@hadoop001 conf]$ sqoop job --list

[hadoop@hadoop001 conf]$ sqoop job --exec ruozejob
